






챗GPT 같은 AI가 덧셈 문제는 거의 완벽하게 풀지만, 뺄셈 특히 답이 음수로 나오는 계산에서는 이상한 실수를 반복한다는 연구 결과가 나왔다. 독일 자를란트대학교와 미국 브라운대학교 등 공동 연구팀은 8개의 주요 AI 모델을 조사한 연구 논문을 보면, AI가 답의 숫자는 맞게 계산하면서도 앞에 마이너스 부호를 빼먹는 독특한 오류를 가지고 있었다.
같은 난이도인데 뺄셈만 30~50점 낮아
연구팀은 구글의 Gemma-2, 중국의 Qwen2, 메타의 Llama-3, AI2의 OLMo-2 등 4개 모델 패밀리의 8가지 AI를 대상으로 덧셈과 뺄셈 실력을 비교했다. 각 AI가 한 번에 인식할 수 있는 숫자 범위 안에서 균형 잡힌 문제를 만들어 테스트했고, 같은 질문을 5가지 방식으로 바꿔가며 물어봤다.
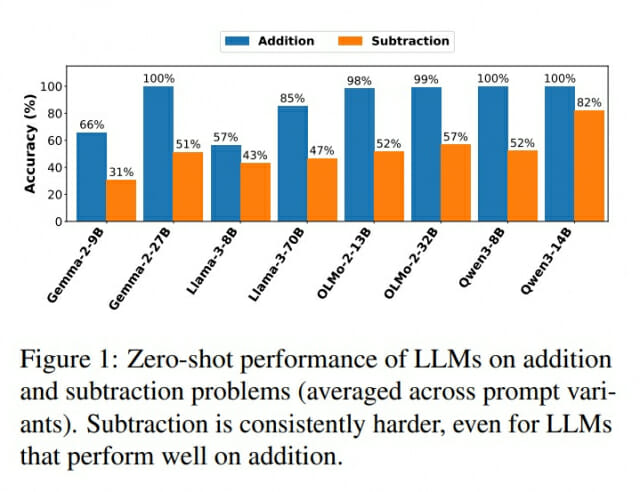
결과는 충격적이었다. Qwen2-8B 모델은 덧셈에서 거의 100점을 받았지만 뺄셈에서는 52점에 그쳤다. OLMo-2-32B 모델도 덧셈 99점, 뺄셈 57점이었다. 여러 AI에서 뺄셈 점수가 덧셈보다 30~50점 낮았다. 뺄셈은 순서를 바꾸면 답이 달라지는 비가환 연산이다. 또한 뺄셈은 자릿수를 추적하는 차입 과정이 중요한데, 처음부터 훈련된 트랜스포머 모델이 이런 긴 시퀀스의 자릿수 추적에서 어려움을 겪는다는 선행 연구가 있다.
답이 음수로 나올 때만 망가진다
연구팀이 문제를 a>b(큰 수에서 작은 수 빼기)와 a<b(작은 수에서 큰 수 빼기) 두 그룹으로 나눠서 분석했더니 극명한 차이가 드러났다. 거의 모든 AI가 a>b일 때는 성공했지만, a<b일 때는 정확도가 급락했다. 예를 들어 Qwen2-8B, Gemma-2-27B, Llama-3.1-70B 모델은 답이 양수일 때는 거의 완벽했지만, 답이 음수일 때는 5% 미만의 정확도를 보였다. 혹시 'a-b' 형식 때문에 헷갈리는 건지 확인하려고 '-b+a' 형식으로도 물어봤는데 결과는 똑같았다. 이는 AI의 실패가 뺄셈 연산 자체가 아니라 음수 정수를 최종 답으로 만들어내는 데 있어서의 체계적 어려움임을 확인시켰다.
숫자는 맞는데 마이너스 부호만 빠뜨려
정확히 어디서 실수하는지 알아보기 위해 연구팀은 마이너스 부호를 무시하고 숫자 크기만 맞는지 채점해봤다. 그러자 점수가 극적으로 상승했다. OLMo-2-13B 모델은 완전히 맞은 답이 4%였는데, 부호를 빼고 보니 96%가 맞았다. Llama-3-70B도 0.2%에서 49%로, Qwen2-8B는 4%에서 37%로 올랐다. '-b+a' 형식에서도 동일한 패턴이 관찰됐다. 이는 AI가 뺄셈의 크기는 정확히 계산하면서도 마이너스 부호를 체계적으로 생략한다는 것을 의미한다. 연구팀은 이것이 단순한 실수가 아니라 모델의 근본적인 한계라고 지적했다.
AI는 답을 알면서도 못 쓴다
가장 흥미로운 발견은 AI 내부를 들여다본 실험에서 나왔다. 연구팀은 Gemma-2 9B, Llama-3.1-8B, Qwen2-8B 세 모델의 내부 신호를 읽어내는 간단한 판별 장치를 만들었다. 이 장치는 AI가 계산 과정에서 만들어내는 신호 패턴을 보고 "이 답이 양수인지 음수인지" 맞춰보는 역할을 했다. 놀랍게도 이 판별 장치는 거의 완벽하게 맞췄다. Gemma-2 9B와 Qwen2-8B는 100%, Llama-3.1-8B는 99% 이상을 기록했다. 같은 실험을 5번 반복했는데도 결과가 거의 똑같이 나왔다.
이 말은 AI가 답을 쓸 때는 마이너스 부호를 빼먹지만, 속으로는 답이 음수인지 양수인지 정확히 알고 있다는 뜻이다. AI 안에서는 올바른 정보를 갖고 있지만, 이를 글자로 바꿔서 내보낼 때 마이너스 부호가 사라지는 것이다. AI가 '아는 것'과 '말하는 것' 사이에 단절이 생기는 셈이다.
예시를 보여줘도 효과 제한적
이 문제를 해결하려고 연구팀은 두 가지 방법을 시도했다. 첫 번째는 AI에게 문제를 풀기 전에 미리 푼 예제를 보여주는 것이었다. 3개, 5개, 10개씩 예시를 보여주며 테스트했다. 결과는 들쭉날쭉했다. Llama-3.1-8B는 예시 없이 8.1%였던 정확도가 예시 5개를 보여주자 31.5%로 올랐다. 크지는 않지만 의미 있는 개선이었다. Qwen2-14B도 처음에는 나아졌지만 예시 3개 이후로는 더 이상 좋아지지 않았다. 반면 Gemma-2-27B나 Llama-3.1-70B 같은 큰 모델들은 결과가 불안정하고 일관성이 없었다.
거의 모든 AI에서 마이너스 부호를 무시하고 채점하면 90% 이상이 맞았다. 이는 AI가 숫자 크기는 제대로 계산하지만 부호만 자꾸 빼먹는다는 뜻이다. 예시를 보여주는 방법은 일반 AI에서 실수를 어느 정도 줄이지만, 전체적으로 효과가 크지 않고 들쭉날쭉하다는 결론이다.
특별 훈련받은 AI는 거의 완벽
두 번째 방법은 특별 훈련을 받은 AI를 테스트하는 것이었다. '인스트럭션 튜닝'이라고 불리는 이 특별 훈련은 AI가 사람의 지시를 더 잘 따르도록 추가로 가르치는 과정이다. 이렇게 훈련받은 AI들은 MATH와 GSM8k 같은 수학 시험에서 좋은 성적을 낸다고 알려져 있다. 결과는 놀라웠다. 거의 모든 특별 훈련 AI가 90% 이상의 정확도를 기록했고, Gemma-2-9B, Gemma-2-27B, Qwen2-8B, Qwen2-14B는 100%를 받았다. 일반 버전에서 완전히 실패했던 모델들도 특별 훈련 후에는 성능이 크게 향상됐다.
연구팀은 이런 개선이 특별 훈련 과정에서 나온다고 보았다. 실제로 OLMo-2 모델의 훈련 자료를 조사해보니, MATH 문제집, GSM8k 문제집, Tülu 3 데이터가 포함되어 있었다. 이 모든 자료에는 작은 수에서 큰 수를 빼는 문제(답이 음수로 나오는 경우)가 들어있었다. OLMo-2가 특별 훈련 중에 이런 문제들을 학습해서 성능이 좋아진 것으로 추측된다.
여러 자리 숫자에서도 똑같은 문제
연구팀은 한 자리 숫자뿐 아니라 여러 자리로 이루어진 긴 숫자에서도 실험했다. AI는 긴 숫자를 여러 조각으로 나눠서 인식하는데, 최대 3조각까지 나뉘는 숫자를 테스트했다. 긴 숫자를 다룰 때는 덧셈 성적도 떨어졌지만, 뺄셈이 더 어렵다는 경향은 그대로였다. Gemma-2-27B는 긴 숫자 덧셈에서 99%를 받았지만 뺄셈에서는 51%였다. Qwen2-8B와 Qwen2-14B도 덧셈 99%, 뺄셈 49%로 비슷한 차이를 보였다.
큰 수에서 작은 수를 뺄 때와 작은 수에서 큰 수를 뺄 때의 차이도 긴 숫자에서 똑같이 나타났다. Qwen2-14B는 답이 양수일 때(a>b) 100%를 기록했지만, 답이 음수일 때(a<b)는 38%로 뚝 떨어졌다. 마이너스 부호를 빼먹는 경향도 긴 숫자에서 똑같이 관찰됐다. OLMo-2-32B는 답이 음수인 문제에서 25%만 맞혔지만, 부호를 빼고 채점하니 71%가 맞았다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. AI가 덧셈은 잘하는데 뺄셈은 못하는 이유가 뭔가요?
A. 뺄셈은 순서를 바꾸면 답이 달라집니다(3-5와 5-3은 다름). 또한 뺄셈할 때는 자릿수를 빌려오는 계산이 중요한데, 이전 연구들에 따르면 AI가 긴 숫자의 자릿수를 추적하는 데 어려움을 겪는다고 합니다. 특히 답이 음수로 나올 때 AI는 숫자는 맞게 계산하면서도 앞에 마이너스 부호를 자꾸 빼먹습니다.
Q2. AI가 마이너스 부호를 빼먹는 이유는 뭔가요?
A. 연구팀이 AI 내부를 분석한 결과, AI는 속으로 답이 음수인지 양수인지 정확히 알고 있었습니다. 하지만 이 정보를 글자로 바꿔서 내보낼 때 마이너스 부호가 사라집니다. AI가 '아는 것'과 '말하는 것' 사이에 단절이 있는 셈입니다.
Q3. 이 문제를 해결할 방법이 있나요?
관련기사
- AI 모델끼리 '생각' 직접 주고 받는다…텍스트 없이 소통하는 신기술 등장2025.11.05
- 깐부치킨, 'AI 깐부' 세트 출시…물 들어올 때 노 젓는다2025.11.05
- 챗GPT, 이제 약 이름 안 알려준다…의료·법률·재정 조언 서비스 일괄 차단2025.11.03
- 마이크론, 메모리 장기계약 비중 확대...삼성·SK도 성장 구도 바뀐다2026.06.25
A. 특별 훈련이 가장 효과적입니다. 사람의 지시를 더 잘 따르도록 추가로 가르치는 '인스트럭션 튜닝'을 받은 AI는 90% 이상, 일부는 100%의 정확도를 보였습니다. 반면 문제 풀기 전에 예시를 보여주는 방법은 효과가 작고 들쭉날쭉했습니다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)





