







일반인도 검증 가능한 벤치마크의 필요성
AI 모델의 능력을 평가하는 벤치마크가 점점 더 전문화되면서 새로운 문제가 대두되고 있다. 웰슬리 칼리지와 텍사스 오스틴 대학 연구진들에 따르면, 현재의 벤치마크들은 대부분 PhD를 보유했거나 취득 중인 전문가들이 설계한 것으로, 일반인들은 문제 자체를 이해하기 어려울 뿐만 아니라 답이 맞는지 검증하는 것도 쉽지 않다. 이는 AI 모델이 왜 특정 문제를 어려워하는지, 답이 정확한지, 효율적으로 추론하고 있는지를 확인하기 어렵게 만든다. 연구진은 이러한 문제가 앞으로 추론 모델이 더욱 확산됨에 따라 더욱 중요해질 것이라고 지적한다. (☞ 논문 바로가기)
실제로 높은 학위 소지가 반드시 뛰어난 추론 능력을 의미하지는 않는다. 따라서 연구진은 일반적인 지식만으로도 이해할 수 있는 문제로 구성된 벤치마크가 필요하다고 주장한다. 이러한 문제는 해결하기는 어렵더라도 답을 검증하는 것은 AI와 인간 모두에게 쉬워야 한다는 것이 연구진의 설명이다.
박사급 지식은 필요 없다... NPR 퍼즐로 AI 능력 측정
연구진이 발표한 연구 논문에 따르면, 기존 AI 모델의 평가 방식을 완전히 새롭게 접근한 벤치마크가 등장했다. 지금까지의 AI 벤치마크는 대학 수준의 수학 경진대회 문제나 고난도 프로그래밍 문제, 학문적 전문 지식이 필요한 문제들로 구성되어 왔다. 그러나 NPR 선데이 퍼즐 챌린지를 기반으로 한 이 새로운 벤치마크는 전문적인 지식 대신 일반적인 상식을 활용해 AI의 성능을 측정한다. 1987년부터 방송된 이 라디오 퍼즐 프로그램은 매주 수백에서 수천 명의 청취자들이 정답을 제출할 만큼 대중적이며, 일부 퍼즐의 경우 사전이나 지도를 참고해 풀 수 있도록 명시적으로 안내하기도 한다.
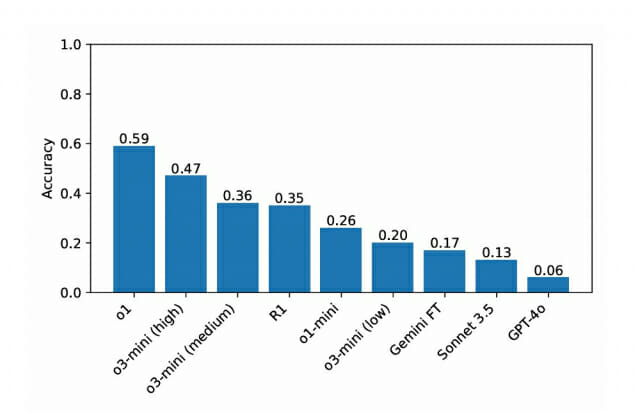
오픈AI o1, 59% 정답률로 경쟁 모델 압도
이번 연구의 가장 주목할 만한 결과는 오픈AI의 o1 모델이 59%의 정답률을 기록하며 다른 모델들을 크게 앞섰다는 점이다. o3-미니는 높은 추론 노력으로 47%, 기본 설정으로는 36%를 기록했으며, 딥시크 R1은 35%의 정답률을 보였다. 추론 기능이 없는 클로드 소넷 3.5와 GPT-4o는 각각 13%와 6%로 크게 뒤처졌다.
특히 주목할 점은, GPQA(구글 검증 Q&A)와 같은 PhD 수준의 과학 문제에서는 R1, o1, o3-미니 모델들이 비슷한 성능을 보였던 것과 달리, 이번 일반 상식 벤치마크에서는 모델 간 성능 차이가 뚜렷하게 나타났다는 것이다.
595문제 중 142건
포기 선언한 딥시크R1... 실패 유형 2가지
연구진은 AI 모델들의 새로운 실패 패턴을 발견했다. 딥시크 R1의 경우 595개의 도전 과제 중 142개에서 "포기할래"라고 선언했다. 실패 유형은 크게 두 가지로 나타났다. 첫째는 '공중에서 답 끌어내기'로, 추론 과정에서 전혀 언급하지 않은 답을 최종 답안으로 제시하는 경우다. 예를 들어 "alpha에서 중간 글자를 알파벳 순으로 이전 글자로 바꾸면 aloha가 되는" 문제에서 R1은 전혀 다른 "penne"와 "penné"를 답으로 제시했다. 둘째는 '의도적 제약조건 위반'으로, "queueing"이라는 답이 부적절하다는 것을 인정하면서도 어쩔 수 없이 답으로 제시하는 경우였다.
퍼즐의 합리성 검증
연구에 사용된 퍼즐들의 난이도가 적절했는지에 대한 의문이 제기될 수 있다. 그러나 연구진이 제시한 데이터에 따르면, "alpha에서 aloha로 바꾸는" 퍼즐의 경우 370명이 정답을 제출했고, "daiquiri" 문제는 500명이 맞췄다.
NPR 선데이 퍼즐 챌린지의 청취자 수가 약 400만 명으로 추정되는 것을 고려하면, 이 문제들이 도전적이면서도 충분히 풀 수 있는 수준임을 보여준다. 또한 정답자들이 대부분 동일한 답에 도달했고 오답 제출이 드물었다는 점에서, 퍼즐의 답이 명확하고 검증 가능하다는 것을 입증한다. 이는 AI 모델의 오답이 문제의 모호성이나 난이도가 아닌 모델 자체의 한계에서 비롯되었음을 시사한다.
R1의 영원한 생각 현상과 32,768 토큰의 한계
연구진은 R1 모델이 특정 문제에서 사고를 멈추지 못하는 현상을 발견했다. 32,768 토큰이라는 출력 제한에도 불구하고, 50개의 도전 과제에서 R1은 추론을 완료하지 못했다. 특히 "서로 다른 13개 글자로 구성된 미국 도시 이름 찾기"와 "7글자 음식 이름에서 첫 글자를 다섯 번째 위치로 옮기면 동의어가 되는 단어 찾기(brisket → risk, bet)" 문제에서 이러한 현상이 두드러졌다. 최대 컨텍스트 창(128K)으로 실험을 진행했을 때도 각 문제에서 10번 중 2번은 추론을 완료하지 못했다.
3,000 토큰 vs 10,000 토큰: AI 추론의 최적점 발견
연구진의 추론 과정 분석 결과, 대부분의 도전 과제는 20,000토큰 미만의 추론 출력을 생성했다. 제미니 씽킹은 약 10,000토큰에서 정확도가 정체된 반면, R1은 3,000토큰 정도에서 제미니 씽킹의 성능을 추월하기 시작했다. 모델의 불확실성도 관찰되었는데, R1은 29건, 제미니 씽킹은 18건, o1-미니는 3건의 사례에서 답을 번복했다.
한 가지 흥미로운 사례로, 7개 항목을 가진 카테고리를 찾는 문제에서 R1은 정답인 '대륙'을 초반에 발견했음에도 불구하고 다른 답을 계속 탐색하다가 결국 처음 찾은 답으로 회귀하는 모습을 보였다.
GPQA 9.1%에서 GSM8K 97%까지: AI 벤치마크의 현주소
최근 AI 모델들의 성능이 급속도로 발전하면서 기존 벤치마크들이 빠르게 포화상태에 도달하고 있다. GPQA의 경우 물리학, 화학, 생물학 분야의 PhD 과정 전문가들이 만든 문제들로 구성되었지만, 최신 추론 모델들은 불과 몇 달 만에 이를 정복했다. HLE(Humanity's Last Exam)는 더 광범위하고 어려운 문제들로 구성되어 있으나, 여기서도 오픈AI o1이 9.1%의 정확도를 기록했다.
관련기사
- AI 자율성 높아질수록 인간 역할 줄어든다…섬뜩한 경고2025.02.18
- 알트먼의 깜짝 고백…"GPT-4.5에서 AGI 느꼈다"2025.02.18
- 머스크, '그록3' 마침내 공개…GPT-4o 제치고 챗봇 성능 1위2025.02.18
- AI, 동물 통증도 잘 잡아낸다…"수의사 보다 11.5% 더 정확"2025.02.18
수학 분야에서는 더욱 두드러진 성과를 보여, GSM8K 같은 벤치마크에서 97% 이상의 정확도를 달성했다. 그러나 이번 NPR 퍼즐 챌린지는 AI 모델들이 여전히 일반 상식 영역에서는 한계를 보인다는 것을 증명했다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)





