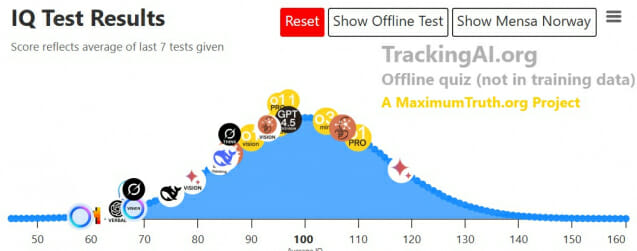
구글 제미나이 2.5 프로, IQ 130으로 AI 모델 중 최고 지능 입증
생성형 AI 기술이 빠르게 발전하면서 각 모델의 성능을 객관적으로 평가하는 지표의 중요성이 커지고 있다. 'Tracking AI'는 최근 17개의 텍스트 기반 AI 모델과 6개의 비전 기반 AI 모델을 대상으로 IQ 테스트를 실시했다. 특히 주목할 만한 결과는 구글(Google)의 제미나이 2.5 프로(Gemini 2.5 Pro Exp.)가 멘사 노르웨이(Mensa Norway) 테스트에서 IQ 130점을 기록하며 전체 AI 모델 중 가장 높은 점수를 획득했다는 점이다. 이는 일반적으로 인간의 '매우 우수한' 지능 수준으로 평가되는 점수로, AI가 인간 수준의 인지 능력에 근접하고 있음을 시사한다.
오프라인 테스트에서는 오픈AI(OpenAI)의 o1 프로(o1 Pro)와 o1 모델이 각각 120점과 125점으로 높은 점수를 기록했다. 앤트로픽(Anthropic)의 클로드 3.7 소넷 익스텐디드(Claude 3.7 Sonnet Extended)도 멘사 노르웨이 테스트에서 107점, 오프라인 테스트에서 118점을 기록하며 상위권에 위치했다.
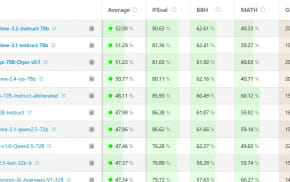
오픈AI와 앤트로픽의 경쟁: 상위 10개 AI 모델 중 7개가 오픈AI 제품
테스트 결과를 자세히 살펴보면, 전체 순위에서 상위 10개 모델 중 7개가 오픈AI의 제품이라는 점이 특히 주목할 만하다. 오픈AI의 o1 프로, o3 미니, GPT-4.5 프리뷰, o1, o3 미니 하이, o1 프로(비전), o1(비전) 모델이 모두 상위권에 위치했다. 이는 오픈AI가 다양한 유형의 AI 모델 개발에서 선두를 달리고 있음을 보여준다.
앤트로픽은 클로드 3.7 소넷 익스텐디드와 클로드 3.7(비전) 모델이 각각 3위와 9위를 차지하며 오픈AI와의 경쟁에서 선전했다. 특히 클로드 3.7 소넷 익스텐디드는 오프라인 테스트에서 118점을 기록하며 높은 성능을 보였다.
한편, 딥시크(DeepSeek)의 R1과 V3 모델은 각각 16위와 18위를 차지했으며, xAI의 그록-3(Grok-3)과 그록-3 씽크(Grok-3 Think)는 19위와 14위를 기록했다. 메타(Meta)의 라마-3.3(Llama-3.3)과 라마-3.2(비전)(Llama-3.2 Vision)은 하위권에 머물렀다.
텍스트 vs 비전: AI 모델의 도메인별 성능 차이 분석
테스트 결과를 통해 텍스트 기반 모델과 비전 기반 모델 간의 성능 차이도 확인할 수 있었다. 흥미로운 점은 동일한 AI 모델이라도 텍스트 처리와 이미지 처리 능력에서 상당한 차이를 보인다는 것이다. 예를 들어, GPT-4o는 텍스트 버전에서 멘사 노르웨이 테스트 94점, 오프라인 테스트 65점을 기록한 반면, 비전 버전에서는 각각 67점과 67점을 기록했다. 이는 동일한 모델이라도 도메인에 따라 성능이 크게 달라질 수 있음을 보여준다.
반면 오픈AI의 o1 프로는 텍스트 버전(멘사 노르웨이 110점, 오프라인 120점)과 비전 버전(멘사 노르웨이 87점, 오프라인 95점) 모두에서 상대적으로 균형 잡힌 성능을 보여주었다. 이는 멀티모달 AI 모델의 발전 방향을 시사한다.
생각하는 AI의 부상: 플래시 씽킹과 확장된 추론 기능의 효과
최근 AI 개발 트렌드 중 하나는 '생각하는(thinking)' 기능을 갖춘 모델의 등장이다. 구글의 제미나이 2.0 플래시 씽킹(Gemini 2.0 Flash Thinking Exp.)과 xAI의 그록-3 씽크(Grok-3 Think)가 이러한 추세를 대표한다. 테스트 결과, 제미나이 2.0 플래시 씽킹은 멘사 노르웨이 테스트에서 84점, 오프라인 테스트에서 111점을 기록했다. 또한 그록-3 씽크는 멘사 노르웨이 테스트에서 86점, 오프라인 테스트에서 108점을 획득했다. 이는 표준 모델보다 더 복잡한 추론을 수행할 수 있는 '확장된 사고' 기능이 실제로 AI의 문제 해결 능력을 향상시킬 수 있음을 보여준다.
클로드 3.7 소넷 익스텐디드 역시 '확장된(Extended)' 버전으로, 기본 모델보다 더 긴 시간 동안 복잡한 추론을 수행할 수 있는 능력을 갖추고 있다. 이 모델이 상위권에 위치한 것은 AI의 '사고 시간'이 성능 향상에 중요한 요소임을 시사한다.
FAQ
Q: IQ 테스트가 AI의 실제 능력을 측정하는 데 적합한 방법인가요?
A: IQ 테스트는 패턴 인식, 논리적 추론 등 특정 인지 능력을 측정하는 데 유용합니다. 그러나 AI의 전반적인 능력을 평가하기 위해서는 다양한 벤치마크와 실제 응용 사례를 함께 고려해야 합니다. Tracking AI의 테스트는 AI 모델 간의 상대적 성능을 비교하는 하나의 지표로 활용될 수 있습니다.
Q: 가장 높은 IQ 점수를 받은 AI 모델이 실제 사용에서도 가장 우수한가요?
A: 반드시 그렇지는 않습니다. IQ 테스트는 특정 유형의 문제 해결 능력을 측정하지만, 실제 사용에서는 문맥 이해, 사용자 의도 파악, 안전성, 편향성 등 다양한 요소가 중요합니다. 따라서 특정 사용 사례에 가장 적합한 모델은 IQ 점수만으로 결정할 수 없습니다.
Q: 일반 사용자가 이러한 AI 모델들을 어떻게 이용할 수 있나요?
관련기사
- [Q&AI] 클릭 한 번이면 '종소세 환급 신청' 완료… 어떻게?2025.04.01
- [Q&AI] 챗GPT ‘지브리 풍’ 이미지 생성 화제… 왜?2025.03.28
- 생성형 AI 없으면 뒤처진다…최고 경영진 89%가 도입 서두르는 이유2025.03.28
- 美 나스닥 데뷔하는 SK하이닉스…다음 투자 행보는2026.07.10
A: 대부분의 주요 AI 모델은 웹 인터페이스나 API를 통해 접근할 수 있습니다. OpenAI의 ChatGPT, 앤트로픽의 Claude, 구글의 Gemini 등은 일반 사용자를 위한 서비스를 제공하고 있으며, 일부는 무료 버전도 제공합니다. 기업용으로는 API를 통한 통합 옵션도 있습니다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)