의사처럼 단계적으로 배워야…기존 의료 AI의 한계 지적
워싱턴대학교와 노스캐롤라이나대학교 연구진의 논문에 따르면, 현재의 의료 AI 시스템들은 실제 임상 현장에서의 추론 과정을 제대로 반영하지 못하고 있다. 이는 대부분의 의료 AI가 정적인 텍스트와 단순 질의응답 작업으로만 훈련되고 평가되기 때문이다. 실제 임상 현장에서는 환자 병력 검토부터 임상 소견 분석, 검사 결과 해석을 거쳐 종합적인 진단 결론에 이르는 체계적인 진단 조사가 필수적이다. 의사는 현재 증상에 대한 추가 질문이나 검사 필요성을 판단하는 반복적인 과정을 거치는데, 현재의 단순 선택형 문제 형식으로는 이러한 실제 진료 과정의 복잡성을 담아내지 못하고 있다는 것이 핵심적인 문제로 지적됐다. (☞ 논문 바로가기)
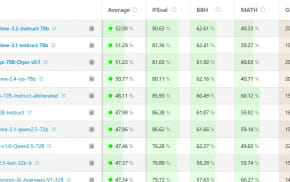
대화형 학습으로 LLaMA 3.2 모델 정확도 21.4% 향상
연구팀이 개발한 새로운 벤치마크 '머디 메이즈(Muddy Maze)'는 실제 의료 현장의 진단 과정을 정교하게 모사했다. 이 방식으로 학습된 LLaMA 3.2 모델은 일회성 평가에서 단일 정확도가 21.4%, 다중 정확도는 8.25% 향상됐다. 특히 Qwen 2.5 모델은 기본 난이도 태스크에서 다중 라운드 추론 시 9.64%의 단일 정확도 향상과 4.37%의 다중 정확도 향상을 보여줬다.
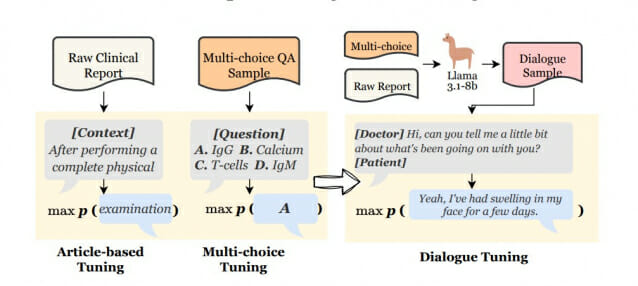
진단은 단계적 과정…3단계 난이도의 실전형 평가 시스템
전체 벤치마크의 45%를 차지하는 도전 과제와 35.4%를 차지하는 고급 과제, 19.6%를 차지하는 기본 과제로 구성된 3단계 난이도 시스템을 도입했다. 기본 단계는 MedQA Step 1 문제를 바탕으로 하며, 고급 단계는 MedQA Step 2와 3, MedBullets 문제들을 포함한다. 가장 높은 단계인 도전 과제는 JAMA Challenge의 실제 임상 사례들을 활용해 현실 의료 환경의 복잡성을 반영했다.
엔트로피 감소 이론으로 입증한 대화형 학습의 우수성
연구진은 대화형 학습의 효과를 엔트로피 감소 관점에서 분석했다. 의사가 환자와의 대화를 통해 점진적으로 불확실성을 줄여나가는 것처럼, AI도 대화를 통해 진단의 불확실성(엔트로피)을 단계적으로 감소시킨다는 것을 수학적으로 입증했다. 이는 조건부 상호 정보량 I(D; enew¦Et)가 항상 비음수라는 사실을 통해 확인됐다.
잡음 환경에서도 강건한 성능 유지하는 대화형 모델
실제 의료 환경의 다양한 노이즈 상황에서도 대화형 학습 모델은 우수한 성능을 보였다. LLaMA 3.2-3B 모델은 노이즈 레벨 0과 1에서 각각 2.82%와 6.18%의 성능 향상을 보였으며, Qwen 2.5 모델은 노이즈 레벨 1에서 2.53%, 레벨 5에서도 2.28%의 향상된 성능을 유지했다.
의료 AI의 실용화를 위한 과제와 전망
관련기사
- 오픈AI 'o3-미니' 뭐가 좋길래…초보자도 이해하기 쉽게 설명합니다2025.02.01
- AI가 학생 글쓰기 첨삭했더니...6명 중 5명 실력 향상2025.02.03
- AI가 혈당 관리도 할 수 있을까… 챗GPT로 실험했더니2025.02.01
- 美 나스닥 데뷔하는 SK하이닉스…다음 투자 행보는2026.07.10
연구진은 이번 연구의 한계점으로 대화 생성 과정에서 발생할 수 있는 AI의 환각 현상과 의사소통 스타일의 다양성 반영 문제를 지적했다. 향후 더 광범위한 의료 분야로의 확장과 함께 이러한 한계점들을 보완하는 연구를 진행할 예정이다. 특히 환자 개인정보 보호와 의료 데이터 보안 규정 준수에 대한 엄격한 기준도 마련할 계획이다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)