







뉴욕대학교(New York University), 스탠퍼드대학교(Stanford University), 카네기멜론대학교(Carnegie Mellon University) 공동 연구팀이 AI 모델의 다양한 답변 생성 능력을 측정하는 새로운 방식을 제안했다.
연구팀은 18개의 대형 언어 모델(LLM)을 분석한 결과, 모든 질문에 가장 다양하고 질 높은 답변을 생성하는 단일 모델은 존재하지 않는다는 사실을 발견했다. 대신 질문마다 최적의 모델이 다르며, 이를 자동으로 선택하는 라우터(Router)를 훈련시키면 단일 최적 모델 대비 26.3%의 성능을 달성할 수 있다는 점을 입증했다. 이는 AI를 활용해 창작, 코딩, 교육 콘텐츠를 만들 때 하나의 모델에만 의존하는 것이 최선이 아닐 수 있음을 시사한다.
다양성 커버리지, AI 답변의 폭과 질을 동시에 측정하다
연구팀은 AI 모델이 생성한 답변 세트의 다양성과 품질을 함께 평가하는 '다양성 커버리지(Diversity Coverage)'라는 새로운 지표를 제안했다. 기존 평가 방식은 단일 답변의 정확도나 답변 간 유사도만 측정했기 때문에, 창작이나 브레인스토밍처럼 여러 가지 유효한 답변이 존재하는 개방형 질문에는 적합하지 않았다.
다양성 커버리지는 생성된 답변 세트에서 중복을 제거한 뒤 각 답변의 품질 점수를 합산하고, 이를 동일한 개수의 답변으로 도달할 수 있는 최대 점수로 나눈 값이다. 예를 들어 "북미 국가를 하나 말해보세요"라는 질문에 미국, 캐나다, 멕시코를 각각 한 번씩 답하면 100%의 커버리지를 달성하지만, 미국만 세 번 반복하면 33%에 그친다. 이 지표는 AI가 얼마나 넓은 답변 공간을 탐색했는지를 정량화한다.
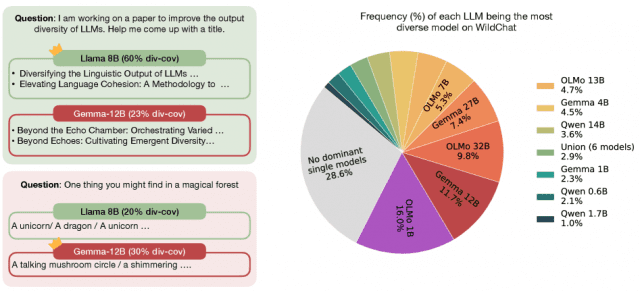
그림 1. 모델별 다양성 차이와 NB-WildChat에서 단일 최우수 모델이 존재하지 않음을 보여주는 분석 결과.
라마(Llama) 70B도, 큐엔(Qwen) 72B도, 모든 질문의 정답은 아니다
연구팀은 라마(Llama), 큐엔(Qwen), 올모(OLMo), 젬마(Gemma) 등 4개 모델 패밀리에서 1B부터 72B 파라미터까지 18개 모델을 대상으로 실험을 진행했다. NB-WildChat 데이터셋의 1,000개 질문을 분석한 결과, 질문마다 최적 모델을 선택하면 33.0% 다양성 커버리지를 기록했다.
그러나 이 '최적 모델'은 질문마다 달랐다. 예를 들어 어떤 질문에서는 라마(Llama) 3.3 70B가 최고 성능을 보였지만, 다른 질문에서는 큐엔(Qwen) 0.6B 같은 소형 모델이 더 나은 결과를 냈다.
모델 크기나 패밀리만으로는 다양성 성능을 예측할 수 없었다. 연구팀은 "만약 질문마다 최적 모델을 선택할 수 있다면 33.0%의 커버리지를 달성할 수 있지만, 단일 최고 모델을 고정해서 쓰면 23.8%에 머문다"고 밝혔다. 이 9.2%포인트 격차는 매일 수십 개의 질문을 처리하는 실무 환경에서 누적되면 결과물의 질적 차이로 이어진다.
질문만 보고 최적 모델을 고르는 라우터 훈련
연구팀은 질문마다 가장 다양한 답변을 잘 만들 모델을 골라주는 ‘라우터’를 개발했다.
이 라우터는 질문을 보고 18개 후보 모델 중 하나를 선택한다. 실험 결과, 라우터는 NB-WildChat에서 26.3%의 다양성 커버리지를 기록해 단일 최고 모델(23.8%)보다 높은 성능을 보였다.
NB-Curated에서도 약 40% 안팎의 성능을 보여, 다른 유형의 질문에도 일정 수준 일반화되는 경향을 확인했다. 연구팀은 "라우터는 질문 텍스트를 기반으로 모델 선택 패턴을 학습하는 것으로 나타났다"고 설명했다.
두 모델을 조합하면 성능은 더 오른다
연구팀은 한 단계 더 나아가, 질문마다 두 개의 모델을 함께 선택해 답변을 합치는 방식도 실험했다. 쉽게 말해, 하나의 모델 대신 두 모델의 아이디어를 섞는 방법이다. 이 방식은 성능을 조금 더 끌어올려, NB-WildChat에서는 약 26.7%, NB-Curated에서는 약 42.2% 수준을 기록했다. 즉, 하나의 모델만 사용할 때보다 더 다양한 답변을 얻을 수 있었다. 그 이유는 간단하다. 서로 다른 모델을 쓰면 겹치는 답변은 줄고, 새로운 아이디어는 늘어나기 때문이다.
다만 단점도 있다. 모델을 두 개 동시에 실행해야 하므로 시간과 비용이 더 든다. 따라서 실제로는 성능을 조금 더 높일지, 비용을 줄일지 상황에 따라 선택해야 한다. 또한 연구팀은 학습 데이터가 많을수록 라우터 성능이 좋아지는 경향도 확인했다.
프롬프트 바꾸면 결과도 달라진다… 라우터는 환경에 따라 성능 흔들려
연구팀은 라우터가 특정 프롬프트 방식에만 맞춰 학습된 것은 아닌지 확인하기 위해, 훈련 때와 다른 방식의 프롬프트로 추가 실험을 진행했다.
훈련 시에는 "가능한 한 많은 답변을 나열하라"는 명시적 지시를 포함한 프롬프트를 사용했지만, 테스트에서는 일반적인 단일 답변 생성 프롬프트와 자기 일관성(Self-Consistency) 샘플링 방식도 적용했다.
그 결과, 프롬프트 방식에 따라 성능 차이가 크게 나타났고, 특히 한 번에 여러 답을 생성하는 방식이 가장 높은 다양성을 보였다.
하지만 중요한 점은, 한 프롬프트로 학습한 라우터가 다른 프롬프트에서는 성능이 잘 나오지 않았다는 것이다. 즉, 라우터는 프롬프트와 무관하게 항상 잘 작동하는 시스템이 아니라, 어떤 방식으로 답을 생성하느냐에 영향을 받는 구조였다.
또한 연구팀은, 여러 답을 한 번에 생성하는 방식은 다양성은 높지만 뒤로 갈수록 답변의 질이 떨어지는 경향도 함께 확인했다고 밝혔다.
모델 앙상블은 선택이 아니라 필수가 될 수 있다
이 연구는 단일 AI 모델에 의존하는 현재의 일반적 관행이 최선이 아닐 수 있음을 데이터로 보여준다. 특히 창작, 교육 콘텐츠 생성, 마케팅 카피 작성처럼 다양한 아이디어가 필요한 작업에서는 질문마다 최적 모델이 다를 가능성이 크다.
다만 이 연구는 18개의 오픈소스 모델만을 대상으로 했기 때문에, GPT-4나 클로드(Claude) 같은 최신 클로즈드 모델이 포함될 경우 결과가 달라질 수 있다. 또한 라우터 훈련에는 모든 후보 모델의 답변을 미리 생성해야 하므로 초기 데이터 구축 비용이 크다.
그럼에도 불구하고 라우터가 한 번 훈련되면 추론 시에는 단일 모델만 실행하면 되기 때문에, 장기적으로는 비용 효율적일 수 있다. 이 접근법이 실무에 정착하려면 라우터의 일반화 성능과 훈련 데이터 확보 방법에 대한 추가 연구가 필요하다. 그러나 적어도 한 가지는 분명하다. AI 모델을 '하나만' 쓰는 시대는 끝나가고 있다.
FAQ( ※
이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q.
다양성 커버리지는 어떤 상황에서 중요한가요?
창작 글쓰기, 브레인스토밍, 교육 콘텐츠 생성처럼 여러 가지 유효한 답변이 존재하는 작업에서 중요합니다. 단일 정답이 있는 질문보다는 다양한 관점이나 아이디어를 탐색해야 하는 경우에 이 지표가 유용합니다.
Q.
라우터는 어떻게 최적 모델을 선택하나요?
라우터는 질문 텍스트를 분석해 각 모델이 얼마나 다양한 답변을 생성할지 예측합니다. 훈련 과정에서 수천 개의 질문에 대해 각 모델의 실제 성능 데이터를 학습하기 때문에, 새로운 질문이 들어왔을 때 패턴을 인식해 최적 모델을 고를 수 있습니다.
Q.
일반 사용자도 이 방식을 활용할 수 있나요?
현재는 연구 단계이지만, 향후 API 서비스나 플랫폼 형태로 제공될 가능성이 있습니다. 사용자가 질문을 입력하면 자동으로 최적 모델을 선택해 답변을 생성하는 방식으로 구현될 수 있습니다.
기사에 인용된 리포트 원문은 arXiv에서 확인할 수 있다.
리포트명: No Single Best Model for Diversity: Learning a Router for Sample Diversity
관련기사
- AI 에이전트가 기억을 지우는 법? 더 똑똑해지려면 잊어야 한다2026.04.06
- AI가 검색창 대체하고 있다…쇼핑 시작점 바뀌었다2026.04.06
- AI가 사람 움직임을 '언어'처럼 이해하게 됐다2026.04.02
- 차세대중형위성 4호, 스발바르와 첫 교신…태양전지판 정상 전개2026.07.07
이미지 출처: AI 생성 콘텐츠
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)





