정창욱 UNIST 반도체소재·부품대학원 교수 연구팀은 새로운 입력 데이터를 기존에 학습한 데이터 기준에 맞게 재정렬하는 ‘π-불변 테스트 시점 보정'’ 알고리즘을 개발했다고 26일 밝혔다.
연구 결과는 인공지능 분야 3대 국제학회로 꼽히는 국제표현학습학회(ICLR) 2026에 채택됐다.
반도체 공정이나 칩, 패키지 설계에서는 내부에서 열이 어디에 얼마나 퍼지고, 힘이 어디에 집중되는지를 미리 파악해야 한다. 열이 특정 부위에 몰리면 성능이 떨어지거나 고장이 날 수 있고, 반복적으로 힘이 쌓이면 미세한 균열이나 파손으로 이어질 수 있기 때문이다.
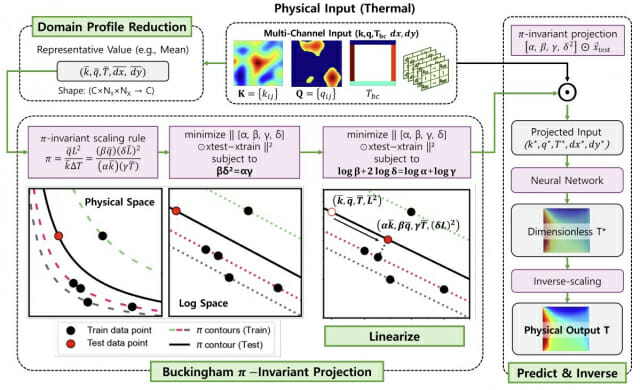
연구팀은 이에 '버킹엄 π 불변량' 개념을 바탕으로, 새 입력이 들어오면 이를 그대로 예측에 사용하지 않고 먼저 학습 데이터와 물리적으로 유사한 형태로 보정하는 ‘π-불변 테스트 시점 투영’ 알고리즘을 개발했다.
이는 π 값은 유지하면서 입력 스케일만 조정하므로 물리적 의미를 보존할 수 있다. 로그 공간 최소제곱 최적화를 이용해 재학습 없이 기존 모델에 바로 적용할 수 있다. 또 대표값 비교 방식을 도입해 계산 비용도 크게 줄였다.
이 방법을 열전도와 탄성 해석 문제에 적용한 결과, OOD에서도 평균 오차(MAE)를 최대 약 91%까지 줄이는 성능 향상을 확인했다.
관련기사
- UNIST 연구실 한곳서 세계 3대 AI학회 논문 3편 동시 발표2026.04.21
- 조선소 파운데이션 모델 개발 400억원 투입…산업현장 적용 추진2026.04.12
- UNIST–고려아연, 4개월 AI 교육했더니 현장혁신 방안 32건 쏟아져2026.02.18
- AI 더 똑똑하게 만드는 '수학적 방법' 찾았다2026.01.19
학습 데이터를 전부 일일이 비교하는 대신 비슷한 데이터끼리 묶어 대표 값만 비교하는 방식을 적용해 계산 부담도 줄였다. 기존의 전수 비교보다 약 100분의1 수준의 비용으로도 빠르게 입력을 보정할 수 있다.
정창욱 교수는 "유체 역학의 난제로 불리는 나비에-스토크스 방정식에도 적용했을 때도 비슷한 성능 개선 효과가 확인됐다"고 말했다.