







AI가 학교 수업 자료를 평가한다면 어떤 일이 벌어질까. 미국 워싱턴주립대와 뉴욕주립대 버팔로 캠퍼스 공동 연구팀이 GPT-4o, 클로드 소넷 4(Claude Sonnet 4), 제미나이 2.5 프로(Gemini 2.5 Pro) 세 가지 AI 모델에게 미국 초중등 과학 수업 자료를 평가하게 한 뒤, 그 결과를 교육 전문가의 판단과 비교하는 실험을 진행했다. 결과는 예상보다 훨씬 복잡하고 흥미로웠다.
AI 채점관 등장: 648개의 평가 데이터가 말해주는 것
연구팀은 미국 전역에서 검증된 초중등 과학 교육과정 12개 단원을 선정했다. 생명과학, 물리과학, 지구과학 분야에 걸쳐 있는 이 자료들은 모두 미국 과학교육 국가표준(NGSS, Next Generation Science Standards)에 맞게 설계된 고품질 커리큘럼이다.
연구팀은 세 AI 모델에게 동일한 기준표—교육 자료 품질을 9가지 항목으로 평가하는 이퀴프(EQuIP) 루브릭—를 적용해 각 수업 자료를 평가하도록 했다. AI는 각 항목에 0~3점 사이의 점수를 매기고, 그 이유를 글로 설명한 뒤 개선 방향까지 제시했다. 이 과정에서 총 648개의 평가 결과물이 생성됐다. 두 명의 과학교육 전문가가 이 결과물 전체를 검토하며 동의 여부를 판단했다.
점수보다 이유가 더 믿을 만하다: 전문가 동의율의 반전
실험 결과에서 가장 눈에 띄는 점은 AI가 매긴 숫자 점수보다 그 이유 설명에 전문가들이 훨씬 더 많이 동의했다는 사실이다. 점수에 대한 전문가 평균 동의율은 69.6%에 그쳤지만, AI가 작성한 이유 설명에 대한 동의율은 86.1%, 개선 제안에 대한 동의율은 82.5%에 달했다.
모델별로 살펴보면 개선 제안 동의율은 제미나이(Gemini)가 88.9%로 가장 높았고, 클로드(Claude)가 81.3%, GPT가 77.2% 순이었다. 즉, AI가 내린 결론(점수)보다 그 결론에 이르는 과정(논리와 설명)이 인간 전문가의 눈에 더 타당하게 보였다는 뜻이다. 이는 AI를 교육 평가에 활용할 때 단순히 점수를 자동화하는 방식보다, AI의 설명을 교사가 참고하는 방식이 훨씬 유용할 수 있음을 시사한다.
제미나이는 후하고, 클로드는 엄격하고, GPT는 그 사이: AI마다 다른 채점 철학
세 모델의 성격 차이는 데이터에서 뚜렷하게 드러났다. 제미나이는 평균 2.96점(3점 만점)을 부여하며 가장 후한 평가자였고, GPT-4o는 2.81점으로 그 뒤를 이었다. 반면 클로드는 2.18점으로 훨씬 엄격한 채점 성향을 보였다. 전문가 동의율도 극명하게 갈렸다. 점수 항목에서 제미나이의 전문가 동의율은 87.1%, GPT는 84.3%였지만, 클로드는 고작 37%에 불과했다. 흥미롭게도 클로드의 개선 제안에 대한 동의율은 81.3%로 다른 두 모델과 비슷한 수준이었다. 즉 클로드는 점수는 너무 짜게 줬지만 조언의 내용 자체는 전문가들이 납득할 만했다는 것이다.
연구팀은 이 차이를 각 모델의 설계 철학에서 찾는다. GPT-4o와 제미나이는 텍스트, 이미지, 오디오 등 다양한 정보를 통합적으로 처리하는 멀티모달(multimodal) 기반 모델로, 전반적인 패턴을 인식하는 방식으로 평가한다. 반면 클로드는 '헌법적 AI(Constitutional AI)'라는 방식으로 훈련되어 안전하고 정확하며 해롭지 않은 출력을 우선시한다. 이 특성이 교육 평가에서는 규칙 기반의 엄격한 채점으로 나타났다는 분석이다.
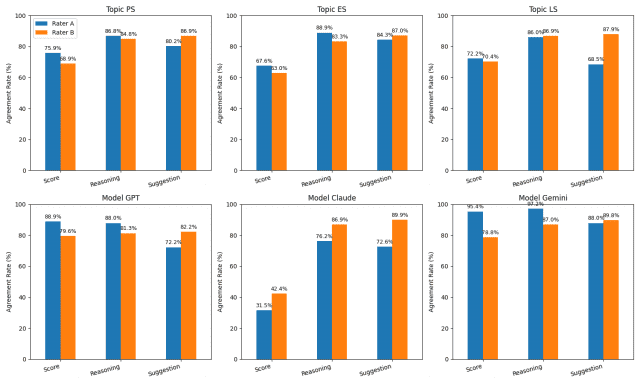
그림 2. 과학 분야별(위), AI 모델별(아래) 전문가 동의율(%) 비교 막대그래프
같은 수업, 전혀 다른 점수: AI와 인간 모두 '판단 기준'이 다르다
연구팀이 제시한 두 가지 실제 사례는 이 문제를 더 구체적으로 보여준다. 첫 번째는 초등학교 3학년 물리과학 수업으로, 학생들이 일상 재료로 균형 잡힌 조각품을 만드는 활동이었다. 전문가 A는 이 수업에 3점 만점을 부여하며 학생들의 탐구적 사고를 높이 평가했지만, 전문가 B는 1점을 주며 "과학 개념을 명시적으로 요구하지 않는 미술 활동에 가깝다"고 비판했다.
두 번째는 5학년 물리과학 수업으로, 단열재를 설계해 물의 온도를 유지하는 실험이었다. 클로드는 1점을 주며 표준 기준에 맞는 명시적 설명이 없다고 지적했고, GPT는 2점을 주며 무난한 평가를 내렸으며, 제미나이는 3점을 부여하며 학생들이 실제 데이터를 분석하고 모델을 수정하는 과정에서 충분한 과학적 사고가 일어난다고 판단했다. 연구팀은 이를 세 가지 AI 인식론으로 정리한다. 클로드는 규칙 중심의 정밀한 평가자, GPT는 중립적이지만 얕은 평가자, 제미나이는 맥락을 통합하는 전체론적 평가자라는 것이다.
AI 채점은 '정답'이 아니라 '다양한 관점'을 제공하는 도구다
이 연구는 AI가 교육 평가에 활용될 때 단일한 정답을 내놓는 방식보다 여러 관점을 함께 보여주는 방식이 훨씬 가치 있다는 점을 시사한다. 인간 전문가들 사이에서도 점수 불일치가 빈번하게 나타났는데, 물리과학 분야에서 두 전문가의 일치도(코헨 카파 약 0.29)가 가장 낮았고, 지구과학(약 0.49)과 생명과학(약 0.47)은 중간 수준의 일치도를 보였다. 이는 "좋은 수업이란 무엇인가"에 대한 판단 자체가 본질적으로 주관적이고 복잡하다는 뜻이다. 따라서 AI를 도입할 때 하나의 모델이 내린 점수를 그대로 신뢰하기보다, 여러 모델의 평가를 비교하며 교사가 스스로 판단하는 데 참고 자료로 활용하는 것이 바람직하다. 연구팀도 AI가 교사의 판단을 대체하는 것이 아니라 교사의 전문적 성찰을 돕는 파트너가 되어야 한다고 강조한다. 앞으로의 AI 교육 평가 시스템은 숫자 하나를 내놓는 채점기가 아니라, 다양한 해석의 근거를 투명하게 제시하는 방향으로 설계되어야 한다는 것이 이 연구의 핵심 메시지다.
FAQ(※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q. AI가 교육 자료를 평가하면 인간 전문가와 얼마나 일치하나요?
A. 이번 연구에 따르면 AI가 부여한 점수에 대한 전문가 평균 동의율은 약 70%이며, AI의 이유 설명에 대한 동의율은 86%로 더 높습니다. AI의 숫자 점수보다 설명이 더 신뢰할 만하다는 뜻입니다.
Q. GPT, 클로드, 제미나이 중 교육 평가에 가장 적합한 AI는 무엇인가요?
A. 전문가와의 일치도 면에서는 제미나이(Gemini)가 점수 87.1%, 이유 설명 92.1%로 가장 높았습니다. 그러나 어떤 모델이 "최선"인지는 교육의 목적과 평가 기준에 따라 다를 수 있으며, 세 모델을 함께 활용해 다양한 관점을 비교하는 방식이 더 효과적입니다.
Q. AI 채점 결과를 교사가 그대로 믿어도 되나요?
A. 아직은 그렇지 않습니다. 같은 수업에 대해 AI마다 점수가 크게 다를 수 있고, 인간 전문가들 사이에서도 의견이 갈리는 경우가 많습니다. AI 평가는 교사의 판단을 보조하는 참고 자료로 활용하되, 최종 판단은 교사가 내리는 것이 바람직합니다.
기사에 인용된 리포트 원문은 arXiv에서 확인할 수 있다.
관련기사
- 오픈AI, 스마트 스피커·안경·조명까지…AI 하드웨어 제국 꿈꾼다2026.02.24
- AI가 인간 고용하는 시대 열렸다…"클로드가 내 상사라면 이상적"2026.02.23
- "AI 비서가 하루종일 일한다"… 오픈AI, 장시간 작동 AI 만드는 법 공개2026.02.19
- 美, 앤트로픽 '미토스5' 빗장 풀어…"100여 곳에 허용"2026.06.27
리포트명: Judging the Judges: Human Validation of Multi-LLM evaluation for High-Quality K–12 Science Instructional Materials
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)





