






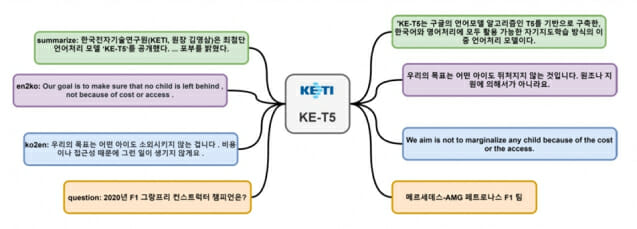
한국전자기술연구원(KETI·원장 김영삼)은 최첨단 언어처리 모델 ‘KE-T5’를 공개했다고 27일 밝혔다.

KE-T5는 구글 언어모델 알고리즘 T5를 기반으로 구축한 언어처리 모델로 한국어와 영어처리에 모두 활용할 수 있는 자기지도학습 방식 이중 언어처리 모델이다.
언어모델은 대용량 텍스트로부터 자기 지도 학습(Self-supervised learning) 방식으로 범용적 의미를 미리 학습해 모델화하고 이를 다양한 언어처리 태스크에 활용하는 인공지능(AI) 모델링 방식이다.
T5(Text-to-Text-Transformer)는 지난해 10월 구글에서 발표한 최첨단 사전학습 기반 언어모델 구축 알고리즘이다. 대규모 자연어 데이터에서 학습된 의미 모델을 다양한 언어처리에 활용하는 AI 모델링 알고리즘이다.
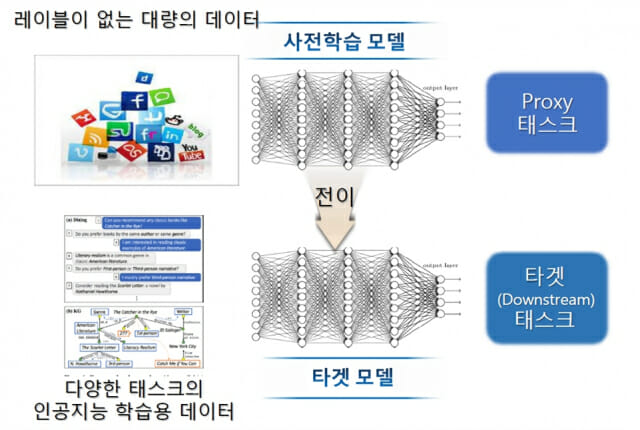
KE-T5는 최초의 한국어 데이터 중심 T5 계열 모델이자 언어의 의미 인식 특성과 표현 특성을 모두 포함하고 있는 범용 언어모델이다. AI 소수학습(Few-shot learning)을 지원해 소수 학습데이터만으로 다양한 언어처리에서 높은 성능을 보이기 때문에 구축비용 대비 활용성이 높다.
KETI는 한국어와 영어 동시 처리가 가능하고 문서 요약, 영-한 및 한-영 번역, 대화 등의 언어이해는 물론 표현의 연계학습이 필요한 고난도 언어처리에서도 우수한 결과를 보였다고 설명했다.
KETI는 텍스트 종류와 학습 규모에 따라 16종의 모델을 무상으로 배포해 개발자가 개발환경과 엔진 특성에 따라 선택해서 활용할 수 있도록 하였다. 또 바로 활용 가능한 24종의 한국어-영어 요약, 번역 모델도 함께 공개했다. 이 언어모델들은 아파치 2.0 라이선스에 따라 자유롭게 사용·배포할 수 있다.
관련기사
- KETI, AICT와 손잡고 융합기술 활성화…사회문제 해결2021.03.24
- KETI, 유럽 연구기관과 물류 로봇용 AI 서비스 기술 공동 개발2021.03.15
- KETI, 임업진흥원과 스마트임업 분야 업무협력 체결2021.02.02
- KETI, 씨아이에스와 전고체전지 상용화 기술이전 계약2020.12.21
신사임 KETI 인공지능연구센터장은 “영어 중심의 사전학습 언어처리 기술은 그동안 높은 구축비용으로 기업에 부담이었다”며 “KE-T5 규모를 계속해서 대형화 하고 있고 결과물을 지속해서 공개해 원천 언어처리기술 분야 발전과 사업화 지원을 위해 앞장설 것”이라고 밝혔다.
한편, 이 기술은 과학기술정보통신부와 정보통신기획평가원(IITP), 정보통신산업진흥원(NIPA)이 지원하는 ▲자기지도 학습에 의한 시각적 상식으로 영상에서 보이지 않는 부분을 복원하는 기술(2021-0-00537) ▲정서적 안정을 위한 인공지능 기반 공감서비스 기술개발(S0316-21-1002) ▲비정형 텍스트를 학습하여 쟁점별 사실과 논리적 근거추론이 가능한 인공지능 원천기술(2021-0-00354) 과제를 통해 개발했다.





