






국내 연구진이 초대형 인공지능(AI) 학습 과정에서 고질적인 문제인 ‘메모리 부족’을 근본적으로 해결할 수 있는 핵심기술이 개발됐다.
차세대 이더넷 기반으로 메모리 확장이 가능한 기술이어서 향후 AI·빅데이터 산업 전반의 인프라 혁신을 이끌 것으로 기대됐다.
한국전자통신연구원(ETRI)은 초대형 AI 학습에서 가장 큰 문제로 꼽히는 GPU 메모리 한계와 데이터 병목 현상을 해결하는 새로운 메모리 기술 ‘옴니익스텐드(OmniXtend)’를 개발했다고 8일 밝혔다.

최근 초대형 AI 모델과 고성능 컴퓨팅(HPC) 수요가 급격히 증가하면서, 처리해야 할 데이터 규모도 폭발적으로 커지고 있다. 그러나 GPU 성능이 아무리 향상되더라도, 메모리 용량이 충분하지 않으면 연산 효율이 급격히 떨어지는 ‘메모리 장벽(memory wall)’이 발생한다.
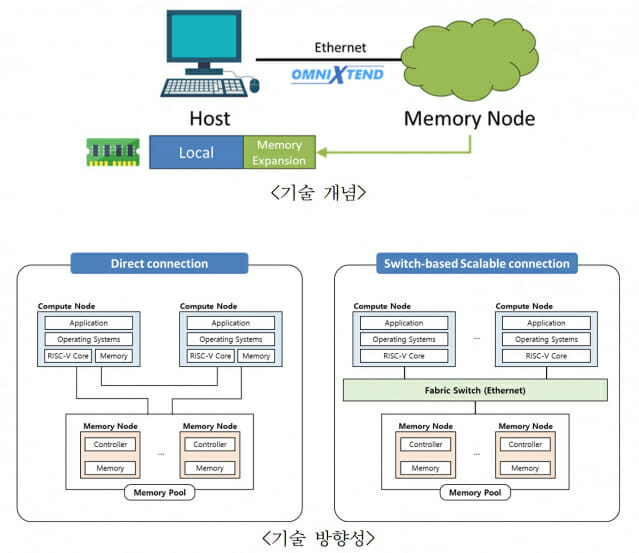
'옴니익스텐드'는 표준 네트워크 기술인 이더넷(Ethernet)을 활용해 여러 서버와 가속기(Device) 각각의 메모리를 하나의 대용량 메모리처럼 공유하는 기술이다. 각 장비에 개별적으로 존재하던 메모리를 네트워크 전반으로 확장해, AI 학습에 필요한 메모리를 원하는 만큼 유연하게 확보할 수 있는 구조다.
연구팀은 데이터 이동 지연을 최소화, AI 학습 속도가 향상됐다고 설명했다. 서버 교체 없이 메모리를 확장할 수 있어 데이터센터 구축·운영 비용 절감 효과도 기대된다.
기존 고속 직렬 통신 인터페이스(PCIe) 기반 구조는 장비 간 연결 거리와 시스템 확장에 한계가 있었다. 반면 옴니익스텐드는 이더넷 스위치를 활용해 물리적으로 떨어진 다수 장비를 하나의 메모리 풀로 묶을 수 있다. 초대규모 AI 환경에 적합한 고확장성 시스템 구조인 셈이다.
연구팀은 또 ▲현장 프로그래밍 가능 게이트 어레이(FPGA) 기반 메모리 확장 노드 ▲이더넷 기반 메모리 전송 엔진 등과 같은 핵심 요소기술을 개발해 시스템의 안정적 동작도 검증했다.
최근 실시한 시연에서는 이더넷 환경에서 여러 장비가 공유 메모리 풀(memory pool)을 구성하고 실시간 서로의 메모리에 접근하는 모습을 성공적으로 보여줬다.
또한 대규모 언어 모델(LLM)을 활용한 연산 부하 테스트를 통해 옴니익스텐드 구조가 실제 AI 학습 환경에서도 성능 향상에 기여한다는 사실도 확인했다. 실험 결과, 메모리 용량이 부족한 환경에서는 LLM 추론 성능이 크게 저하된 반면, 이더넷 기반으로 메모리를 확장한 경우 성능이 2배 이상 회복됐다.
ETRI는 향후 데이터센터 하드웨어·소프트웨어 기업을 중심으로 기술이전을 추진, 상용화를 도모할 계획이다. 특히 AI 학습·추론용 서버와 메모리 확장 장치, 네트워크 스위치 등에 적용해 차세대 AI 인프라 시장에서 실질적인 산업적 성과 창출을 추진할 방침이다.
차승준 책임연구원은 "차량·선박 등 고신뢰 임베디드 시스템의 대용량 메모리 연결망으로 확장하고, NPU·GPU·CPU 등 이종 가속기 간 메모리 공유 구조를 고도화하기 위한 후속 연구도 함께 추진할 예정"이라고 덧붙였다.
관련기사
- HPE "이더넷 기반 AI 패브릭, 인피니밴드 대안 넘는다"2025.12.11
- SK하이닉스, 엔비디아와 '초고성능 AI 낸드' 개발 협력…"내년 말 샘플 제조"2025.12.10
- KT, '차세대 연구시험망' 백본 용량 7Tbps로 고도화2025.12.01
- AI 시대, 연필과 지우개로 치르는 수능2025.11.13
김강호 초성능컴퓨팅연구본부장은 “향후 새로운 과제기획을 통해 신경망처리장치(NPU)와 가속기 중심의 메모리 인터커넥트 기술 연구를 본격 확대할 계획”이라며, “글로벌 AI·반도체 기업의 차세대 시스템에 본 기술이 적용될 수 있도록 기술 고도화와 국제 협력을 지속하겠다”고 말했다.
연구는 과학기술정보통신부와 정보통신기획평가원(IITP)이 지원하는 ‘SW컴퓨팅산업원천기술개발사업’의‘메모리 중심 차세대 컴퓨팅 시스템 구조 연구’과제의 일환으로 수행됐다.





