






대규모 통계 분석으로 밝혀낸 AI 글쓰기의 한계
서울시립대학교 통계데이터과학과 연구진이 발표한 최신 연구에 따르면, 챗GPT로 대표되는 대형 언어모델(LLM)이 생성한 텍스트는 겉보기에 자연스러워 보이지만 인간의 글쓰기와는 본질적인 차이가 있는 것으로 나타났다. 연구진은 2023년 12월 6일부터 2024년 1월 17일까지 맨해튼 지역 446개 호텔의 3만2천여 개의 숙박 리뷰를 수집했으며, 추가로 CNN 뉴스 기사 8,008개, SQuAD2 문장 9,198개, 그리고 Quora 질문 24,714개를 분석 대상으로 삼았다.
혁신적인 연구 방법론으로 AI 텍스트의 본질에 접근
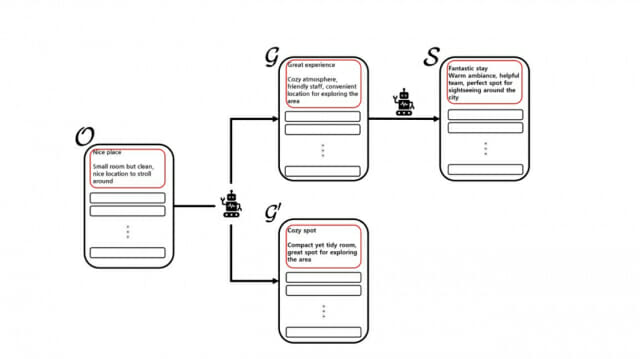
연구진은 두 가지 핵심 질문에 주목했다. 첫째, 원본 텍스트(O)와 GPT가 이를 바꿔 쓴 버전(G) 간의 잠재적 커뮤니티 구조 차이가 G와 이를 다시 바꿔 쓴 버전(S) 간의 차이와 같은지, 둘째, GPT의 텍스트 다양성을 제어하는 매개변수를 조절할 때 G가 O와 더 유사해지는지를 분석했다.
연구팀은 각 텍스트를 OpenAI의 text-embedding-3-small 모델을 사용해 1536차원의 단위 벡터로 변환했다. 분석을 위해 호텔링의 T-제곱 검정, Nploc 검정, 에너지 검정, 볼 검정 등 4가지 통계적 방법을 사용했으며, 클러스터 수를 2개에서 5개까지 변화시키며 실험을 진행했다. 또한 쿨백-라이블러 발산과 바서스타인 거리 분석을 통해 텍스트 간의 통계적 거리도 측정했다.
GPT의 다양한 설정값 변화에도 여전한 인간 텍스트와의 간극
연구팀은 GPT의 텍스트 생성 다양성을 제어하는 '온도' 매개변수를 0.1에서 1.5까지 다양하게 조절하며 실험을 진행했다. 실제 실험에서 사용된 호텔 리뷰 사례를 보면 흥미로운 차이가 드러난다. 원본 리뷰가 "기본적이고, 깨끗하고 편안한 호텔이다. 단기 숙박으로는 나쁘지 않다. 모든 것과의 접근성이 좋다"였을 때, GPT는 온도 설정에 따라 다음과 같이 다른 텍스트를 생성했다.
낮은 온도(0.1)에서는 "저렴하면서도 깨끗하고 아늑한 숙소를 제공하는 호텔이다. 빠른 숙박에 적합하다. 편리한 위치 덕분에 모든 편의시설에 쉽게 접근할 수 있다"와 같이 원본에 충실한 표현을 생성했다. 중간 온도(0.7)에서는 "아늑하고 잘 관리된 호텔로 모든 필수 시설을 갖추고 있다. 짧은 휴가에 딱 좋다. 위치의 편리함이 큰 장점이다"처럼 좀 더 자연스러운 변형이 이루어졌다. 높은 온도(1.5)에서는 "이 부티크 호텔은 기대 이상이었다. 객실은 아늑했고 직원들도 친절했다. 도시를 둘러보기에 완벽한 위치였다. 짧은 여행을 위한 훌륭한 선택이다"와 같이 원본과는 상당히 다른, 더 창의적이고 열정적인 표현이 생성됐다.
이러한 실험 결과는 온도 설정이 높아질수록 AI가 더 자유롭고 창의적인 표현을 생성하지만, 동시에 원본의 의도나 톤에서 더 멀어질 수 있음을 보여준다. 흥미롭게도 SQuAD2 데이터셋에서는 온도 매개변수가 증가할수록 인간 텍스트와의 유사성이 증가하는 특이한 패턴이 발견됐다. CNN과 SQuAD2 데이터의 경우, 한 문장으로 구성된 특정 문체를 가진 텍스트라서 일부 예외적인 결과가 나타났다.

텍스트 변환 과정에서 발견된 주목할 만한 차이
연구진은 텍스트 변환 과정에서 중요한 발견을 했다. 두 번째 패러프레이징(G에서 S로의 변환)이 첫 번째 패러프레이징(O에서 G로의 변환)보다 더 큰 변화를 보였다는 것이다. 이는 LLM이 텍스트를 변환할 때마다 원본과의 차이가 점점 더 커질 수 있음을 시사한다.
연구의 한계와 자연어 처리 분야의 새로운 과제
관련기사
- AI로 돈을 더 잘 벌려면…금융사들이 택한 미래 전략2025.01.06
- 앤트로픽, 음악 출판사와 가사 저작권 분쟁 합의... "AI 가드레일 강화"2025.01.06
- AI와 VR로 '나폴리 피자 만들기' 가르쳤더니…효과 놀랍네2025.01.06
- 메타, AI 캐릭터 프로필 추방…왜 그랬을까2025.01.06
연구진은 이번 연구가 가진 한계도 명확히 했다. 제안된 테스트 방법이 간접적인 증거만을 포착할 수 있어 탐지력과 적용 가능성이 제한될 수 있으며, 대응된 데이터 설정에서만 적용 가능하다는 제약이 있다고 설명했다. 또한 LLM의 성능을 정량적으로 평가할 수 있는 통계적 방법론이 부족한 현실을 지적하며, 이는 LLM이 최근에 등장했기 때문이라고 설명했다. 연구진은 이번 연구가 제시한 방법론이 향후 LLM 평가를 위한 새로운 기준이 될 수 있을 것으로 기대했다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT-4o를 활용해 작성했습니다. (☞ 보고서 원문 바로 가기)





