






"HBF는 HBM을 제대로 해본 회사만 할 수 있는 기술입니다."
김정호 KAIST 전기전자공학부 교수는 3일 기자간담회에서 차세대 AI 메모리로 주목받는 HBF(고대역폭 플래시)에 대해 이같이 단언했다.
생성형 AI가 추론·멀티모달·장문 컨텍스트 시대로 진화하면서 메모리 용량 한계가 본격화되기 때문이다. HBF를 단순한 낸드플래시의 확장판이 아니라 HBM(고대역폭 메모리)을 통해 축적된 기술력이 전제돼야 가능한 영역으로 본 셈이다.

김 교수의 이 발언은 곧바로 한국 메모리 산업의 경쟁력으로 이어진다. 현재 HBM 시장을 주도하고 있는 삼성전자와 SK하이닉스가 HBF에서도 시장 리더십을 유지할 수 있는 것이다.
김 교수는 "HBM은 메모리 중에서도 가장 어려운 시스템 설계"라며 "HBM을 해봤다는 것은 이미 가장 복잡한 메모리 기술을 경험했다는 의미"라고 말했다. 이어 "이 경험을 가진 나라와 기업은 사실상 한국밖에 없다"며 "HBM을 잘하는 회사가 HBF에서도 유리할 수밖에 없는 구조"라고 강조했다.
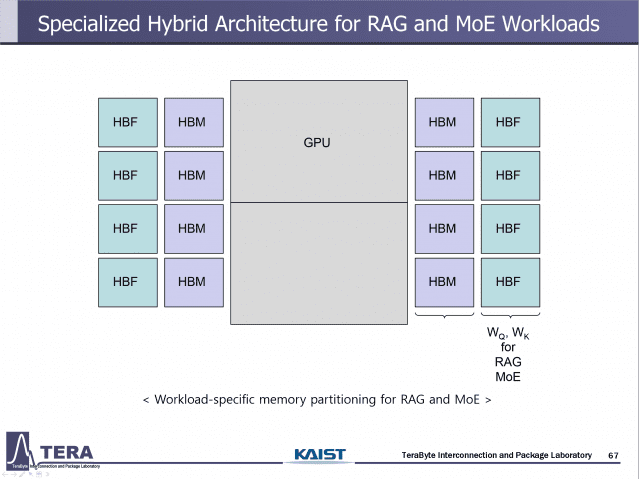
HBF는 낸드플래시 기반의 초대용량 메모리를 GPU 가까이에 배치해, 기존 HBM만으로는 감당하기 어려운 데이터를 처리하기 위한 새로운 메모리 반도체다.
AI 추론 과정에서 폭증하는 KV 캐시, RAG(검색 증강 생성)를 위한 문서·영상·이미지 데이터, 멀티모달 AI의 장기 기억이 대표적인 대상이다.
김 교수는 "HBM이 GPU 옆 책상이라면, HBF는 바로 옆에 붙은 도서관"이라며 "당장 필요한 책은 책상에서 보고, 더 많은 자료는 도서관에서 꺼내오는 구조"라고 설명했다.
"낸드가 아니라 연결이 성능을 결정"
HBF 상용화 과정에서 제기되는 속도 문제는 메모리 제어 로직 설계를 통해 구조적으로 보완할 수 있다는 입장이다. 낸드플래시는 D램에 비해 용량이 큰 대신, 속도가 느리다는 특징을 갖고 있다. 낸드플래시를 집적해 만든 HBF의 속도가 HBM 대비 느린 이유다.
김 교수는 HBF의 성능을 좌우하는 핵심으로 낸드 자체가 아니라, 베이스 다이에 통합된 메모리 제어 로직을 꼽았다.
이 로직은 전통적인 SSD 컨트롤러와는 다르다. SSD처럼 낸드 옆에서 읽기·쓰기만 담당하는 방식이 아니라, GPU와 메모리 사이에 위치한 베이스 다이가 데이터 흐름을 직접 제어하는 구조다. 페이지 단위 병렬 읽기, 대량 데이터 묶음 전송, 버퍼링과 스케줄링을 통해 낸드의 물리적 한계를 구조적으로 보완한다는 설명이다.
김 교수는 "낸드는 느리지만, 한 번에 많이 읽어서 보내면 된다"며 "GPU와 연결되는 대역폭과 지연은 낸드 셀 자체가 아니라 베이스 다이와 인터포저, 인터커넥트 설계가 결정한다"고 말했다. 실제 시스템 기준으로는 HBM 대비 20~30% 수준의 성능 손실로 관리 가능하다는 게 그의 판단이다.
HBF는 단독 메모리가 아니라 HBM과 결합된 계층형 구조로 진화할 가능성이 크다. 속도는 HBM, 대용량 데이터는 HBF가 맡는 구조다.
상용화 시점은 2027년 말에서 2028년으로 예상된다. 초기에는 AI 추론용으로 채택되며, 이후 HBM과 HBF를 결합한 메모리 구조가 표준으로 자리 잡을 가능성이 크다는 분석이다. 2038년에는 HBF의 비중이 HBM보다 커질 것으로 내다봤다.
관련기사
- 파두 "데이터센터용 칩 전문 기업 도약...CXL·HBF는 속도 조절2025.12.04
- "삼성전자·SK하이닉스·샌디스크, HBF 준비…2030년 뜰 것"2025.11.12
- SK하이닉스 "이제 메모리는 조합의 시대…커스텀 HBM·HBF에 기회"2025.11.04
- SSD-프로세서 직결 난항…HBF가 돌파구 될까2025.08.26
김 교수는 기술 완성도보다 누가 먼저 실제 AI 서비스에 채택하느냐가 관건이라고 강조했다. HBF가 단순한 부품 성능 경쟁이 아니라, 실제 AI 서비스 환경에서 효과가 입증돼야 확산될 수 있는 구조적 기술이기 때문이다. 한 곳에서라도 HBF를 적용해 추론 속도나 동시 처리량 개선이 확인되면, 해당 사례가 곧바로 시장의 기준점이 된다는 설명이다.
그는 "기술 자체보다는 누가 먼저 쓰느냐가 더 중요하다"며 "어떤 서비스에 채택되느냐가 시장을 결정할 것"이라고 말했다.





