






인공지능(AI) 연구에 박차를 가하고 있는 네이버가 세계적인 컨퍼런스에서 연이어 성과물을 발표한다.
특히 이번에 발표할 논문에는 이미지와 텍스트의 관계를 파악하는 방법, 동작 인식 연구 등이 포함돼 있어 향후 활용 방안에 관심이 쏠리고 있다.
네이버의 핵심기술연구를 책임지고 있는 네이버랩스와 네이버랩스유럽은 세계적으로 주목받는 컨퍼런스인 '컴퓨터 비전 및 패턴 인식 컨퍼런스(CVPR)2017'에서 5편의 논문을 발표한다.
이 중 2개 논문은 전체 컨퍼런스 발표 논문 중 상위 8%내에 들어야 자격이 주어지는 '스포트라이트 세션'에서 발표할 예정이어서 관심이 쏠린다.
최근 들어 AI 기술쪽에서 가장 활발하게 연구되고 있는 분야 중 하나는 어떻게 하면 컴퓨터가 세상을 보고 이해할 수 있는지에 대한 것이다.
네이버랩스와 네이버랩스 유럽(前 제록스리서치센터, XRCE)은 이 분야에서 주목할만한 결과를 내놨다.

■ 문장 속 단어와 이미지 일부를 연결시킨다
CVPR2017 상위 8% 기준을 통과한 네이버랩스의 논문 중 한 편은 이미지와 텍스트 간 관계를 보다 긴밀하게 파악하는 방법에 대한 것이다.
네이버랩스는 지난해 CVPR2016에서 열린 '비전 퀘스천 앤서링(VQA)' 챌린지에서 2등을 차지했다. 이 대회는 사진을 주고 이에 대한 질문을 한 뒤 보다 정확한 답을 찾아낸 알고리즘에게 높은 점수를 준다.
올해 CVPR2017에선 지난 해보다 한 단계 업그레이드된 DAN알고리즘 관련 논문을 내놨다.
이 회사가 발표한 '멀티모달 추론과 매칭을 위한 DANs(Dual Attention Networks for Multimodal Reasoning and Matching)'라는 제목의 논문은 시각적 주의(visual attention)와 문자적 주의(textual attention) 간의 상호작용을 활용해 AI를 학습시키는 프레임워크에 대한 내용을 담고 있다.(논문링크)
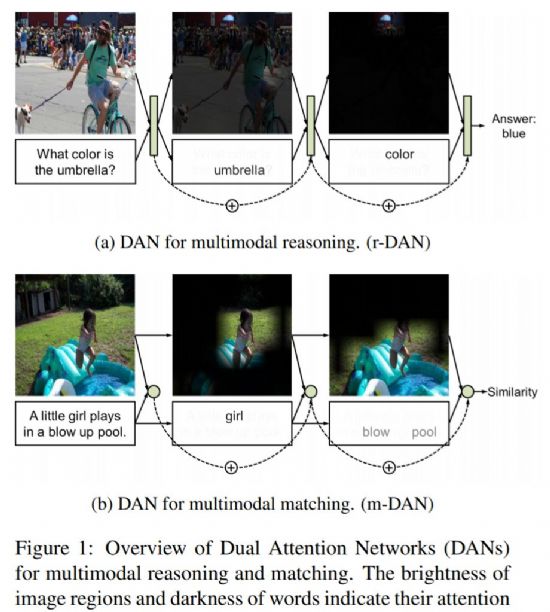
지난해에 비해 눈에 보이는 이미지와 연관되는 텍스트 간의 관계를 더 명확하게 파악할 수 있게 됐다는 뜻이다.
논문에서는 이러한 방법을 추론모델, 매칭모델에 각각 적용할 수 있다고 설명했다.
추론모델은 특정한 이미지와 이와 관련된 질문이 주어지는 상황을 AI 알고리즘에게 보여주면서 학습시키는 과정을 말한다.
예를 들면 "우산의 색깔은?"이라고 질문하면 전체 이미지 내에서 먼저 '우산'에 주목해 이미지를 찾아낸 다음 '우산의 색깔'을 나타내는 영역을 정확하게 추론해서 '파란색'이라는 답을 내놓는 식이다.
매칭모델은 주어진 이미지와 텍스트 내 단어들 간 유사성이 높은 결과를 찾는 방안이다. 네이버랩스 블로그에 따르면 텍스트와 가장 비슷한 이미지, 이미지와 가장 비슷한 텍스트 등을 검색하는데 활용할 수 있다.
이를테면 여자아이가 공기풀에서는 노는 모습을 담은 전체 이미지와 '작은 여자아이가 공기풀에서 놀고 있다(A little girl plays in a blow up pool)'는 문장과 매칭시켜 놓은 뒤 AI 알고리즘에 여자아이(girl)를 입력하면 그 부분만 주목도를 높이는 식이다.

■ 사물에 가려진 사람 동작도 예측
두번째 논문은 컴퓨터가 주위 사물이나 다른 사람들에게 가려진 이미지를 본 뒤 사람의 정확한 동작을 인식하고, 이해할 수 있는 방법에 대한 것이다.
네이버랩스 유럽이 발표한 'LCR-Net: 인간 동작을 위한 로컬라이제이션-분류-회귀(LCR-Net: Localization-Classification-Regression for Human Pose)'가 그것이다.(논문링크)
이 논문은 사람의 모습이 담긴 이미지를 보고 3가지 방법을 동원해 움직임을 파악하는 방법을 다뤘다.
관련기사
- 네이버, 컴퓨터 비전 컨퍼런스서 AI 기술 공유2017.07.25
- 네이버랩스, 유럽 최대 AI 연구소 인수 비결은?2017.07.25
- 네이버 품에 안긴 XRCE, 어떤 AI기술 가졌나2017.07.25
- 네이버 서비스엔 어떤 AI 녹아 있나2017.07.25
먼저 이미지를 보고 어떤 동작을 하고 있는지를 추측한다. 그 뒤에는 여러 후보군들을 비교해 가장 이미지 속 사람의 움직임을 정확하게 반영한 동작 제안에 더 높은 점수를 준다. 이런 과정을 반복해 가장 실제와 가까운 동작을 알아낸다.
논문에서는 특히 2D나 3D 형태로 여러 사람들의 동작을 동시에 예측해낼 수 있다는 점을 성과로 내세웠다.





