






[샌디에이고(미국)=권봉석 기자] 퀄컴이 지난 해 출시한 스냅드래곤 X 시리즈 시스템반도체(SoC)는 45 TOPS(1초당 1조번 연산)급 신경망처리장치(NPU)로 인텔과 AMD 등 x86 프로세서 기반 SoC 대비 우위를 차지했다.
내년 상반기 중 출시할 스냅드래곤 X2 엘리트/엘리트 익스트림에는 전 세대 대비 두 배 가까운 80 TOPS급 NPU를 탑재할 예정이다. 주요 연산을 저전력 NPU로 처리해 배터리 지속시간이 중요한 노트북 분야에서 경쟁력을 확보하겠다는 것이다.

12일(이하 현지시간) 오전 미국 캘리포니아 주 샌디에이고 내 '스냅드래곤 X 엘리트 딥다이브' 행사에서 루시안 코드레스쿠 퀄컴 기술부사장은 "스냅드래곤 X2 시리즈의 헥사곤 NPU는 상시 구동 AI를 겨냥해 전 세대 대비 78% 성능을 향상시켰다"고 강조했다.
이어 "AI가 운영체제와 사용자 경험 전반을 바꾸고 있는 현 시점에서, 지속적 온디바이스 AI 실행과 다중 모델 동시 활용을 위해서는 극단적인 에너지 효율이 필수이며 헥사곤 NPU는 이를 충족한다"고 덧붙였다.
헥사곤 NPU, DSP에서 다양한 연산 처리용으로 진화
루시안 코드레스쿠 부사장은 헥사곤 제품개발 팀이 처음 구성된 2004년부터 아키텍처 팀을 이끌어왔다. 당시 개발된 QDSP6는 오디오와 멀티미디어 처리 효율 개선에 주력했고, 스마트폰 카메라의 영상처리 중요성이 커진 2014년부터 벡터 연산이 추가됐다.

2019년에는 단순한 DSP에서 벗어나 뉴럴 네트워크, 머신러닝 가속을 위해 행렬 연산을 추가한 헥사곤 NPU로 개념을 확장했다.
루시안 코드레스쿠 부사장은 "매년 새로운 NPU를 설계하고 스마트폰, PC, 오토모티브, IoT 등 다양한 제품에 이를 탑제한다. 제품마다 필요한 기능과 규모는 다르지만 기본적인 코어 기술은 공통"이라고 설명했다.
"NPU, 행렬 연산만 강화하는 것이 능사 아냐"
헥사곤 NPU는 AI에 필요한 각종 연산을 조율하고 제어하는 '스칼라' 코어, SIMD(단일 명령어/다중데이터) 명령어를 주로 처리하는 '벡터' 코어, AI 연산의 주를 이루는 행렬 관련 연산을 주로 처리하는 '매트릭스' 코어 등 3개 주요 부분으로 구성됐다.
루시안 코드레스쿠 부사장은 "오픈소스와 자체 모델, 고객사 등이 만든 다양한 AI 모델을 이용해 테스트한 결과 NPU는 단순히 행렬 연산만 잘 처리하는 것이 능사가 아니다"라고 설명했다.

그는 "어떤 모델은 행렬 연산에서, 어떤 모델은 벡터 연산에서, 어떤 모델은 스칼라 코어나 메모리, 제어 계층에서 병목 현상을 일으킨다. NPU 시스템 전반의 밸런스를 맞추지 않으면 아무리 행렬 연산만 강화해도 속도 향상은 제한적일 것"이라고 말했다.
스칼라 엔진, 멀티스레딩으로 한 클록당 32개 명령어 처리
스냅드래곤 X2 엘리트/엘리트 익스트림에 내장된 헥사곤 NPU는 퀄컴 자체 기준으로 6세대 제품에 해당한다.
먼저 AI 연산을 조율하는 스칼라 엔진을 크게 강화했다. 코어는 6코어지만 멀티스레딩 방식으로 내부에서 최대 12 스레드를 처리하도록 처리했다.

한 클록(사이클) 당 처리할 수 있는 명령어는 최대 32개 수준이다. 코어는 32비트로 작동하지만 32비트의 한계를 넘어서는 큰 AI 모델을 처리할 수 있도록 메모리 주소는 64비트로 처리해 효율성을 높였다. 이런 개선 결과 전 세대 대비 처리량은 143%, 대역폭은 127% 향상됐다.
벡터 엔진은 최대 1024비트를 처리할 수 있는 레지스터를 탑재했고 FP8(실수, 8비트)와 FP16(실수, 16비트) 대비 연산량을 경감하며 비슷한 결과를 낼 수 있는 BF16 연데이터타입도 지원한다.

이를 이용해 일반적 머신러닝 연산·리사이즈·소프트맥스 등 광범위한 연산을 처리한다. 벡터 엔진의 연산 속도는 전 세대 대비 1.43배 늘어났다.
매트릭스 엔진, 2비트 가중치 처리 기능 추가
행렬 연산을 처리하는 매트릭스 엔진은 2비트로 양자화된 거대언어모델(LLM) 처리 능력을 더했고 FP8과 BF16 자료형을 처리할 수 있다.
특히 행렬 연산 처리와 활성 함수 연산까지 처리할 수 있도록 전용 파이프라인을 더해 여러 번 데이터를 옮길 필요 없이 한 번에 데이터를 처리한다.

또 매트릭스 엔진의 전압과 작동 클록을 분리해서 응용프로그램이나 AI 모델의 특성에 맞게 성능과 전력을 세밀하게 조절할 수 있다. 이런 처리 결과 매트릭스 엔진의 처리량은 전 세대 대비 78% 성능을 높였다.
새 NPU, 같은 전력에서 전 세대 대비 최대 1.6배 향상
새로 개발된 헥사곤 NPU는 스냅드래곤 X 엘리트 대비 같은 전력에서 최대 1.6배 더 높은 성능을 낸다. AI·컴퓨터 비전 벤치마크에서는 5.7배, 긱벤치 AI에서는 8만8천점이 넘는 점수를 냈다.

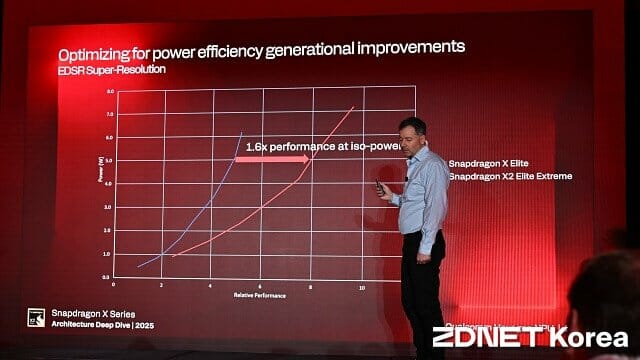
루시안 코드레스쿠 부사장은 "자체 실험 결과 칩 면적과 메모리 대역폭이 고정돼 있을 때 FP16, FP8, INT4 등 서로 다른 데이터 타입을 이용할 때, 정밀도를 높이면 전력 소모가 커진다는 결과를 얻었다"고 설명했다.

이어 "이 때문에 업계 전체가 보다 정밀도를 낮추는 방향으로 움직이고 있으며 허용 가능한 정확도를 유지하는 범위에서 비트 수를 최대한 줄이는 것이 에너지 효율 상 가장 큰 이득을 준다는 결론을 얻었다"고 설명했다.
관련기사
- 퀄컴, 차세대 산업용 프로세서 '드래곤윙 IQ-X' 공개2025.11.13
- 삼성 '엑시노스 2600' 갤S26에 탑재..."퀄컴칩과 병행"2025.11.11
- 퀄컴, 독자 CPU·NPU로 AI 추론 인프라 도전장...인텔과 맞붙나2025.10.28
- 퀄컴 차세대 AI PC 프로세서, 컴퓨팅·AI 성능서 경쟁사 '압도'2025.09.29
스냅드래곤 X2 모든 제품군에 80 TOPS급 NPU 탑재
퀄컴은 스냅드래곤 X2 엘리트/엘리트 익스트림 뿐만 아니라 향후 출시될 윈도 PC용 SoC에 동일한 NPU를 탑재할 예정이다. 보급형 PC나 고성능 PC 모두 동일한 AI 처리 성능을 갖추게 된다.

루시안 코드레스쿠 부사장은 "80 TOPS급 헥사곤 NPU는 성능 측면에서 큰 도약을 이뤘다. 이는 스칼라, 벡터, 매트릭스 등 전반을 균형있게 재설계한 결과물이다. 이를 바탕으로 온디바이스 AI가 항상 켜진 PC 시대를 뒷받침할 중심이 될 것"이라고 밝혔다.





