






카이스트 연구진이 발표한 논문에 따르면, 연합학습(Federated Learning) 기반의 군사용 대규모 언어모델(LLM)이 새로운 보안 위험에 직면해 있다. (☞ 논문 바로가기)
의료·금융 분야에서 검증된 연합학습, 이제는 군사 분야로 확대
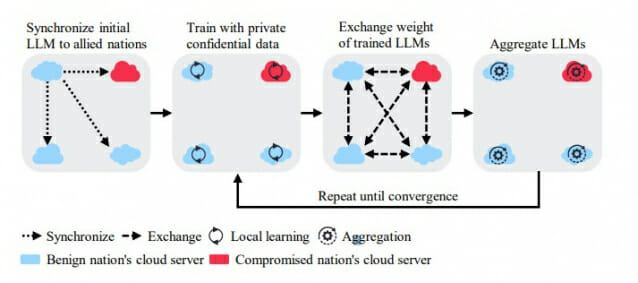
최근 인텔 가우디(Intel Gaudi)와 같은 전문 AI 하드웨어의 발전으로 국방 분야의 AI 활용이 가속화되고 있다. 미국 국방부는 이미 학계, 산업계, 동맹국들과 협력하여 데이터 관리와 책임있는 AI 개발을 위한 연합학습 도입을 적극 추진하고 있다. 연합학습은 실시간으로 변화하는 위협과 전장 상황에 AI 모델을 신속하게 적응시킬 수 있으며, 원시 데이터 대신 모델 업데이트만을 교환하여 통신 효율성도 높일 수 있다.
군사 LLM 4대 보안 위협: 기밀유출부터 허위정보까지
연구진이 밝혀낸 네 가지 주요 취약점은 각각 독특한 공격 방식을 가지고 있다. 기밀 데이터 유출 공격의 경우, 공격자는 전문가 검증을 통해 추출된 정보의 정확성을 확인하고 불필요한 데이터를 걸러내어 효과적으로 기밀을 수집한다. 무임승차 공격은 연합 모델의 전반적인 품질을 저하시키고 동맹국 간 신뢰를 약화시킨다. 시스템 교란 공격자는 집계된 모델과 개별 튜닝된 버전을 비교하며 가장 효과적인 오류 주입 방법을 찾아낸다. 허위정보 유포의 경우, 공격자는 지역 데이터셋과 결합된 모델 가중치를 모두 수정하여 이중 경로로 허위정보를 전파한다.
인간-AI 협력 방어체계: 실시간 워게임 시뮬레이션과 자동 교정
방어 체계의 핵심은 레드팀-블루팀 워게이밍이다. 레드팀 LLM이 인식된 취약점을 공격하면, 블루팀 LLM이 실시간으로 적응형 대응책을 개발한다. 이 과정에서 군사 도메인 전문가들이 전술과 결과를 검증하여 방어 대책이 실제 시나리오에 부합하는지 확인한다. 충분한 방어 능력이 확인되면 품질보증 단계로 넘어가는데, 여기서 QA LLM이 배포된 모델의 이상이나 공격 시도를 지속적으로 감시한다.
다층적 정책 검증: AI와 전문가의 단계별 승인 체계
정책 프레임워크는 세 단계의 검증을 거친다. 먼저 정책 전문가들이 각 제안을 기존 방위 기준과 임무별 요구사항에 비추어 평가한다. 이어서 AI 기반 위험 모델이 새로 도입된 수정안이 보안을 약화시키거나 운영상 병목을 만들지 않는지 재분석한다. 마지막으로 도메인 전문가들이 전략적, 전술적 타당성을 검증하여 진행 중인 임무나 정당한 정보 교환을 저해하지 않는지 확인한다.
암호 기술과 국제 표준화: 차세대 보안 강화 방안
관련기사
- 의료 AI 진단 정확도 9.64% 높인 새 학습법…비결은?2025.02.03
- "딥시크 개발비 82억은 과장…총 비용은 50배 이상"2025.02.03
- AI가 학생 글쓰기 첨삭했더니...6명 중 5명 실력 향상2025.02.03
- 오픈AI 'o3-미니' 뭐가 좋길래…초보자도 이해하기 쉽게 설명합니다2025.02.01
연구진은 미래 보안 강화를 위한 구체적 방안도 제시했다. 제로지식 증명으로 데이터 주권을 보호하고, 차분 프라이버시로 개인정보를 보호하며, 준동형 암호화로 암호화된 상태에서 데이터 처리가 가능하도록 한다. 또한 블록체인 기반 감사로 추적성을 확보하고, 고도화된 이상 탐지 알고리즘으로 시스템 무결성을 강화할 것을 제안했다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)





