






"전산업계 공통적으로 인공지능(AI) 활용이 증가하고 있지만, 그 용도에 따라 인프라 구성은 달라야 한다. 머신러닝이나 딥러닝 관련 워크로드는 크게 '훈련(training)'과 '추론(inference)' 두갈래로 나뉘는데, 각각 인프라의 구조가 달라진다."
양원석 한국델테크놀로지스 데이터센터&컴퓨트사업부 전무는 최근 본지와 인터뷰에서 AI 관련 IT인프라를 설명하며 이같이 밝혔다.

양원석 전무는 "훈련 영역은 특정 업무에 맞게끔 머신을 학습시키는 게 중심이고, 추론 영역은 학습을 마친 AI를 서비스에 투입하는 게 중심"이라며 "기업은 기술을 사업에 활용할 때 훈련과 추론에 인프라를 달리 고려하고 선택해야 한다"고 강조했다.
양 전무는 "전통적인 스케일업, 혹은 스케일아웃 중 어느 게 맞는가, 어떤 프레임워크가 적합할지 따지는 게 필요하다"며 "또 활용하려는 앱이나 워크로드가 이미지처리인지, 자연어인지, 시계열 분석인지, 추천인지 등에 따라서 적합한 알고리즘을 고르고 적절한 인프라를 선택해야 한다"고 덧붙였다.
현대의 AI는 인공신경망을 이용하는 알고리즘에 많은 데이터를 학습시켜, 이미지 속 정보를 추출하거나 사람의 언어로 소통할 수 있는 능력을 갖추는 게 일반적인 유형이다.
기업은 1차로 알고리즘을 학습시키는 과정과, 일정 수준 이상 훈련된 알고리즘을 실제 서비스에 적용하는 과정을 거쳐 AI를 활용하게 된다.
델테크놀로지스는 이같은 과정에서 각 영역에 맞는 시스템 인프라를 구성해야 한다고 본다. 학습에 적합한 인프라와 추론 혹은 실제 서비스에 적합한 인프라가 달라져야 한다는 것이다.
양 전무는 "훈련이란 방대한 데이터를 저장하고, 그 데이터를 반복적으로 특정 알고리즘에 학습시키는 것"이라며 "수십 수백테라바이트의 저장 공간이 필요하기도 하고. 원하는 시간 안에 학습시킬 수 있는 방대한 컴퓨팅 파워로 GPU 같은 가속 기술이 대량으로 필요하다"고 설명했다.
그는 "추론은 학습을 끝낸 후 특정 서비스를 구동하는 인프라 환경을 필요로 하는데, 이 경우 하나의 컴퓨트 노드에 적게는 한개, 또는 두개의 GPU나 아니면 CPU 만으로도 추론 서비스를 할 수 있다"며 "단일 컴퓨트 노드 안에 가속 기술이 많지 않아도 되고 서비스 받는 대상이 많다면 기존 웹서비스처럼 스케일아웃 형태로 펼쳐 나가면 되는 구조"라고 밝혔다.
학습용 인프라는 많은 데이터로 수많은 연산을 수행해야 하므로 GPU가 대량으로 필요한 반면, 추론용 인프라는 적은 GPU나 CPU만 가진 일반 시스템이면 된다는 것이다.
그는 나아가 훈련용 환경을 구축할 때 단일 컴퓨트 안에 GPU 수를 늘려야 할지, GPU를 여러 노드에 분산시켜 처리해야 할지 등은 학습 대상이나 알고리즘, 프레임워크에 따라 달라진다고 설명했다.
그는 "과거엔 개발자가 분산처리를 위해 데이터를 쪼개 여러 서버로 나누거나, 개발단계에서 코드를 수정하는 등 해야 할 일이 많았다"며 "현재의 AI 기술은 프레임워크가 함께 발전하고 있어서 개발자가 신경쓰지 않아도 알아서 분산처리를 해주는 등 인프라 구성에 편리한 점이 많아지고 있다"고 말했다.
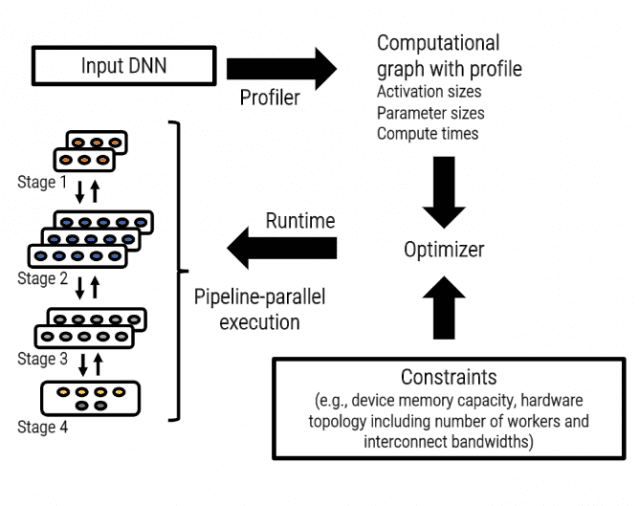
그는 "대표적으로 구글의 G파이프나 MS의 파이프드림 같은 프레임워크는 분산처리 학습을 편리하게 하고, 엔비디아의 NCCL 같은 라이브러리는 노드와 노드 사이의 통신을 최적화해 속도를 높여준다"며 "일부의 수준높은 기업이나 집단에서만 소유하던 이런 기술이 일반 엔터프라이즈와 사용자도 쉽게 활용할 수 있게 됐다"고 덧붙였다.
델테크놀로지스는 AI 영역에서 GPU 가상화 시대의 도래를 예상하고 있다. 기업의 IT인프라가 서버 가상화를 넘어 데이터센터 전체를 소프트웨어로 구성하는 소프트웨어정의데이터센터(SDDC)로 진화하고 있고, 그 안에 GPU 같은 가속 기술도 자연스레 포함된다는 얘기다.
양 전무는 "AI 인프라가 그동안 베어메탈에서 운영되는 게 많았지만, SDDC 영역의 하나로 바뀌고 있다"며 "가상화된 인프라 안에 AI 관련 GPU나 여러 대안 가속 기술도 포함돼 구현돼야 한다는 수요가 많아졌다"고 말했다.
그는 "SDDC 관점에서 보면, GPU도 서비스 대상 중 하나"라며 "원하는 시점에 GPU 가속을 빠르게 쓸 수 있는 '서비스형 GPU'를 구현할 수 있어야 한다"고 덧붙였다.
델테크놀로지스는 관계사인 VM웨어와 협력해 SDDC, 컨테이너 등의 환경에서 GPU 서비스를 제공하는 역량을 강화하고 있다.
VM웨어는 하드웨어 가속기 가상화 기술을 보유한 비트퓨전을 인수했다. 비트퓨전은 VM웨어의 V스피어7에 통합돼 GPU, FPGA, IPU 등을 가상화해 제공할 수 있게 해준다.
기업의 IT환경은 내부적으로 다양한 구성을 갖고 있다. 베어메탈 환경 외에 컨테이너, 클라우드 등 복합적 환경이다.
양 전무는 "훈련을 위한 GPU를 한 기업에서 100개를 갖고 있다고 치고 어느 개발자 한명에게 과제 하나를 위해 100개를 다 몰아줄 수 있다면 가장 좋을 것"이라며 "그러나 기업은 각 개발자에게 그들의 담당 분야에 맞는 환경만 주고, 컨테이너든 가상화든 어떤 형태로 GPU를 쪼개주는 게 훨씬 더 효율적일 것"이라고 설명했다.
그는 "여러 개발자에게 각자 요구하는 자원을 할당해주고, 과제를 끝내면 회수하고, 또다른 훈련에 자원을 다시 묶어서 배분하는 게 필요하다"며 "모든게 베어메탈로 돼 있다면 단일 훈련 입장에서 좋겠지만, 개발 환경 전체를 고려한 수명주기 입장에선 효율적이지 않으므로 서비스 형태로 자원을 주고 회수하는 환경이 필요하다"고 강조했다.
델테크놀로지스는 GPU와 AI 인프라에서 독보적 위치를 점유하는 엔비디아와 긴밀히 협력하는 체제를 구축하고 있다. 엔비디아 톱티어 파트너로서 새로운 GPU 제품이나 소프트웨어 출시 전에 그에 적합한 컴퓨팅 환경을 개발하는 관계다.
이와 함께 GPU 외에 새롭게 등장하는 제2, 제3의 가속 기술도 적극 수용하고 있다. 현 시점에 AI 가속기술 중 GPU의 비중이 절대적이지만, 5년 안에 FPGA나 SOC 등의 비중이 더 커질 것이란 시장조사업체의 전망에 동의한다. 크래프코어의 IPU처럼 새로운 콘셉트를 구체화하는 스타트업과도 협력하고 있다.
델테크놀로지스는 AI의 다양한 시나리오와 특성에 맞는 다양한 인프라 솔루션을 제공한다는 방침이다.

AI 추론을 위해서 엔비디아 텐서RT, ONNX 등을 활용하고자 할 경우 CPU, FPGA, GPU 중심의 AI 워크로드 처리로 빠른 결과를 얻어낼 수 있도록 지원하는 특화 서버인 델 EMC 파워엣지 R740가 대표적이다.
관련기사
- 델테크놀로지스, 쿠버네티스 최적화 HCI 출시2020.09.29
- 델테크놀로지스, SW정의스토리지 '파워플렉스' 출시2020.07.14
- 델테크놀로지스, 엣지 컴퓨팅용 HCI 출시2020.07.01
- 델EMC, 14세대 파워엣지 서버 포트폴리오 발표2019.04.11
▲금융 서비스나 생명공학, 고성능 컴퓨팅(HPC)과 석유·가스 탐사와 같은 산업 분야를 위한 딥러닝 워크로드의 경우 가속기에 최적화된 고밀도 서버인 '델EMC 파워엣지 C4140' ▲높은 가속기 집적도, 빠른 설치를 위한 ML 스택, 학습 데이터에 빠르게 액세스할 수 있는 로컬 스토리지 지원 등이 필요한 머신러닝 특화 서버 '델EMC DSS 8440' 등도 있다. 델EMC DSS8440 서버의 경우 엔비디아 토폴로지 외에도 그래프코어 IPU 토폴로지도 지원한다.
양 전무는 "델은 AI 컴퓨팅 자원 외에도 스토리지, 가속기, 네트워킹 인프라, 전문가 컨설팅 서비스 등을 아울러 고객의 AI 인프라 구축을 지원할 수 있다"며 "어떤 고객 수요에도 대응할 수 있는 다양한 라인업을 갖고 있다"고 강조했다.





