







사우스캐롤라이나 대학교 인공지능연구소 연구진이 발표한 보고서에 따르면, 대형언어모델(LLM)이 우울증과 불안장애 진단을 위한 의료 보조 도구로서 높은 잠재력을 보여주고 있다.
표준화된 정신건강 평가도구의 AI 통합
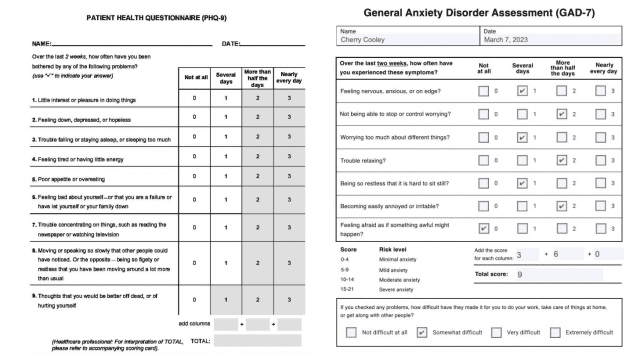
연구진이 활용한 PHQ-9과 GAD-7은 정신건강 진단의 핵심 평가도구다. PHQ-9은 지난 2주간 환자가 경험한 우울 증상을 9가지 항목으로 평가하며, 관심/흥미 상실, 우울감, 수면 문제, 피로감 등을 0-3점 척도로 측정한다. GAD-7은 불안장애 진단을 위한 7가지 항목을 평가하는데, 불안감, 과도한 걱정, 안절부절못함 등의 증상을 같은 방식으로 측정한다. 두 도구는 의료진들이 환자의 상태를 포착하기 위해 표준적으로 사용하는 진단 도구로, 증상의 심각도를 체계적으로 점수화한다.
의료진 부족 문제 해결할 AI 진단 보조 시스템
연구진은 환자가 급증하고 의료 인력이 부족한 현재 의료계의 문제를 해결하기 위해 LLM을 활용한 진단 보조 시스템을 제안했다. 이 시스템은 PHQ-9과 GAD-7 설문의 응답 패턴을 분석하여 주요우울장애(MDD)와 범불안장애(GAD)의 진단을 보조한다. 연구진은 특히 환자와 의료진 간의 자연어 대화 상황에서 LLM의 활용 가능성에 주목했다. 진단 보조를 위해서는 LLM이 표준 진단 절차를 정확히 따르는 것이 필수적이라고 연구진은 강조했다.
상용·오픈소스 AI 모델 모두 90% 이상 정확도 달성
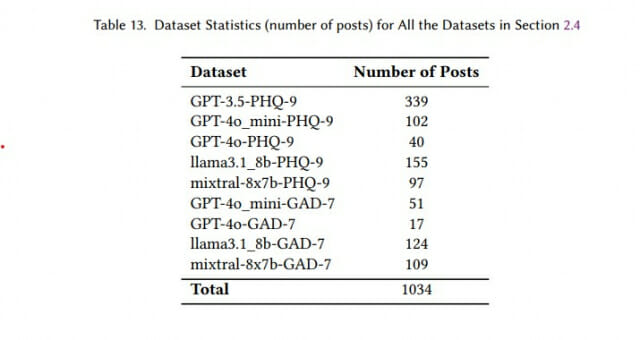
연구팀은 상용 및 오픈소스 모델을 대상으로 광범위한 테스트를 진행했다. 프롬프팅 방식의 평가에는 GPT-3.5와 GPT-4o와 같은 상용 모델과 llama-3.1-8b, mixtral-8x7b와 같은 오픈소스 모델이 사용되었다. 파인튜닝 실험에는 MentalLlama와 Llama 모델이 활용되었다.
상용 모델 중에서는 GPT-4o-mini가 96%의 정밀도와 98%의 재현율을 보여주며 가장 우수한 성능을 보였다. GPT-3.5-Turbo도 89%의 정밀도와 96%의 재현율로 높은 성능을 기록했다. 오픈소스 모델 군에서는 mixtral-8x7b가 96%의 정밀도와 95%의 재현율을 달성하며 상용 모델에 근접한 성능을 보여주었다.
전문가 검증으로 입증된 AI 진단의 신뢰성
연구진은 모델 평가를 위해 두 가지 방법을 사용했다. 첫째는 hits@k 기반 랭킹으로, 모델이 식별한 텍스트의 유사도를 기준으로 순위를 매기고 상위 k개 위치 내에 정답이 포함되는지를 확인했다. 둘째는 정확도, 정밀도, 재현율, F1 점수와 같은 표준 분류 지표를 활용했다.
평가에는 PRIMATE 데이터셋이 사용되었다. 이는 PHQ-9 관련 기준에 따라 주석이 달린 소셜 미디어 게시물 모음이다. 연구진은 먼저 GPT-4o를 사용해 게시물에서 PHQ-9 증상에 해당하는 텍스트 부분을 식별했고, 이를 전문 임상의들이 검증하는 과정을 거쳤다.
AI 진단의 현재 한계와 개선점
해당 연구에는 인도 국립정신보건신경과학연구소(NIMHANS) 출신의 전문가 3인이 평가에 참여했다. 이들의 평가는 우울증 진단에서 코헨의 카파 계수 0.74, 불안장애 진단에서 0.72의 높은 평가자간 신뢰도를 보였다. 특히 오픈소스 모델인 mixtral-8x7b는 GAD-7 기반 불안장애 평가에서도 92%의 정확도와 99%의 hits@5 점수를 기록하며 안정적인 성능을 보여주었다.
다만 연구진은 AI가 임상의의 추론 과정을 완벽히 모방하지는 못한다는 한계를 지적했다. 전문가들의 높은 합의를 얻은 데이터셋의 크기가 상대적으로 작다는 점은 AI의 추론 능력이 아직 임상의에 미치지 못함을 보여준다고 설명했다.
임상 현장 도입을 위한 DiagnosticLlama 개발과 미래 계획
연구팀은 AI 모델의 성능 향상을 위해 프롬프팅과 파인튜닝 두 가지 접근법을 시도했다. 특히 DiagnosticLlama라는 특화 모델을 개발해 진단 기준에 맞춘 파인튜닝을 진행했다. 연구진은 이러한 진단 특화 모델이 안전성과 프라이버시가 중요한 의료 환경에서 특히 유용할 것이라고 전망했다.
관련기사
- AI가 쓴 글, 사람 글과 정말 다를까…과학적으로 분석했더니2025.01.07
- AI로 돈을 더 잘 벌려면…금융사들이 택한 미래 전략2025.01.06
- 앤트로픽, 음악 출판사와 가사 저작권 분쟁 합의... "AI 가드레일 강화"2025.01.06
- AI와 VR로 '나폴리 피자 만들기' 가르쳤더니…효과 놀랍네2025.01.06
현재 연구팀은 이 모델들을 임상의들이 실제로 활용할 수 있는 앱으로 통합하는 작업을 진행 중이다. 또한 DiagnosticLlama 모델을 GAD-7 진단까지 확장하고, CSSRS와 같은 비선형 설문 구조로의 확장도 계획하고 있다. 연구팀은 이러한 발전이 의료진의 업무 부담을 줄이고 더 많은 환자들이 적절한 정신건강 케어를 받는 데 도움이 될 것으로 기대하고 있다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소넷과 챗GPT-4o를 활용해 작성했습니다. (☞ 보고서 원문 바로가기)





