SW공학의 역사
SW 공학(Software Engineering)은 1960년대 후반 미국과 유럽을 중심으로 본격적으로 발전하기 시작했다. 1960년대 IBM system/360용 OS/360 개발 프로젝트는 과도한 납기 지연과 원가 초과를 겪었고, 당시 미국 국방 및 대형 공공 시스템 프로젝트들도 잇따라 납기 지연과 품질 문제를 겪었다. 1968년 NATO가 주관한 국제회의(NATO Software Engineering Conference in Garmisch, Germany)에서 SW 개발의 위기(Software Crisis)를 공식 선언하고, 그 해결책으로 SW 공학의 연구개발이 시작됐다.
SW공학이 1960년대 이전의 SW 개발 방식과 다른 점은 시스템 구현 이전에 분석과 설계를 체계적으로 수행하고, 개발 전 과정에서 표준 프로세스, 표준화된 기법과 도구를 활용한다는 것이다.
요구 분석은 개발 명세를 사전에 규명함으로써 요구 결함(Requirement Error)으로 인한 재작업(Rework)을 줄인다. 명확한 인수 기준은 테스트 자동화의 기반이 되며, 자동화된 회귀 테스트는 지속적인 코드 내부 구조 개선(Refactoring)을 안전하게 뒷받침한다.
설계에는 시스템 전체의 아키텍처 설계와 상세 수준의 코드 설계가 있다. 아키텍처 설계는 시스템을 구성하는 컴포넌트 간의 통합 효율을 높인다. 상세 설계와 코드 구조 설계는 코드의 가독성과 변경 용이성을 높여 SW의 장기적인 유지보수성(Maintainability)을 확보한다.
요구 스펙과 SW 설계를 자연어로 표현할 때 발생하는 모호성(Ambiguity)을 제거하기 위해 UML(Unified Modeling Language), BPMN(Business Process Model and Notation), ERD(Entity-Relationship Diagram), ArchiMate, C4와 같은 특수한 그래픽 부호를 사용하는 비주얼 모델링 언어(Visual Modeling Notation)를 국제 및 업계 표준으로 정착시켜 왔다.
SW공학은 오늘날 AI 코딩 에이전트 시대에도 여전히 중요하다. AI가 코드를 생성하더라도, 대규모 프로덕션 시스템의 품질과 유지보수성은 결국 체계적인 SW 공학에 의해 좌우된다.
SW코딩 자동화의 역사
1980년대 이후 코딩 자동화 기술은 본격적으로 발전해 왔다. 1980년대 말 Texas Instruments가 개발한 IEF(Information Engineering Facility)는 메인프레임 COBOL 코드를 100% 자동 생성하는 CASE(Computer-Assisted Software Engineering) 툴로, 금융·공공 분야의 대규모 엔터프라이즈 시스템 코드를 자동 생성하는 데 활용됐다.
1990년대에는 Unix C, Windows C++, Java 등을 자동 생성하는 다양한 모델 기반 CASE 툴들(Composer, Obsydian, ObjectTeam 등)이 등장했다. 그러나 요구사항 변화에 대한 유연성 부족과 복잡한 모델링 부담으로 인해 1990년대 후반부터 CASE 툴의 인기가 하락하기 시작했다.
2000년대에 들어서는 객체 지향 프로그래밍 언어를 사용하는 웹 애플리케이션의 반복 점증적 개발이 새로운 SW 개발 패러다임으로 확산됐다. UML 모델 기반의 100% 코드 자동 생성을 추구하는 MDA(Model-Driven Architecture) 툴이 개발되었으나 대중적인 개발 패러다임으로 확산되지는 못했다. 대신 Spring, Ruby on Rails, Django 등 오픈 소스 웹 애플리케이션 프레임워크가 개발 시장을 장악했다. 한편 Rational Rose, Sparx EA(Enterprise Architect) 같은 비주얼 모델링 툴은 코드 생성 툴과 분리되었지만, 코드 스켈레톤(Code Skeleton) 생성과 Round-Trip Engineering을 가능하게 해 널리 활용됐다.
2010년대 후반 이후 비주얼 모델 기반으로 애플리케이션을 자동 생성하는 Low-Code 개발 플랫폼(Outsystems, Mendix, Appian, Microsoft PowerApps 등)이 급속히 확산되기 시작했다. (박준성, Fundamentals of Low-Code Development, kosta-online.com 참조)

같은 시기에 템플릿 기반의 시각적 Drag-and-Drop을 통해 WYSIWYG(What You See Is What You Get) 방식으로 애플리케이션을 자동 구성하는 No-Code 개발 플랫폼(Wix, Bubble, AppSheet, Webflow 등)도 급속히 확산되었다. Gartner는 2022년 보고서에서 기업 신규 애플리케이션 개발 중 Low-Code/No-Code(LCNC) 비중이 2020년 25%에서 2026년 75% 수준까지 증가할 것으로 전망했다. (Gartner, Forecast Analysis: Low-Code Development Technologies-Worldwide, 2022). 실제로 2024년에 이미 다수 기업이 Low-Code 개발 플랫폼을 도입하면서 이러한 방향성이 현실화됐다.
오늘날 AI 코딩 에이전트가 코딩 자동화에 큰 관심을 불러일으키고 있지만, 위에서 보았듯이, 코딩 자동화는 새로운 현상이 아니다. LCNC(Low-Code/No-Code) 플랫폼이 이미 애플리케이션의 자동 구축에 널리 활용되고 있다. LCNC 플랫폼은 자유도를 제한한 표준 아키텍처, 메타데이터 모델, 시각적 제약 조건 위에서 동작했기 때문에 높은 생산성과 안정성을 동시에 확보할 수 있었다. 반면 자연어 기반 AI 코딩 에이전트는 훨씬 더 높은 자유도를 제공하지만, 환각(Hallucination)과 구조적 일관성 붕괴라는 새로운 위험을 안고 있다. 따라서 AI 코딩 에이전트가 LCNC를 넘어 엔터프라이즈 프로덕션 시스템 개발의 주류가 되기 위해서는, SW공학적 제약 조건을 에이전트 코딩 프로세스에 강하게 내재화해야 한다.
생성형 AI 기반 코딩 지원 및 자동화의 등장
2020년대 들어 생성형 AI(Generative AI, GenAI) 기반의 Vibe Coding, AI Coding Assistant 및 AI Coding Agent가 확산되고 있다. Vibe Coding은 자연어 프롬프트를 통해 애플리케이션을 빠르게 생성·수정해 가는 실험적 개발 방식이다. 테스트 후 에러가 있으면 자연어로 피드백을 주면서 반복적으로 개선해 나간다. Claude, ChatGPT 같은 범용 AI Chatbot 또는 Lovable, Bolt.new, Replit 같은 전문 Vibe Coding 툴을 사용한다.
오늘날 대부분의 AI 코딩 툴들은 Vibe Coding, AI Coding Assistant, AI Coding Agent 기능을 모두 갖추고 있으며, 일부는 통합 개발 환경(IDE)에 내장되어 있다. GitHub Copilot, Cursor, Amazon Q Developer 등 AI Coding Assistant는 개발자의 코딩을 지원해 생산성을 높이는 데 사용된다.
코드 완성(Code Completion), 코드 생성, 리팩토링, 디버깅, 문서화, 코드 번역 등을 지원한다. Cursor, Claude Code, GitHub Copilot 등 AI Coding Agent는 개발자와 상호작용하며 시스템 목표 구현, 요구사항 개발, 테스트 생성, 오류 수정, 설계 개선, 문서화 등을 계획-실행-검증 루프를 통해 반자율적으로 수행한다. Vibe Coding은 대규모 프로덕션 시스템 구축에는 한계가 있다. 프로덕션 시스템의 구축에 사용할 수 있는 AI Coding Assistant 및 Agent는 LCNC 플랫폼과 비교했을 때 아래 표 1과 같은 특징을 갖추고 있다.
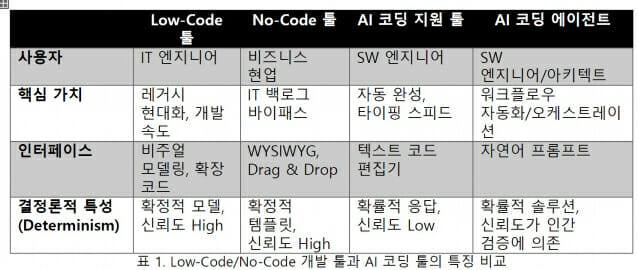
AI Coding Agent가 No-Code 개발 플랫폼에 비해 가지는 장점은 템플릿을 커스터마이즈하는 것보다 프롬프트를 통해 UI를 더 자유롭게 설계할 수 있고, 컴포넌트 단위로 수정하고 조립할 수 있다는 점이다. Low-Code 개발 플랫폼과 비교하면 비주얼 모델링의 어려움에서 벗어나 프롬프트나 이미지를 통해 애플리케이션과 데이터베이스를 생성할 수 있고, 벤더 종속적(Proprietary) 프레임워크에 록인(Lock-in)되지 않으며 Next.js, Tailwind, PostgreSQL 등 표준 오픈 소스 프레임워크로 생성해 IDE 기반 개발 환경으로 이관할 수 있다는 점이다.
그러나 주요 LCNC 플랫폼들은 GenAI Foundation Model을 기반으로 AI Coding Assistant/Agent 기술을 툴 내에 융합함으로써 단점을 극복하고 있다. AI Coding Assistant 기술은 개발자의 비주얼 Drag-and-Drop 및 모델링 작업을 지원하는 데 활용하고, AI Coding Agent 기술은 기존 비주얼 모델링 없이도 자율적으로 애플리케이션을 생성하는 데 활용한다.
가트너와 IDC 자료를 기반으로 시장 규모를 비교해 보면, LCNC 시장이 여전히 AI 코딩 툴 시장보다 훨씬 큰 비중을 차지하고 있음을 알 수 있다. AI 코딩 에이전트가 LCNC 개발 플랫폼 대비 경쟁 우위를 확보하려면 결국 비확정적 출력의 문제를 극복해야 한다. 동일한 프롬프트에도 상이한 결과를 생성하는 비결정성(Non-determinism)과 환각(Hallucination) 현상 때문에 테스트 재현성과 코드 변경의 예측 가능성이 약화되고, 그 결과 CI/CD 파이프라인의 안정성이 저하될 수 있다. 또한 보안 리스크, 기술 부채(Technical Debt) 축적, 저작권 및 규제법 위반, 감사 실패(Audit Failure) 등의 문제도 일으킨다.
LCNC 플랫폼은 메타데이터, 시각적 모델, 플랫폼 제약 조건을 통해 개발 자유도를 제한함으로써 결정론적(Deterministic) 자동화를 달성했다. 반면 AI 코딩 에이전트는 자연어 기반의 개방형 생성(Open-Ended Generation)을 사용하기 때문에 훨씬 높은 유연성을 제공하지만, 동시에 비결정성과 환각이라는 새로운 위험을 초래한다.
LCNC는 제약(Constraint)을 통해 자동화에 성공했다. AI 코딩 에이전트도 엔터프라이즈 프로덕션 시스템 개발의 주류가 되려면 SW공학적 제약과 거버넌스를 내재화해야 한다.
SW공학 기반의 AI 에이전트 코딩
AI 코딩 에이전트의 환각 현상과 비결정성(Nondeterminism)을 없애기 위해서는 SW공학적 제약과 자동화 메커니즘을 체계적으로 적용해야 한다. (박준성, AI Agent Coding Patterns, kosta-online.com 참조)
▲테스트 주도 개발(Test-Driven Development, TDD: Kent Beck, Test-Driven Development, 2002 참조): 에이전트가 소스 코딩 전에 테스트 코드를 먼저 작성하도록 컨텍스트 파일(Context File)에 명기한다. SW 변경 후 즉시 자동 테스트를 실시하도록 Hook을 설치한다. 변경 Commit 전에 Test Coverage가 일정 수준에 미치지 못하면 Commit을 못하도록 Hook을 설치한다. Red-Green-Refactoring 기반의 TDD 사이클을 Skill로 등록해 에이전트의 작업 계획(Task Planning)에 포함한다. Red, Green, Refactoring 단계를 별도의 Subagent가 수행하도록 분리한다.
▲지속적 통합(Continuous Integration, CI: Kent Beck, Extreme Programming Explained, 2004; Martin Fowler, Continuous Integration, martinfowler.com, 2006 참조): 에이전트 코딩에서 CI(즉, Agentic CI)는 TDD처럼 자동화된 Quality Gate이다. SW 변경을 리포지토리의 Main Branch에 Merge할 때 자동으로 Commit, 빌드, PR 생성, 단위/통합 테스트, 정적 분석, 보안 점검을 수행한다. 실패할 경우 에이전트는 Merge를 금지하고, Stack Trace를 피드백 받아 오류를 자가 수정(Self-Correct)한다.
Agentic CI는 GitHub Actions, Buildkite, CircleCI 같은 CI/CD 플랫폼을 사용해 CI Pipeline을 실행하고, AI 코딩 에이전트를 Pipeline 내에서 여러 스텝(코드 리뷰, 수정, 품질 개선)을 수행하는 데 이용한다. 결과적으로 Trunk-Based Development 전략 하에서 Agentic CI를 운영함으로써 항상 릴리스 가능한 Main Branch를 유지할 수 있다. 위의 TDD와 마찬가지로 컨텍스트 파일, Hook, Skill, Subagent를 보완적으로 활용하여 CI 실패를 조기에 탐지하고 예방할 수 있다. 효과적인 CI 운영을 위해서는 높은 수준의 테스트 자동화가 필요하며, TDD는 이를 구현하는 대표적 방법이다. TDD를 통해 누적된 테스트 코드는 CI 파이프라인에서 자동화된 단위·통합 테스트의 기반이 된다.
▲요구 스펙(Requirement Specification: 박준성, The Complete Guide to Business Analysis, kosta-online.com 참조): AI 에이전트를 포함하는 AI 네이티브 애플리케이션을 구축할 때 경영 성과를 달성하려면 에이전트를 포함한 End-to-End 프로세스를 재발명(Reinvention)해야 한다. 애플리케이션의 비즈니스 도메인에서 사용하는 도메인 개념과 의미 체계를 명확히 정의하고 표준 용어를 사용해 프로세스를 설계해야 한다. 애플리케이션에서 구현해야 할 혁신적인 기능을 사용사례(Use Case)로 명확히 정의하고, 시나리오로 구체화할수록 요구사항의 구현 오류를 줄일 수 있다. (박준성, AI 에이전트 성공의 핵심 조건, kosta-online.com 참조)
이러한 요구 분석은 AI 코딩 에이전트를 사용해 애플리케이션을 개발하기 전에 미리 수행한다. 프로세스 모델은 국제 표준인 BPMN(Business Process Model and Notation)을 이용해 설계할 수 있다. 시맨틱 모델은 종래 UML 클래스 다이어그램으로 작성했지만, AI 코딩 에이전트를 사용할 때는 온톨로지(Ontology)를 병행 활용하는 것이 효과적일 수 있다. 온톨로지는 개념 간의 관계와 제약을 명시적으로 표현하므로, AI 코딩 에이전트가 도메인 의미를 더 정확히 해석하고 일관된 코드를 생성할 가능성이 높다.
아래 '그림 1'은 요구 분석 산출물과 그들 간의 의존 관계를 보여준다. 프로세스 모델, 시맨틱 모델(Business Object Model), 사용사례 모델, UX 모델, 서비스 모델 간의 긴밀한 의존 관계를 정확히 준수해야 일관성 있고 완전한 요구 스펙을 만들 수 있다.
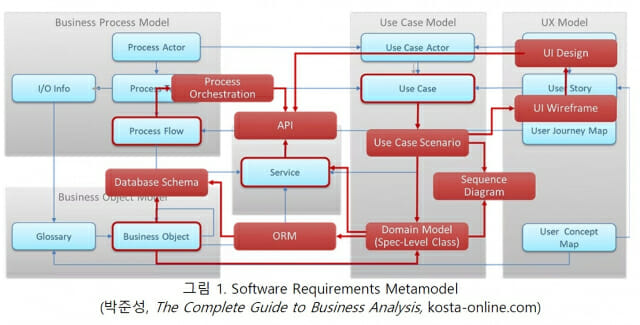
앞에서 1970년대 SW공학 등장 이후, 인간들 사이에서도 자연어의 모호성 때문에 모델링 언어를 만들어 요구 스펙과 SW 설계의 문서화에 사용했다는 사실을 지적했다. AI 코딩 에이전트도 마찬가지로 자연어 프롬프트보다는 더 상세한 Markup Language(Markdown, HTML 등), Serialized Language(JSON, YAML 등), Modeling/Domain Specific Language(UML, BPMN, BDD, User Story, Ontology 등), 프로그래밍 언어(Python, Typescript 등)를 더 안정적으로 처리할 수 있다.
프로세스 모델, 시맨틱 모델 및 사용사례를 AI 코딩 에이전트의 요구 스펙에 반영할 때는 그대로 이미지나 텍스트 형태로 입력할 수도 있고, 사용자 스토리(User Story)와 BDD(behavior-Driven Development)의 Gherkin 문장으로 변환해 입력할 수도 있다. BDD 문장은 생성된 코드의 인수 테스트(Acceptance Test) 기준을 제공한다. (Dan North, Introducing BDD, dannorth.net, 2006)
이러한 변환 자체도 AI 코딩 에이전트에게 위임할 수 있다. 예컨대, 프로세스 모델을 에이전트에 입력할 때 Mermaid.js 같은 다이어그램 DSL로 변환해 제공할 수 있다. 온톨로지는 JSON-LD나 Turtle(.ttl)로 직렬화(Serialize)해서 제공할 수 있다. 사용자 스토리와 BDD 문장이 생성되면 분석가(Business Analyst)가 오류가 없는지 검토해야 한다.
분석자 리뷰를 패스하면 에이전트가 사용자 스토리와 BDD 문장을 기반으로 코드를 작성한다. 앞의 TDD 기법에서 설명했듯이 소스 코딩 이전에 테스트 코드를 작성해야 하므로, 에이전트는 사용자 스토리와 BDD 문장에서 TDD 테스트 코드를 도출한다.
BDD 문장 작성에 Cucumber 같은 BDD 프레임워크와 Playwright 같은 E2E 테스트 프레임워크를 사용하는 경우, 에이전트는 Step Definition 파일을 기반으로 테스트 코드를 생성한다. BDD 툴을 사용하지 않는 경우에는 에이전트가 BDD 문장을 직접 TDD 테스트 코드로 변환한다. 이와 같이 효과적인 CI 운영은 TDD 기반 테스트 자동화를 필요로 하고, TDD는 BDD에 의존하고, BDD는 프로세스 모델링, 시맨틱 모델링, 사용사례 분석 등 사전(Upfront) 요구 분석을 통해 정확하게 도출된다. (요구 분석 → BDD → TDD → CI)
▲객체 설계(Object Design: Erich Gamma et al., Design Patterns, 1994; Robert Martin, Design Principles and Design Patterns, 2000 참조): AI 코딩 에이전트는 코드를 Python, Typescript 등 객체 지향 프로그래밍 언어(Object-Oriented Programming Language)로 생성한다. 프로덕션 시스템이 갖추어야 할 중요한 품질 속성에는 가독성(Readability), 변경 용이성(Maintainability), 확장성(Extensibility) 및 테스트 용이성(Testability)이 있다.
이러한 속성을 갖추려면 코드가 객체 설계 원칙을 지키고 객체 설계 패턴을 적용해야 한다. AI 코딩 에이전트가 객체 설계 원칙과 패턴을 일관되게 적용하도록 하기 위해서는, 컨텍스트 파일에 원칙과 패턴을 명시하고, CI/CD 파이프라인에서 아키텍처 규칙 검증(Architectural Fitness Function)을 통해 정적 분석(Static Analysis)을 수행하며, 설계 품질 검토를 담당하는 Subagent를 운영하는 등의 Quality Gate가 필요하다.
▲서비스 지향 아키텍처(Service-Oriented Architecture, SOA: OASIS, Reference Model for Service Oriented Architecture, 2006; 박준성, The Complete Guide to SOA, MSA and Modulith, kosta-online.com): AI 코딩 에이전트를 사용하는 데 있어 중요한 제약 조건은 컨텍스트 윈도우(Context Window)의 크기다. 컨텍스트 윈도우에 필요한 최적의 정보만을 적시에 제공하는 것이 에이전트의 효과와 효율을 높이는 방법이다.
SOA는 애플리케이션을 Loosely-Coupled 서비스 단위로 분할하고, 서비스 간에 공개된 표준 API를 통해 연결한다. 따라서 에이전트가 서비스 단위로 독립적으로 코드를 생성할 수 있도록 한다. 에이전트의 컨텍스트가 작은 서비스에 초점을 맞추기 때문에 환각을 줄일 수 있다.
서비스 간 독립성을 높이기 위해서는 애플리케이션 객체 설계 모델에서 하나의 응집된 Business Capability를 실현하고, 일관된 도메인 언어(Ubiquitous Language)를 공유하는 경계인 Bounded Context를 식별해 이를 하나의 서비스로 매핑하는 방법을 취할 수 있다. (Eric Evans, Domain-Driven Design, 2003 참조)
SOA 애플리케이션을 구현할 때, 애플리케이션의 릴리스 사이클이 시간 단위 이하로 짧아야 할 때는 Microservice Architecture(MSA)로 구현해 서비스별로 독립적으로 배포할 수 있다. 이 경우 서비스 단위의 독립적 배포와 피드백 루프 최적화가 가능해져 오류를 신속히 수정할 수 있다.
MSA는 빠른 릴리스에 적합한 SOA 구현 패턴이지만, 유지보수 및 운영의 복잡성 때문에 Modulith(Modular Monolith)나 SBA(Service-Based Architecture) 구현 패턴을 선호하는 경우도 있다. (Mark Richards and Neal Ford, Fundamentals of Software Architecture, 2020)
한 애플리케이션 안에서 서비스에 따라 독립적으로 배포할 수도 있고 집합적으로 배포할 수도 있다. 아래 그림 2는 에이전트 코딩을 통해 구축한 전자상거래 에이전트 시스템으로, 흑색 테두리 박스는 논리적 서비스, 적색 테두리 박스는 물리적 서비스(배포 단위)를 나타낸다. (박준성, AI 에이전트의 물리적 아키텍처 - Modulith, SBA 및 MSA의 Hybrid 아키텍처, kosta-online.com 참조)
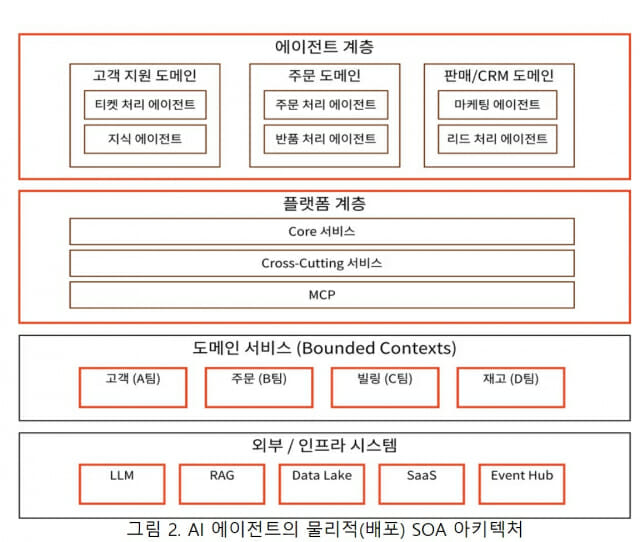
AI 에이전트 코딩에서 SOA를 실현하기 위해서는 우선 아키텍트가 SOA 아키텍처를 설계하고, OpenAPI나 Protocol Buffers를 이용해 각 서비스의 API를 정의한다. 에이전트의 프로젝트 구조 파일에서 각 서비스를 독립적인 리포지토리로 정의할 수도 있고, Monorepo를 정의할 수도 있다.
Monorepo를 사용한 경우, 정적 분석을 통해 SOA의 서비스 캡슐화(Service Encapsulation) 원칙, 즉 API 이외의 방식으로 다른 서비스에 직접 접근할 수 없다는 원칙을 위반했는지 검증한다. 에이전트는 API Contract를 준수하는 코드를 생성한다. SOA에서는 API의 확장은 허용하지만 하위 호환성을 깨는 변경은 제한하는 것이 중요하다. 이 원칙이 위반됐는지 CI 파이프라인에서 검증하고, 위반한 경우 빌드를 취소한다.
관련기사
- [박준성의 SW] AI 경쟁력?... 모델 도입이 아니라 리더부터 개발자까지 AI 역량 내재화 해야2026.05.23
- [박준성의 SW] AI 에이전트 성공의 핵심 조건2026.05.01
- [박준성의 SW] AI 에이전트 허와 실2026.04.21
- 삼성전자, 2030년까지 신규 팹 4곳 구축…용인·평택·호남 전방위 투자2026.07.21
결론
AI 코딩 에이전트는 시니어 분석가/아키텍트/엔지니어가 가이드하고 검증해야 하는 주니어 개발자와 같다.에이전트와 시니어 전문가가 Pair Programming을 하는 것과 같다. 시니어의 역할은 SW 공학의 원칙, 패턴과 베스트 프랙티스를 잘 적용, 현장 사용자가 신뢰할 수 있고 미래에 장기적으로 발전·확장해 나갈 수 있는 애플리케이션을 구축하도록 관여하고 책임을 지는 것이다.
*본 칼럼 내용은 본지 편집방향과 다를 수 있습니다.