엔비디아 RTX3090보다 2.1배 빠른 가속기술이 상용화 초기 수준으로 개발됐다.
KAIST는 정명수 전기및전자공학부 교수 연구팀이 그래프 신경망 기반 인공지능(AI) 추론 속도를 획기적으로 높일 수 있는 AI 반도체 기술 ‘오토GNN’을 세계 최초로 개발했다고 5일 밝혔다.
오토 GNN은 엔비디아 고성능 그래픽카드인 'RTX 3090' 대비 속도는 2.1배, 일반 CPU와 비교했을 땐 무려 9배 빠르다. 에너지 소모는 3.3배 줄였다.

RTX 3090은 4K·8K 게이밍과 8K 영상 편집, 대형 3D 렌더링, AI 연산 같은 ‘초고해상도·대용량 데이터’ 작업에 주로 쓴다. 가격도 보통 수백만원 대다.
오토 GNN이 이를 대체할 수 있다는 것이 정명수 교수 설명이다.
정 교수는 "상용화로 바로 가기는 어렵지만, 상용화 초기 단계인 개념증명(POC)을 이번에 한 것"이라며 "상용화로 가기 위해선 삼성미래기술육성사업으로 예산을 지원한 기관 등과 협의를 거쳐야 한다"고 말했다.
이 연구에 정 교수가 창업한 파네시아 연구진이 주도적으로 참여해 사업화로 갈 공산이 클 것으로 전망됐다. 연구에는 파네시아 5명, KAIST 정명수 교수 연구실(카멜) 3명, 중국 베이징대학과 한양대학교, 미국 펜실베이니아 주립대에서 각각 1명씩 참여했다.
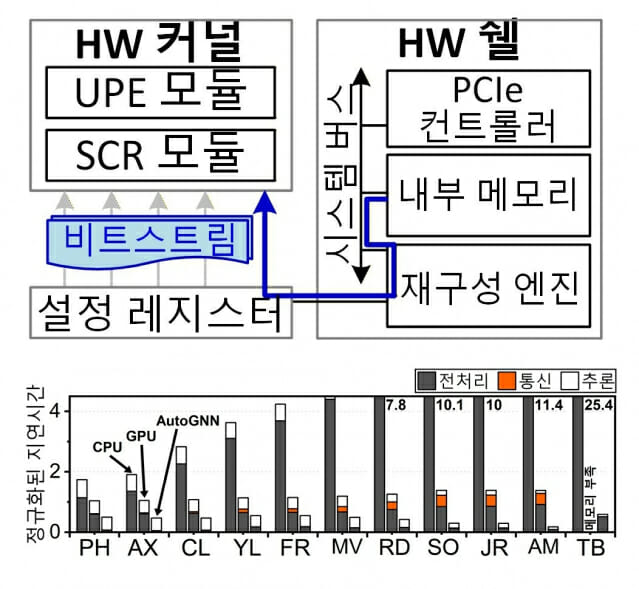
연구팀은 우선 GPU 서비스 지연이 일어나는 주된 원인이 AI 추론 이전 단계인 그래프 전처리 과정에 있음을 밝혀냈다. 이 과정은 전체 계산 시간의 70~90%를 차지하지만, 기존 GPU는 복잡한 관계 구조를 정리하는 연산에 한계가 있어 병목 현상이 상존했다.
이를 해결하기 위해 연구팀은 입력 데이터 구조에 따라 반도체 내부 회로를 실시간으로 바꾸는 FPGA(필드 프로그래머블 게이트 어레이) 기반의 적응형 AI 가속기 기술을 설계했다. 분석해야 할 데이터 연결 방식에 맞춰 반도체가 스스로 가장 효율적인 구조로 바뀌는 방식이다.
연구팀은 필요한 데이터만 골라내는 통합처리요소(UPE) 모듈과 이를 빠르게 정리·집계하는 단일 사이클 리듀서(SCR) 모듈을 반도체 안에 구현했다. 데이터 양이나 형태가 바뀌면 이에 맞춰 최적의 모듈 구성이 자동으로 적용돼, 어떤 상황에서도 안정적인 성능을 유지할 수 있도록 했다.

이 기술은 추천 시스템이나 금융 사기 탐지처럼 복잡한 관계 분석과 빠른 응답이 필요한 AI 서비스에 즉시 적용할 수 있다.
연구팀은 데이터 구조에 따라 스스로 최적화되는 AI 반도체 기술을 확보, 향후 대규모 데이터를 다루는 지능형 서비스 속도와 에너지 효율을 동시에 높일 수 있는 기반이 마련될 것으로 내다봤다.
관련기사
- MS, 차세대 AI 추론칩 '마이아 200' 공개…"아마존보다 3배 빨라"2026.01.27
- 삼성전기·LG이노텍, 패키지기판 호황에도 고민 깊어지는 이유2026.01.22
- "엔비디아 中 AI 가속기 시장 점유율, 66%→8% 떨어질 것"2026.01.18
- SK하이닉스, 내년 HBM4 '램프업' 탄력 운영2025.12.08
정명수 교수는 “불규칙한 데이터 구조를 효과적으로 처리할 수 있는 유연한 하드웨어 시스템을 구현했다는 점에서 의미가 크다”며 “추천 시스템은 물론 금융·보안 등 실시간 분석이 필요한 다양한 AI 분야에 활용될 것”이라고 말했다.
연구는 지난 4일 호주 시드니에서 열린 컴퓨터 아키텍처 분야 국제학술대회인 제32회 ‘IEEE HPC국제 심포지엄'에서 발표됐다. 삼성미래기술육성사업이 지원했다.