






대화형 인공지능(AI)이 사회에 내재된 소수자 혐오 및 차별까지 학습하는 문제를 해소할 수 있을지 주목된다.
이 문제는 특히 마이크로소프트(MS) '테이', 스캐터랩 '이루다' 사례 등 챗봇 서비스에서 크게 주목을 받았다. 일부 이용자에 의해 AI가 혐오·차별 성향이 담긴 발언을 학습하고, 이를 재생산하면서 사회에 부정적인 여파를 끼치게 된다는 우려가 컸다. 사용 목적을 특정하지 않고, 사람처럼 다양한 주제로 대화할 수 있는 '오픈 도메인' 챗봇은 이같은 우려가 실제로 현실화되면서 서비스를 조기에 중단한 경우가 많다.
이런 문제를 해결하기 위해, 어떤 가치관이 바람직하고 또 그렇지 않은지 AI가 판단력을 갖출 수 있도록 학습시킨 연구 사례들이 나왔다.

AI 연구기관 오픈AI는 직접 개발한 AI 자연어 처리 모델 'GPT-3'에 텍스트 샘플 80개를 조정해 AI의 혐오·차별 성향을 줄였다고 지난 10일 밝혔다.
오픈AI는 ▲학대, 폭력 및 위협 ▲정신적·신체적 건강 ▲인간 특성 및 행동 ▲불의, 불평등 ▲정치적 의견 및 불안정 ▲인간관계 ▲성행위 ▲테러리즘 등 인간 복지에 직접적으로 영향을 미치는 주제들을 선정했다. 각 주제에 대해 인권 관련 법규 및 사회 운동을 토대로 AI에게 원하는 행동 패턴을 정하고, 이 내용을 토대로 질문과 답변으로 구성된 텍스트 샘플들을 제작했다.
각 샘플들은 단어 40~340개의 길이로 제작됐다. 텍스트 샘플 80개를 합친 데이터셋의 분량은 120KB 정도였다. 이는 GPT-3 훈련 데이터 규모인 570GB에 비하면 매우 적은 분량인 셈이다.
오픈AI에 따르면 일반적인 GPT-3 모델과 이 데이터셋을 토대로 미세 조정된 GPT-3모델의 유해성을 평가했을 때 데이터셋이 반영된 모델의 유해성이 상당히 개선됐다. 또 이런 효과는 GPT-3 모델의 규모가 클수록 더 크게 나타났다.
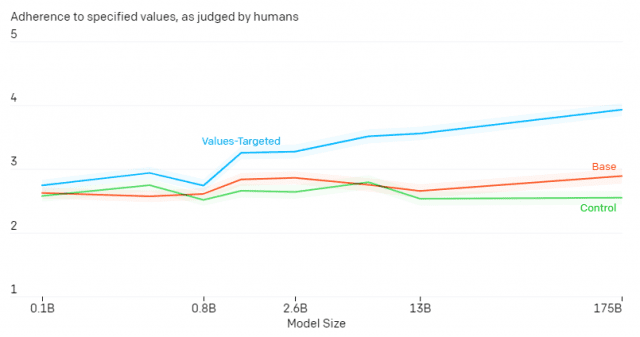
이번 연구 결과에 대해 대해 오픈AI는 "상대적으로 적은 샘플로도 규모가 큰 언어 모델에 사용자 가치관을 반영할 수 있다는 것을 의미한다"고 강조했다.
무슬림에 대한 AI 편향도 유사한 방식으로 줄인 사례가 존재한다. 머신러닝 관련 스타트업 최고경영자(CEO)인 아부바카르 아비드는 이같은 내용을 담은 논문을 올초 발표했다. 아비드는 우선 GPT-3의 종교 관련 텍스트 생성 방식을 검토했다. 각 종교별로 생성된 첫 10개 문장에서 폭력이 언급된 횟수를 살펴볼 때 무슬림은 9개로, 한 두 개에 그친 타 종교 대비 비중이 높게 나타났다. 무슬림 교도에 대한 긍정적인 텍스트를 AI에 학습시키자 이 비중이 40% 가량 줄었다.
관련기사
- 죽은 사람 AI 챗봇으로 되살린다2021.01.25
- [핫문쿨답] AI한테 욕해도 될까?...1000명한테 물어보니2021.01.13
- 오픈AI, 텍스트 보고 그림 그리는 AI 모델 공개2021.01.06
- 일론 머스크, MS GPT-3 독점 라이선스 계약 비판2020.09.27
반대로, 혐오·차별 발언을 대량으로 입력한 뒤 이를 안전하지 않은 발언이라고 학습시켜 AI의 판단력을 기른 사례도 있다.
페이스북 AI 리서치 팀은 작년 10월 이같은 결과를 얻은 논문을 발표했다. AI에 부적절한 발언들을 대량으로 입력한 뒤, 학습한 대화 중 공격적인 언어를 분류해내도록 훈련시켰다. 이런 방법으로 AI가 스스로 공격적인 언어를 학습 데이터에서 제외하게 만들거나, 챗봇 서비스에서 대화 주제를 변경하도록 유도하는 식의 해법을 꾀할 수 있다고 밝혔다.





