







인간의 메모 습관에서 영감 얻은 AI 기술...토큰 92% 절감, 정확도는 그대로
대형 언어 모델(LLM)이 복잡한 추론 작업을 수행할 때 흔히 사용되는 사고 연쇄(Chain of Thought, CoT) 기법은 뛰어난 성능을 보여주지만, 추론 과정에서 발생하는 장황한 설명으로 인해 처리 속도가 느리고 비용이 많이 든다는 단점이 있었다. 줌 커뮤니케이션즈(Zoom Communications)의 연구진은 이러한 문제를 해결하기 위해 '체인 오브 드래프트(Chain of Draft, CoD)'라는 새로운 추론 방식을 개발했다.
체인 오브 드래프트는 인간의 문제 해결 방식에서 영감을 얻은 기술로, 사람들이 복잡한 문제를 해결할 때 필수적인 정보만 간결하게 메모하는 방식을 AI에 적용했다. 이 기술을 활용하면 LLM이 복잡한 문제를 해결하는 데 있어 기존 방식과 비슷하거나 더 나은 정확도를 유지하면서도 토큰 사용량을 최대 92%까지 줄일 수 있다.
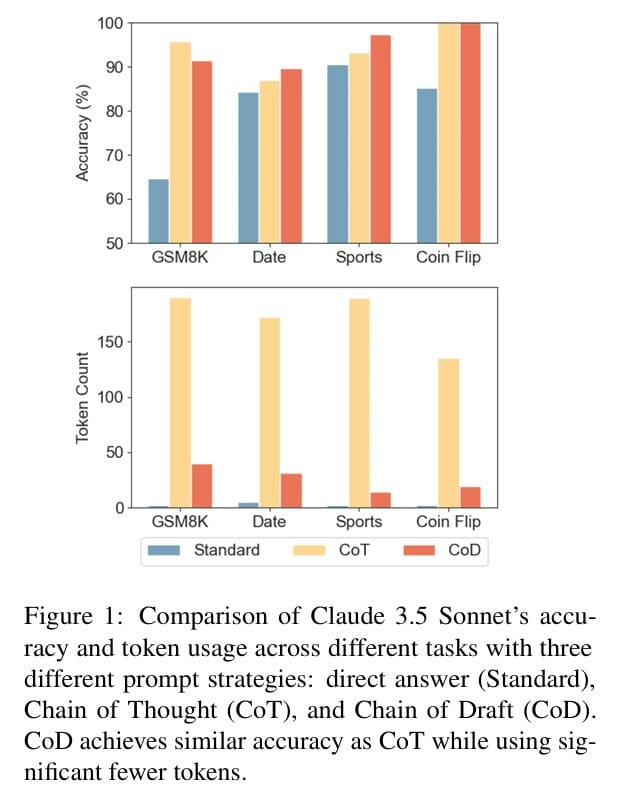
연구팀의 실험 결과에 따르면, 클로드 3.5 소네트(Claude 3.5 Sonnet) 모델에서 스포츠 이해 관련 추론 작업 시 체인 오브 드래프트 방식을 사용했을 때, 기존 CoT 방식이 사용하는 토큰의 7.6%만으로도 유사한 정확도를 달성할 수 있었다.
20개의 사탕 문제, 50단어 vs 8단어: 체인 오브 드래프트의 놀라운 효율성
체인 오브 드래프트는 기존의 CoT와 어떤 점이 다를까? 간단한 예시를 통해 살펴보자.
"제이슨이 사탕 20개를 가지고 있었다. 그는 데니에게 몇 개의 사탕을 주었고, 현재 제이슨에게는 12개의 사탕이 남아있다. 제이슨이 데니에게 준 사탕은 몇 개인가?"라는 문제가 있을 때, 기존의 CoT 방식은 다음과 같이 장황하게 설명한다:
처음에 제이슨은 20개의 사탕을 가지고 있었다.
데니에게 일부를 준 후, 제이슨에게는 12개가 남았다.
데니에게 준 사탕의 수를 찾기 위해, 초기 사탕 수와 남은 사탕 수의 차이를 계산해야 한다.
간단한 뺄셈 문제를 설정할 수 있다: 초기 사탕 수 - 남은 사탕 수 = 데니에게 준 사탕 수
숫자를 대입하면: A = 20 - 12 = 8
따라서, 제이슨은 데니에게 8개의 사탕을 주었다.
반면, 체인 오브 드래프트는 이 과정을 "20 - x = 12; x = 20 - 12 = 8"로 간결하게 요약한다. 불필요한 맥락 설명을 제거하고 핵심 수학적 연산에만 집중함으로써 토큰 수를 대폭 줄인 것이다.
4가지 벤치마크 테스트에서 입증된 80% 이상의 토큰 감소 효과
연구팀은 산술 추론, 상식 추론, 상징적 추론 등 다양한 벤치마크 테스트를 통해 체인 오브 드래프트의 효과를 검증했다. 산술 추론 테스트로는 GSM8k, 상식 추론 테스트로는 BIG-bench의 날짜 이해와 스포츠 이해 작업, 상징적 추론 테스트로는 동전 뒤집기 과제를 사용했다.
GPT-4o와 클로드 3.5 소네트 두 모델 모두에서 체인 오브 드래프트는 기존 CoT 방식과 비교해 토큰 사용량을 크게 줄이면서도 비슷하거나 더 나은 정확도를 보여주었다. 특히 동전 뒤집기 같은 상징적 추론 작업에서는 두 모델 모두 100%의 정확도를 달성하면서도, GPT-4o에서는 68%, 클로드 3.5 소네트에서는 86%의 토큰 감소 효과를 얻었다.
대형 모델에서 7.6%의 토큰만으로 91% 정확도 달성, 소형 모델에선 아직 숙제 남아
체인 오브 드래프트 기술이 뛰어난 성능을 보여주었지만, 연구팀은 몇 가지 한계점도 발견했다. 특히 소규모 언어 모델이나 few-shot 예시 없이 사용할 경우 성능이 저하되는 현상이 관찰됐다. 연구팀은 이러한 한계가 현재 LLM 훈련 데이터에 CoD 스타일의 추론 패턴이 부족하기 때문이라고 분석했다.
연구팀은 추후 연구에서 CoD를 다른 지연 시간 감소 방법과 결합하거나, 간결한 추론 데이터로 모델을 미세 조정하는 방안을 탐색할 계획이다. 이를 통해 연구 중심의 추론 능력 향상과 실용적인 시스템 요구 사항 사이의 간극을 좁힐 수 있을 것으로 기대하고 있다.
이 기술은 실시간 응용 프로그램이나 비용에 민감한 LLM 대규모 배포 환경에서 특히 유용할 것으로 전망된다. 효과적인 추론을 위해 장황한 출력이 반드시 필요하지 않다는 사실을 입증함으로써, 더 효율적인 AI 시스템 설계의 새로운 가능성을 제시하고 있다.
FAQ
Q: 체인 오브 드래프트(CoD)는 기존의 사고 연쇄(CoT) 방식과 어떻게 다른가요?
A: 체인 오브 드래프트는 추론 과정에서 불필요한 설명을 최소화하고 핵심 정보만 간결하게 표현하는 방식입니다. 예를 들어, CoT가 여러 단계의 상세한 설명을 제공한다면, CoD는 각 단계에서 필수적인 수식이나 변환만 간략히 표시합니다. 이를 통해 토큰 사용량을 크게 줄이면서도 유사한 정확도를 유지할 수 있습니다.
Q: 체인 오브 드래프트 기술이 실제로 어떤 이점을 가져다주나요?
A: 이 기술은 대형 언어 모델의 추론 과정에서 발생하는 지연 시간과 컴퓨팅 비용을 크게 줄여줍니다. 실험 결과, 토큰 사용량을 최대 92.4%까지 절감하면서도 정확도는 유지하거나 오히려 향상시킬 수 있었습니다. 이는 실시간 응용 프로그램이나 비용에 민감한 AI 서비스에 특히 유용합니다.
Q: 일반 사용자들은 체인 오브 드래프트 기술을 어떻게 체감할 수 있을까요?
관련기사
- 챗GPT와 클로드가 쓴 글, 97% 정확도로 구분…어떻게 가능?2025.03.04
- [Q&AI] 3월 근로장려금 신청 어떻게…17일 마감, 지급은?2025.03.04
- [Q&AI] 120만 유튜버 유우키 채널 삭제…성추행 무고 사건 총 정리2025.02.28
- AI 비서끼리 대화하면 어떤 일 생길까…관련 영상 화제2025.02.28
A: 일반 사용자들은 AI 챗봇이나 가상 비서 등 대형 언어 모델을 활용한 서비스에서 더 빠른 응답 속도와 더 효율적인 성능을 체감할 수 있을 것입니다. 특히 복잡한 질문에 대한 응답 시간이 크게 단축되고, 서비스 제공업체 입장에서는 운영 비용이 절감되어 더 저렴한 서비스 제공이 가능해질 수 있습니다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)





