






인공지능(AI)이 답을 내는 데 시간이 걸리는 진짜 이유가 ‘메모리 부족’이라 보고, SK하이닉스가 메모리 중심 가속기를 연구 중이다. 그래픽처리장치(GPU)보다 메모리를 훨씬 많이 탑재해 대형 언어모델(LLM) 추론 속도를 끌어올리겠다는 계획이다.
주영표 SK하이닉스 연구위원은 24일 서울 강남구 코엑스에서 진행된 제8회 반도체 산·학·연 교류 워크숍에서 ‘AI 시대를 위한 미래 메모리 솔루션 형성’이라는 제목으로 이같은 내용을 발표했다.

그는 “GPU와 다른 연산·메모리 비율을 갖는 추론형 가속기 구조를 고민하고 있다”며 “연산기보다는 메모리를 훨씬 더 많이 탑재해, 데이터 접근 대역폭을 극대화하는 방향으로 연구가 진행 중”이라고 밝혔다.
“GPU보다 메모리를 더 많이 탑재한 추론형 가속기”
주 연구위원이 밝힌 추론형 가속기 구조는 메모리 특화 가속기다. 이 칩은 기존 GPU 대비 메모리 비중을 대폭 높인 추론형 칩이다. 패키지당 메모리 용량을 확대하, 메모리-연산기 간 접점 면적(쇼어라인)을 넓혀 연산기에 더 많은 대역폭을 공급하는 것이 목표다.
즉, 칩당 메모리 용량을 대폭 키우는 동시에, GPU가 메모리 병목 없이 데이터를 빠르게 공급받을 수 있게 하는 것이 핵심이다.
그는 “기존에는 중앙에 GPU, 주변에 HBM(고대역폭메모리)을 배치했지만, 앞으로는 HBM보다 더 많은 메모리를 탑재하고 인터페이스 쇼어라인을 확대해 대역폭을 극대화하는 구조를 지향한다”고 설명했다.
LLM 추론 병목의 본질은 ‘연산’ 아닌 ‘메모리’
메모리 특화 가속기가 필요한 이유로는 병목 현상을 지목했다. AI 추론 과정에서 메모리 병목이 GPU 효율을 크게 떨어뜨린다는 이유에서다.
주 연구위원은 “LLM 디코드 단계는 GPU 연산 자원을 20~30%밖에 활용하지 못한다”며 “대부분의 시간이 데이터를 읽고 쓰는 과정에 소모돼, GPU 성능이 아니라 메모리 대역폭이 병목으로 작용하고 있다”고 지적했다.
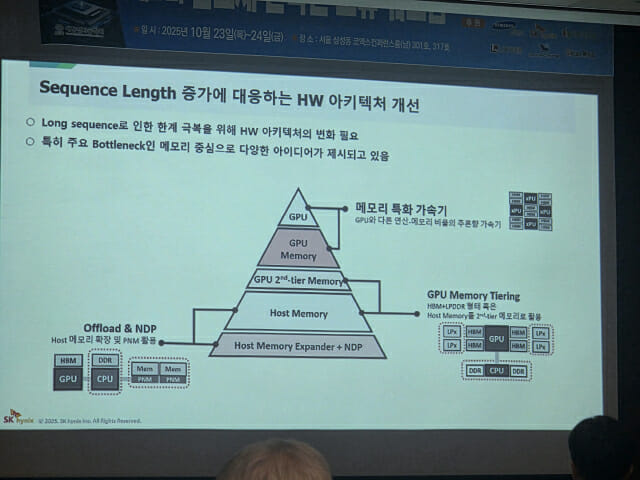
이러한 문제를 해결하기 위해 SK하이닉스는 HBM 외에 LPDDR(저전력 D램), 호스트 메모리 등과의 계층적 결합도 연구 중이다. 계층적 결합은 여러 종류 메모리를 계층으로 묶어, 데이터를 효율적으로 배치하고 이동시키는 방식이다. 필요한 데이터를 상황에 맞게 옮겨쓸 수 있다. 이를 통해 GPU가 LPDDR에 직접 접근하거나, CPU(인텔·ARM 기반) 메모리를 공유하는 방식으로 확장성을 확보한다는 구상이다.
관련기사
- SK하이닉스, HBM4용 테스트 장비 공급망 '윤곽'…연내 발주 시작2025.10.24
- 곽노정 SK하이닉스 사장 "HBM4, 고객 요구 모두 만족 시켜...내년 업황 나쁘지 않아"2025.10.22
- SK하이닉스, HBM4 개발 완료…'세계 최초' 양산 체제 구축2025.09.12
- SK하이닉스, '1c D램' LPDDR5X 개발 성공…SoCAMM 등 AI 메모리 겨냥2025.08.14
그는 “AI 추론 환경의 병목은 이제 연산이 아니라 메모리 접근에 있다”며 “밴드위스(대역폭)를 극대화하기 위해 메모리-SoC 간 쇼어라인을 늘리고, 나아가 3D 적층 구조로 확장하는 방향이 유력하다”고 말했다.
이어 “업계 전반이 연산을 메모리 가까이 두는 구조로 전환 중"이라며 "하이닉스 역시 CXL·HBM·하이브리드 메모리 등 다양한 솔루션을 병행 연구하고 있다"고 덧붙였다.





