






AGI(범용 인공지능)가 정확히 무엇인지에 대한 명확한 정의가 없어, AI 기술이 얼마나 발전했는지 제대로 평가하기 어렵다는 문제가 있었다. 미국 AI 안전센터(Center for AI Safety), UC버클리, MIT, 스탠퍼드대학 등 28개 기관의 연구자 29명이 참여한 이번 연구는 인간의 인지 능력을 기반으로 AGI를 측정하는 구체적인 방법을 제시했다. 해당 연구 논문에 따르면, 평가 결과 100점 만점 기준으로 GPT-4는 27점, GPT-5는 57점을 받았다.
교육받은 성인의 능력을 기준으로 AGI를 정의하다
연구팀은 AGI를 "교육받은 성인의 인지 능력 범위와 숙련도를 충족하거나 넘어서는 AI"로 정의했다. 여기서 중요한 것은 단순히 한 가지 분야를 잘하는 것이 아니라, 인간처럼 다양한 분야에서 능력을 발휘할 수 있는 '폭넓음'과 각 분야에서의 '깊이' 모두를 갖춰야 한다는 점이다.
이를 실제로 측정하기 위해 연구팀은 캐텔-혼-캐롤 이론(Cattell-Horn-Carroll theory, CHC)을 활용했다. 이 이론은 100년 넘게 다양한 인지 능력 테스트를 분석해 만들어진 것으로, 인간 지능 연구에서 가장 신뢰받는 모델이다. CHC 이론은 인간의 지능을 추론, 기억, 지각 등 10가지 핵심 영역으로 나눈다.
연구팀의 핵심 아이디어는 간단하다. 사람을 테스트할 때 사용하는 인지 능력 테스트를 AI에게도 똑같이 적용하는 것이다. 이를 통해 막연했던 '지능'이라는 개념을 0점부터 100점까지의 구체적인 점수로 바꿀 수 있다. 100점을 받으면 AGI에 도달했다고 볼 수 있다.
GPT-5는 57점, GPT-4는 27점... 영역별 편차 커
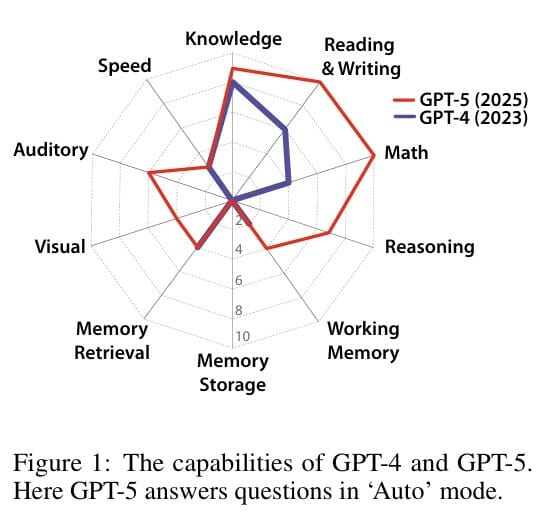
실제로 이 평가 방법을 적용해 보니, 현재 AI는 영역별로 성적 차이가 매우 큰 '들쭉날쭉한' 모습을 보였다. 많은 학습 데이터를 활용하는 영역, 즉 일반 상식이나 읽기 쓰기, 수학 같은 분야에서는 좋은 성적을 냈지만, 기본적인 인지 능력에서는 심각한 문제를 드러냈다.
GPT-4는 일반 지식에서 8점, 읽기와 쓰기에서 6점, 수학에서 4점을 받았다. 하지만 현장에서 즉석으로 문제를 해결하는 추론 능력은 0점, 새로운 정보를 장기적으로 기억하는 능력도 0점이었다. 소리를 처리하는 능력과 이미지를 이해하는 능력도 0점으로, 텍스트 이외의 영역에서는 거의 작동하지 못했다. 총점은 100점 만점에 27점이었다.
GPT-5는 상당히 발전한 모습을 보였다. 일반 지식 9점, 읽기와 쓰기 10점, 수학 10점으로 기본 영역에서 개선됐고, 즉석 추론도 7점으로 향상됐다. 이미지 처리는 4점, 소리 처리는 6점으로 텍스트 이외의 능력도 생겼다. 하지만 새로운 정보를 장기적으로 기억하는 능력은 여전히 0점으로, 심각한 약점을 보였다. 총점은 57점으로, 빠르게 발전하고 있지만 AGI까지는 아직 갈 길이 멀다는 것을 보여준다.
장기 기억 능력 0점... 가장 큰 문제점
영역별 성적 차이는 AGI로 가는 길에 어떤 장애물이 있는지 명확히 보여준다. 가장 큰 문제는 장기 기억 능력이다. GPT-4와 GPT-5 모두 이 영역에서 거의 0점에 가까웠다. 계속해서 새로운 것을 배우는 능력이 없으면, AI는 마치 '기억상실증'에 걸린 것처럼 대화할 때마다 처음부터 다시 배워야 한다. 이는 AI의 실용성을 크게 떨어뜨린다.
이미지를 보고 논리적으로 추론하는 능력의 부족도 문제다. 이는 AI가 복잡한 컴퓨터 환경에서 작업하는 것을 어렵게 만든다. 작업 기억(짧은 시간 동안 정보를 유지하는 능력)도 부족하다. 현재 모델들은 엄청나게 긴 문맥창(context window)으로 이를 보완하려 하지만, 이는 비효율적이고 비용이 많이 들며, 며칠이나 몇 주에 걸친 작업에는 적합하지 않다.
연구팀은 이러한 '능력 왜곡'이 AI가 실제보다 더 뛰어난 것처럼 보이게 할 수 있다고 경고한다. 예를 들어, AI가 정확한 정보를 기억해내지 못하는 문제(환각 또는 헛소리)는 종종 외부 검색 도구를 연결해서 해결한다. 하지만 검색에 의존하는 것은 두 가지 근본적인 약점을 감춘다. 첫째, AI가 학습한 방대한 지식을 제대로 꺼내 쓰지 못한다는 것이다. 둘째, 더 중요하게는 사용자와의 대화 내용이나 맥락을 장기적으로 저장하고 업데이트할 수 있는 진짜 기억 시스템이 없다는 것이다.
가장 약한 부품이 전체 성능을 결정한다
연구팀은 지능을 자동차 엔진에 비유한다. 전체 지능은 엔진의 "마력"과 같고, 어떤 엔진이든 가장 약한 부품에 의해 성능이 제한된다. 현재 AI "엔진"의 여러 중요한 부품에 심각한 결함이 있어서, 다른 부분이 아무리 좋아도 전체 성능이 크게 제한된다는 것이다.
연구팀이 지능을 10가지 영역으로 나눴지만, 이 능력들은 서로 깊이 연결되어 있다는 점을 이해하는 것이 중요하다. 복잡한 문제를 해결할 때는 한 가지 능력만 사용하는 경우가 거의 없다. 예를 들어, 어려운 수학 문제를 풀려면 수학 지식과 논리적 추론 능력이 모두 필요하다. 다른 사람의 마음을 이해하는 문제는 논리적 추론뿐 아니라 일반 상식도 필요하다. 영화를 이해하려면 소리를 듣고, 영상을 보고, 그 정보를 머릿속에 유지하는 능력이 모두 통합되어야 한다.
평가 프레임워크의 10가지 핵심 영역은 다음과 같다. 일반 지식(10점), 읽기와 쓰기(10점), 수학(10점), 즉석 추론(10점), 작업 기억(10점), 장기 기억 저장(10점), 장기 기억 검색(10점), 시각 처리(10점), 청각 처리(10점), 처리 속도(10점)다. 각 영역을 동등하게 10점씩 배정해서 다양한 능력을 골고루 평가하도록 했다.
우리가 쓰는 챗GPT, 실제로는 이런 수준이었다
이번 평가 결과는 일반 사용자들이 AI를 쓰면서 느꼈던 불편함이 왜 생기는지 명확히 설명해준다. 가장 대표적인 것이 "이전 대화를 기억 못하는 문제"다. 챗GPT를 쓰다 보면 며칠 전에 나눴던 대화 내용을 다시 설명해야 하는 경우가 많다. 심지어 같은 대화 안에서도 앞에서 한 말을 잊어버리는 듯한 답변을 할 때가 있다. 이것이 바로 '장기 기억 저장' 능력 0점의 실제 모습이다. AI는 대화 내용을 진짜로 '기억'하는 게 아니라, 매번 대화 기록을 다시 읽는 방식으로 작동한다.
"가끔 엉뚱하고 그럴듯한 거짓말을 한다"는 불만도 이번 평가로 설명된다. '장기 기억 검색' 영역에서 환각(hallucination) 문제가 지적됐는데, AI가 학습한 방대한 정보 중에서 정확한 것을 찾아내지 못하고 그럴듯하지만 틀린 정보를 만들어내는 현상이다. GPT-4와 GPT-5 모두 이 문제에서 0점을 받았다. 또 "복잡한 이미지는 제대로 이해 못한다"는 지적도 있다. 사진 속 사람 수를 세거나, 미로 찾기 같은 간단해 보이는 시각 문제도 자주 틀린다. 이는 '시각 처리' 영역에서 GPT-5가 겨우 4점을 받은 이유를 보여준다. 사진을 '본다'는 것과 '이해한다'는 것은 전혀 다른 문제다.
그렇다면 앞으로 2-3년 안에 어떤 변화를 기대할 수 있을까? GPT-4에서 GPT-5로 넘어오면서 27점에서 57점으로 2배 이상 점프한 것을 보면, 발전 속도는 빠르다. 특히 이미지와 소리를 처리하는 능력이 0점에서 4-6점으로 생긴 것이 큰 변화다. 하지만 장기 기억 능력은 여전히 0점이다. 이는 단순히 모델을 크게 만들거나 데이터를 더 많이 학습시킨다고 해결되는 문제가 아니다. AI가 경험을 통해 계속 배우고 그것을 저장하는, 근본적으로 새로운 구조가 필요하다는 의미다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q: AGI 점수 100점은 무엇을 의미하나요?
A: AGI 점수 100점은 AI가 교육받은 성인의 인지 능력을 모든 영역에서 충족하거나 넘어선다는 뜻입니다. 단순히 한두 가지를 잘하는 것이 아니라, 추론, 기억, 언어, 수학 등 인간 지능의 특징인 다양한 능력을 폭넓고 깊이 있게 갖췄다는 의미입니다.
Q: 현재 AI의 가장 큰 약점은 무엇인가요?
A: 새로운 정보를 장기적으로 기억하는 능력입니다. GPT-4와 GPT-5 모두 이 영역에서 거의 0점에 가까운 점수를 받았습니다. AI가 계속해서 새로운 것을 배우고 저장할 수 없어서, 대화할 때마다 맥락을 처음부터 다시 배워야 합니다. 이런 "기억상실증"은 AI의 실용성을 크게 떨어뜨립니다.
Q: 이 평가 방법은 기존 AI 테스트와 어떻게 다른가요?
관련기사
- 생성형AI 투자 기업 95%가 수익 제로…이유 살펴봤더니2025.10.27
- "혀 사진만 올려도 체질 분석"...챗GPT가 의학 상담도 해준다2025.10.23
- 챗GPT와 클로드가 1936년 살인사건을 다르게 기억하는 충격적 이유2025.10.23
- 삼성전자, 상반기에만 146조원 벌었다…하반기 성장 지속 전망2026.07.30
A: 기존 AI 테스트는 특정 작업이나 데이터셋에 의존하는 경우가 많았습니다. 반면 이 평가 방법은 100년 넘게 연구된 인간 인지 이론을 바탕으로 만들어져서 시간이 지나도 유효하고, 상황에 맞는 최고의 테스트를 사용할 수 있습니다. 또한 AI의 구체적인 강점과 약점을 진단할 수 있어, 단순한 총점보다 훨씬 유용한 정보를 제공합니다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)





