






스탠퍼드대 인간중심 인공지능연구소(HAI)가 올해 발표한 '인공지능(AI) 인덱스 리포트 2024'에 한국 AI 모델을 포함하지 않은 이유를 밝혔다. 연구진이 파운데이션 모델을 '생태계 그래프(Ecosystems Graph)'에서, 주목할 만한 모델을 '에포크(Epoch)'에서만 참고한 탓이다.
22일 HAI 네스터 마슬레이 AI인덱스연구책임은 보고서에 네이버의 '하이퍼클로바X' 등 한국 AI 모델이 비교 대상에서 생략된 이유를 이같이 본지에 전했다.
네스터 마슬레이 연구책임은 매년 전 세계 AI 동향을 조사하는 AI 인덱스 보고서 제작을 담당한다. 지난해 글로벌 AI 동향을 정리한 보고서를 이달 15일 공개했다.
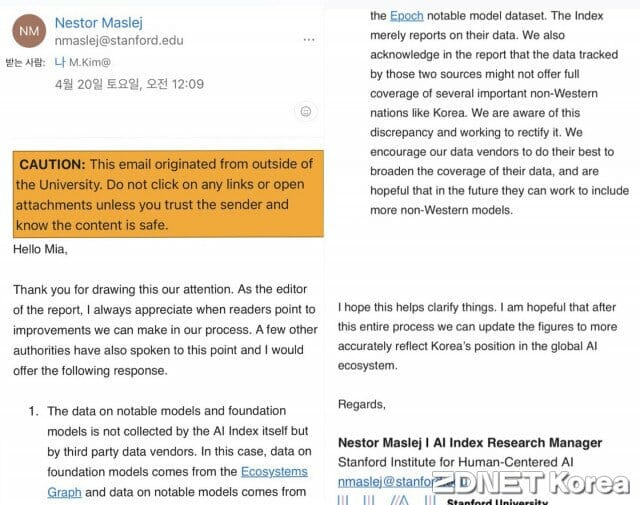
마슬레이 책임은 이번 모델 비교에 좁은 데이터 범위를 활용했다고 인정했다. 전 세계 AI 모델을 비교한 것이 아니라 제3자가 만든 특정 소스로만 비교 대상을 잡았다는 의미다. 그는 보고서에 모든 AI 모델을 조사에 포함시키는 건 무리라고 언급한 바 있다.
그는 "파운데이션 모델 데이터는 생태계 그래프에서, 주목할 만한 모델에 대한 데이터는 에포크의 주목할 만한 모델 부문에서 가져왔다"고 설명했다. 두 사이트는 전 세계 AI 모델을 모아둔 사이트다. 오픈소스 모델과 폐쇄형 모두 등록돼 있다. 두 데이터셋에 없는 모델은 이번 HAI 조사 대상에서 제외됐다.
HAI는 해당 범위 내에서만 파운데이션 모델 출시 현황을 조사하고, 주목만 한만 모델을 선정한 셈이다. 네이버의 하이퍼클로바X 같은 한국 모델이 낮은 성능을 갖춰서 비교 대상에서 빠진 것이 아니라, 애초 HAI가 활용한 데이터 소스 범위 자체가 좁았다.
마슬레이 책임은 "두 출처에서 가져온 데이터가 한국 같은 비영어권 국가 모델을 포함하지 않았을 수 있다"며 "전 세계 주요 모델을 완전히 포괄하지 못했음을 인정한다"고 했다. 그는 "현재 이를 바로잡기 위해 노력 중"이라며 "데이터 활용 범위를 넓혀서 보고서에 더 많은 비영어권 모델을 포함하겠다"고 했다.

스탠퍼드대는 AI 인덱스 2024 보고서에서 지역별 파운데이션 모델 수를 공개하면서 미국이 109개로 가장 많고, 중국과 영국, 아랍에미리트(UAE)가 각각 20개와 8개, 4개로 집계됐다고 전했다. 이외에 약 10개국이 파운데이션 모델을 갖고 있는 것으로 표기됐지만 보고서에 한국은 없었다. 지역별 주목할 만한 모델 수에도 미국이 61개로 가장 많았고, 중국(15개)과 프랑스(8개), 이스라엘(4개) 등의 순으로 나왔지만 한국은 거론되지 않았다.
관련기사
- 메타, 오픈소스 모델 '라마3' 출시…페북-인스타 등에 적용2024.04.19
- "AI가 준 피해, 어디까지 감수할 수 있나"…정부, AI 서울 정상회의서 논의2024.04.14
- 네이버클라우드, 원티드랩 손잡고 기업 생성형 AI 도입 확대 박차2024.04.15
- 네이버, 플러스멤버십 3개월 무료 가입·도착보장 무료 배송 제공2024.04.15
이에 국내 AI 모델이 '패싱'당했다는 지적이 이어졌다. 심지어 몇몇 언론에서도 보고서 데이터 출처와 조사 범위를 확인하지 않고 이를 그대로 보도하는 사태까지 벌어졌다.
익명을 요구한 AI 기업 관계자는 "한국 기업이 전혀 거론되지 않은 것 자체부터 이상했다"며 "논문에 활용된 데이터 조사 범위를 신중히 볼 필요가 있다"고 했다.





