망고부스트가 AMD의 고성능 GPU 32개를 활용해 초대형 AI 모델을 약 11분 만에 학습하는 데 성공했다. 복잡한 하드웨어와 소프트웨어를 하나로 최적화해, 특정 장비에 의존하지 않고도 빠르고 효율적인 AI 학습이 가능하다는 점을 입증했다.
망고부스트는 메타 '라마2 70B 로라' 모델을 10.91분 만에 학습하는 데 성공했다고 5일 밝혔다.
이번 결과는 ML퍼프 기준으로 최초의 AMD 그래픽처리장치(GPU) 기반 멀티노드 학습 성과다. GPU 간 통신 병목을 제거하면서도 성능 저하 없이 학습 시간을 대폭 단축한 사례다.

측정은 국제 AI 벤치마크인 'ML퍼프 트레이닝 5.0(MLPerf Training v5.0)'에서 AMD '인스팅트 MI300X' 그래픽처리장치 32개를 활용했다.
특히 이번 학습에는 일부 파라미터만 미세조정하는 로라 방식이 적용돼 거대 모델에 대해 짧은 시간 안에 고효율 파인튜닝이 가능함을 입증했다.
망고부스트는 온프레미스와 클라우드 환경을 모두 지원하는 유연한 구조를 갖춰 특정 벤더나 하드웨어 환경에 얽매이지 않고 확장 가능한 학습 인프라를 구현하고 있다.
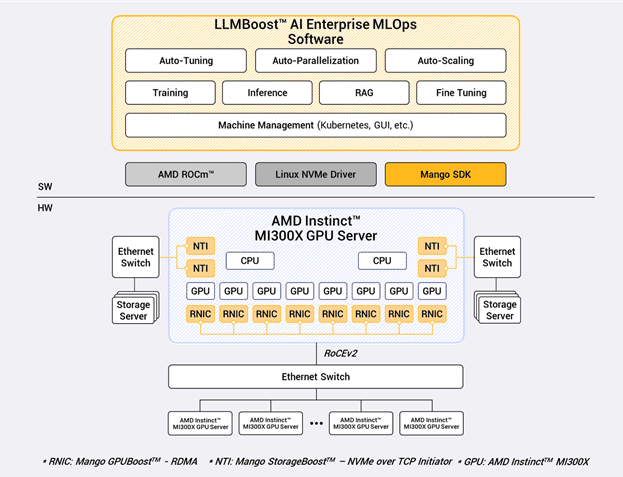
망고부스트는 자체 개발한 '망고 LLM부스트' 소프트웨어와 '망고 GPU부스트 RDMA' 통신 솔루션을 통해 모델 병렬화와 자동 튜닝, 배치 최적화, 메모리 조정 등을 통합 제공하는 시스템을 구현했다.
'LLM부스트'는 다양한 대규모 언어모델을 안정적으로 운영할 수 있도록 설계됐다. 'GPU부스트 RDMA'는 수천 개 큐피 환경에서도 성능 저하 없이 통신을 유지할 수 있도록 설계돼 있다.
ML퍼프 제출 기준으로는 노드 1개에서 2개, 4개로 구성된 멀티노드 환경 모두에서 95~100% 수준의 선형적 성능 확장성을 달성했다. 통신 병목을 해소한 원격 직접 메모리 접근(RDMA) 기반 구조와 GPU 최적화 소프트웨어가 병렬 학습 효율을 실질적으로 끌어올린 것으로 해석된다.
이번 학습 결과는 AMD 라데온 오픈 컴퓨트(ROCm) 소프트웨어 스택과의 통합을 기반으로 한다. 망고부스트는 이 환경에 맞춰 'LLM부스트'의 연산, 메모리, 네트워크 제어 구조를 최적화했고 'MI300X'의 메모리 대역폭과 성능을 극대화하는 데 초점을 맞췄다.
망고부스트는 이번 벤치마크 외에도 '라마2 7B', '라마3.1 8B' 모델에 대한 내부 학습 벤치마크를 통해 유사한 성능을 확보해온 것으로 알려졌다. 이 성능은 실제 온프레미스나 클라우드 환경 모두에서 재현 가능하며 일반화된 학습 효율을 보장한다는 점에서 상용화 가능성도 입증된 상태다.
관련기사
- "AI 인프라 대안 나올까"…망고부스트, 엔비디아 넘은 추론 성과 공개2025.04.05
- 망고부스트, AI 추론 최적화 소프트웨어 '망고 LLM부스트' 출시2025.01.16
- 망고부스트, 'SC24'서 DPU 전 제품군 공개…고성능 컴퓨팅 공략 강화2024.11.28
- 망고부스트, 글로벌 GPU 기업과 'DPU 기반 가속 솔루션' 공동 발표2024.09.30
ML퍼프와 ML커먼스의 창립자인 데이비드 캔터는 "망고부스트의 첫 ML퍼프 트레이닝 결과는 매우 인상적"이라며 "'MI300X' 단일 노드부터 4노드까지의 확장된 학습 성능은 현대 AI 가속기의 성능을 온전히 활용하려면 소프트웨어 스택의 최적화가 얼마나 중요한지를 다시 입증한 사례"라고 밝혔다.
김장우 망고부스트 대표는 "이번 ML퍼프 벤치마크에서 우리는 소프트웨어와 하드웨어의 통합 최적화를 통해 벤더 종속 없이도 대규모 LLM 학습을 효율적으로 수행할 수 있는 해답을 제시했다"며 "이번 결과는 우리 기술이 실제 데이터센터 운영 환경에서 충분히 확장 가능하다는 점을 보여주는 이정표"라고 밝혔다.