






챗GPT를 만든 미국 오픈AI가 마침내 GPT4를 발표했습니다. 그동안 미국을 비롯해 세계는 오픈AI가 언제 GPT4를 발표할 지를 놓고 루머가 무성했는데요, 지난주 독일 마이크로소프트(MS) 안드레이스 브라운(Andreas Braun) 최고기술책임자(CTO)가 전망한 대로 15일 오픈AI가 GPT4를 공개했습니다.
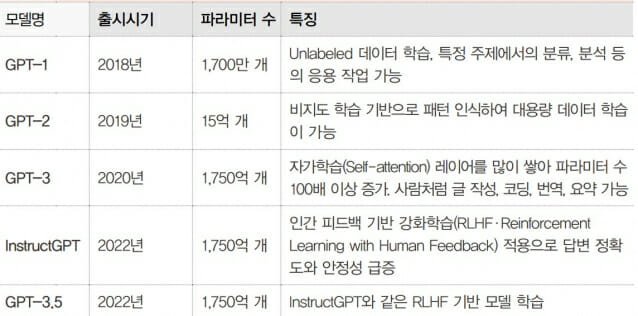
GPT가 처음 나온게 2018년이고 GPT2는 2019년, GPT3는 2020년, GPT3.5(챗GPT)는 2022년 11월에 나왔습니다. GPT3로만 보면 거의 2년만에 새 GPT(GPT4)가 나온 셈입니다.
예상대로 GPT는 텍스트 뿐 아니라 이미지도 인식할 수 있는 멀티모달AI였습니다. 그림으로 입력을 할 수 있게 된 거죠. 그림 내용을 바탕으로 대화와 해석이 가능하게 됐습니다. 하지만 아직 완벽하지 않다고 오픈AI는 발표설명회(프리젠테이션)에서 밝혔습니다. 단어 처리 능력이 대폭 강화된 부분도 눈에 띕니다. 챗GPT보다 처리할 수 있는 단어 수가 8배 많아졌습니다. 약 수십 페이지 분량의 명령어로 입력이 가능해졌습니다. 지원하는 언어도 26개국어가 됐습니다.
추론 능력도 훨씬 좋아졌고, 기존 시험에서 풀지못한 문제도 풀수 있게 됐습니다. GPT4를 사용하려면 기존 챗GPT플러스(월 20달러)로 유료 결제해야 합니다.
하지만 궁금증이 많았던 파라미터(매개변수) 수는 공개하지 않았습니다. AI의 성능을 좌우하는 요인인 파라미터에 대해 일각에서는 GPT4가 100조개가 될 거라는 루머도 있었는데요, 사실 이는 낭설일 가능성이 높습니다. 실제 오픈AI 최고경영자(CEO) 샘 알트먼도 이전에 파라미터 100조개 운운은 터무니없다고 말한 적도 있습니다.
산업계는 문자 처리보다 멀티모달 기능에 더 관심이 있었는데요, 막상 뚜껑을 열어보니 멀티모달보다 문자 처리 기능에 더 방점을 둔 듯한 느낌입니다. 여기에 마이크로소프트(MS) 검색(빙)에 우선 적용하는 등 MS에서 거대한 자금을 지원받다보니 오픈AI가 마치 MS 2중대가 된 듯한 느낌도 있습니다. 프리젠테이션 툴 기업으로 GPT4를 테스트한 AI스타트업 톰(Tome) 창업자 카이스 페이리스는 "GPT3와 3.5(챗GPT)가 6학년 같다면 GPT4는 똑똑한 10학년 같다"고 평가했습니다.

■ 공개하지 않은 파라미터...과연 몇 개 일까?
GPT4에 대해 우선 궁금한게 파라미터(Parameter) 숫자였는데요, 오픈AI는 이에 대해 입을 다물었습니다. 파라미터는 흔히 매개변수라고 불리는데요, 일반인과 문과생들은 금방 와 닿지 않은 개념입니다. 네이버 지식백과에 따르면, 파라미터는 '회로나 기계를 동작시킬 때, 조작 가능한 요소를 가리키는 것'이라고 쓰여 있습니다. 감이 금방 안 오는데요, 각각의 연산에 사용하는 기본 정보들(함수의 계수나 상수 등)을 매개변수라고 합니다. 디지털 기본 단위인 바이트(Byte)처럼 정보의 한 단위로 생각하면 될 것 같습니다.
파라미터가 많을 수록 AI 성능이 좋은 건 맞습니다. 하지만 반드시 그런 건 아닙니다. AI성능은 파라미터 외에도 알고리즘, 컴퓨팅 파워, 데이터가 좌우하기 때문에 이 세 박자가 모두 맞아야 합니다. 실제, 최근 거대AI모델을 새로 발표한 미국 빅테크 메타는 당시 "GPT보다 적은 파라미터를 갖고도 성능은 더 좋다"고 말한 바 있습니다. 파라미터를 많이 가지면 그만큼 비용이 더 많이 들기 때문에, 요즘 글로벌 추세는 파라미터를 늘리지 않고도 좋은 성능의 AI를 개발하는 것입니다.
이런 이유에서 오픈AI가 새로 발표할 GPT4의 파라미터가 100조개라는 건 넌센스일 가능성이 높았습니다. 샘 알트먼 오픈AI CEO도 수개월전 GPT4의 100조개 파라미터 루머에 대해 "엉터리(ridiculous)"라고 말한 바 있습니다.
사람의 신경망 세포인 시냅스가 100조개인데요, GPT4의 100조개 파라미터를 처음 제기한 곳은 미국 저명 IT잡지 와이어드로 2021년 8월 이렇게 추정 했습니다. 2018년 처음 나온 GPT1은 파라미터가 1700만 개, GPT2(2019년)는 15억개, GPT3(2022년)는 1750억개로 100배 커졌는데요, 이런 증가세로 미뤄 GPT4의 파라미터를 100조 운운한 것 같습니다. 오픈AI가 공개하지 않았지만, GPT4 파라미터는 5000억개 안팎일 것 같습니다.
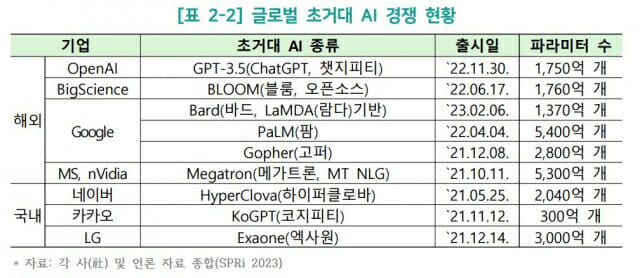
파라미터는 언젠가부터 1000억 개를 돌파하기 시작했는데, 이때부터 ‘초거대 모델(large language model)’이라는 호칭이 사용됐습니다. 현존하는 가장 많은 매개변수AI를 갖고 있는 곳은 구글입니다. 지난해 2월 발표한 '스위치-트랜스포머(Switch-Transformer)'는 매개변수가 무려 1조6000억 개에 달합니다. 1조개가 넘는 유일한 모델입니다. 이어 역시 구글이 지난해 4월 내놓은 팜(PaLM)의 파라미터는 5400억개고, 마이크로소프트(MS)가 2021년 10월 선보인 메가트론(Megatron)은 5300억개, 우리나라 LG가 2021년 12월 발표한 엑사원(Exaone)은 3000억개로 4위 정도 됩니다.
이들 외에 구글고퍼(2021년 12월)가 2800억개, 네이버 하이퍼클로바(HyperClova)는 2040억개, 오픈소스인 빅사이언스의 블룸(BLOOM)은 1750억개로 모두 요즘 핫한 챗GPT(1750억개)보다 매개변수가 많습니다. 구글이 최근 선보인 바드는 1370억개, 카카오 코지티피(KoGPT, 2021년 11월)는 300억개입니다.
■ 멀티모달로 진화한 GPT.."챗GPT가 6학년이라면 GPT4는 똑똑한 10학년"
오픈AI는 GPT를 처음 선보인 2018년 이래 약 1년 간격으로 새 제품을 선보였습니다. 즉 GPT2는 2019년, GPT3는 2020년, GPT3.5(챗GPT)는 2022년 11월 공개했는데요,
GPT1이래 5년만에 나온 GPT4에서 텍스트와 이미지를 동시에 이해하는 멀티모달을 선보였습니다.
GPT4가 멀티모달이 될 거라는 건 이미 예견된 거 였습니다. 지난주 GPT4가 이번주 나올 거라고 처음 이야기한 독일 마이크로소프트 CTO 안드레아스 바라운(Andreas Braun)은 당시 "챗GPT와 완전히 다른 가능성을 제공할 것"이라고 말했는데요, 이 중 하나가 멀티모달이였습니다.
멀티모달 AI는 다양한 모달리티(텍스트 등 입력)를 동시에 받아들여 결과를 내는 AI를 말합니다. 챗GPT 같은 기존 초거대 AI가 주로 언어(텍스트)에 초점을 맞춘 것이라면 멀티모달 AI는 한발 더 나아가 텍스트 외에도 △이미지 △음성 △제스처 △시선 △표정 △생체신호 등 여러 입력을 받아들여 결과를 냅니다. 즉, 텍스트를 넣으면 이미지나 영상(비디오)으로 만들어 줄 수 있습니다. 이에 챗GPT의 텍스트 뿐 아니라 영상, 음악 등에서도 큰 변화가 일어날 수 있습니다.
이미 오픈AI는 텍스트를 그림으로 만들어주는 '달리(DALL-E)'와 '달리2' AI를 선보인 바 있습니다. '달리'는 초현실주의 화가 살바도르 달리(Salvador Dalí)와 자율주행 로봇 이야기를 담은 2008년 애니메이션 영화 ‘WALL-E’에서 따온 말입니다. '달리'는 NLP(Natural Language Processing, 자연어처리)와 이미지 인식 기술을 함께 사용해 전에 학습한 적이 없는 이미지를 새로 만들어냈습니다.
사실 텍스트를 영상으로 전환하는 건 새로운 컨셉은 아닙니다. 이미 메타와 구글도 이런 AI를 갖고 있습니다. 즉, 메타는 'Make-A-Video'를, 구글은 'Imagen Video'라는 AI모델을 갖고 있습니다. 하지만 이들 회사 AI는 리서치(연구) 단계고 여러 이유로 아직 대중이 사용하지는 못합니다.
GPT4의 특징인 멀티모달은 AI가 인간과 더욱 자연스럽게 의사소통하게 해주는데요, 사람과 같은 AI인 일반인공지능(AGI)을 지향하는 오픈AI로서는 꼭 보유해야 할 AI입니다. 오픈AI 후원자 역할을 하고 있는 미국 마이크로소프트(MS)도 최근 문자뿐 아니라 이미지까지 이해해 생성할 수 있는 '비주얼챗GPT'를 소개하기도 했습니다.
우리나라도 멀티모달에서 일가견이 있습니다. 대표적인 곳이 LG인데요, LG는 작년 7월 자사가 만든 AI 아티스트 '틸다'를 세계 3대 광고제인 뉴욕 페스티벌에 출품, 금상과 은상을 받았습니다. 뉴욕 페스티벌은 칸 라이언즈, 클리오 어워즈와 함께 세계 3대 광고제로 인정 받고 있는데요, '틸다'는 세계 60여 개국에서 출품한 작품과 경쟁해서 이런 성과를 거뒀습니다. '틸다'에는 LG의 초거대 멀티모달 AI인 '엑사원'이 적용됐습니다. 현재 '엑사원'은 말뭉치 6000억개 이상과 언어와 이미지가 결합된 고해상도 이미지 3억5000만장 이상의 데이터를 학습한 것으로 알려져 있습니다. 특히 '엑사원은' IT만 아니라 금융, 의료, 제조, 통신 등 여러 분야 산업 데이터까지 학습하고 있어 다른 초거대 AI와는 차별화된 경쟁력을 갖고 있습니다. 각 도메인에서 쓸 수 있는 '도메인 특화 AI'인 것입니다.
LG는 우리나라 시각으로 14일 새벽 미국에서 열린 유명한 영화 및 TV 행사인 'SXSW(South by Southwest)'서 의료와 제약 분야에 적용한 '엑사원'을 소개, 주목을 받았습니다. 배경훈 LG AI연구원장은 "생성형 멀티모달AI(Generative Multimodal AI)가 단순히 그림을 그려주는데 활용되는 것 뿐 아니라 일반 이미지 3.5억장을 학습한 초거대 멀티모달 AI를 활용하면 병리 이미지, 피부과 이미지, X레이 판독사진 등을 기존 대비 10% 이하 레이블 데이터만 있어도 SOTA(최고 성능) 이상 성능을 만들어 낼 수 있다"고 밝혔습니다. LG는 이 AI를 한양대 병원과 검증 후 곧 논문으로 출간 할 예정인데요 글로벌 제약사에 공급도 할 계획입니다.

기업 뿐 아니라 우리 연구소도 정부 지원을 받아 멀티모달 AI 핵심 기술 확보에 열심입니다. 한국전자통신연구소와 한국전자기술연구원(Keti)이 멀티모달 관련 정부 과제 3개를 추진중인데요, 오는 2026년 과제가 완료됩니다. 아쉬운 것은 과제비가 미국 등과 비교하면 터무니없이 적다는 것입니다. 과제당 수년간 들어가는 연구비가 몇십억원 수준이니, 글로벌 빅테크 기업에 비하면 그야말로 '껌' 수준입니다.
■ 더욱 강력해진 단어 생성 능력을 가진 GPT4
멀티모달 외에 GPT4는 단어 생성 능력도 더욱 막강해졌습니다. 기존 챗GPT는 세션당 최대 토큰(Token, AI가 이해하는 언어 단위)이 4096개로 한 세션에서 최대 약 8000 단어까지 처리할 수 있었습니다. 세션은 AI와 사람이 묻고 답하고 묻고 답하기를 주고 받는 구간이라고 이해하면 됩니다.
GPT4는 이 능력이 챗GPT보다 8배 많은 최대 3만2760개 토큰, 최대 6만4000개 단어를 처리할 수 있게 향상됐습니다. AI가 단편소설 하나를 그야말로 눈깜짝 할 새 쓸 수 있다는 거죠. 이 뿐 아니라 GPT4는 다른 나라 말로 번역할 수 있는 것도 한국어를 포함해 26개 국어로 늘렸습니다. 외신은 이탈리아말을 예로들어 이를 우크라이나와 한국어로 번역해준다고 보도했습니다.
월스트리트저널(WSJ)에 따르면 프리젠테이션 툴 기업으로 GPT4를 테스트한 AI스타트업 톰(Tome)의 창업자 카이스 페이리스는 "GPT3와 3.5(챗GPT)가 6학년 같다면 GPT4는 똑똑한 10학년 같다"고 평가했습니다. 오픈AI는 GPT4의 성능 안정성을 확보하기 위해 약 50명 AI전문가에게 6개월 정도 자문을 받았다고 밝혔습니다.
■GPT의 Generative Pre-trained Transformer는 무엇?
보통 이름을 보면 그 정체를 유추할 수가 있죠. GPT도 마찬가지입니다. 그 이름을 뜯어보면 어떤 '물건'인지 알 수 있습니다. GPT는 Generative Pre-trained Transformer의 약어입니다.
관련기사
- 오픈AI 초거대 멀티모달 ‘GPT-4' 공개..."오류·편향성 줄였다"2023.03.15
- 독일 마이크로소프트 "GPT-4 다음 주 나온다"2023.03.10
- 챗GPT 시대, 기자와 저널리즘의 역할은 뭘까2023.03.08
- 美, 앤트로픽 '미토스5' 빗장 풀어…"100여 곳에 허용"2026.06.27
우선 Generative. 이는 말 그대로 생성한다, 무엇을 만든다는 겁니다. 그럼 Pre-trained는 무슨 뜻일까요?. 우리말로 번역하면 사전학습입니다. AI는 (데이터) 학습의 결과물인데요, GPT는 사전학습을 한 AI입니다. 사전학습에 끝나지 않고 파인튜닝이라는 또 한번의 학습을 했습니다. 두번의 학습을 한 AI인 셈이죠. AI기술은 크게 지도학습(supervised learning), 비지도학습(unsupervised learning), 강화학습 3가지가 있는데요, GPT는 사전학습은 비지도학습 기술로, 파인튜닝은 지도학습 기술로 만든 AI입니다.
GPT에 중요한 또 하나의 기술이 Transformer입니다. 트랜포머AI는 문장 속 단어와 같은 순차 데이터 내의 관계를 추적해 맥락과 의미를 학습하는 신경망으로, 어텐션(attention) 또는 셀프어텐션(self-attention)이라 불립니다. 구글(Google)의 2017년 논문에 처음 등장한 용어인데요, 지금까지 개발한 모델 중 가장 새롭고 강력한 것으로 평가받습니다. 세계 AI연구를 선도하는 미국 스탠퍼드대학교 연구진은 2021년 8월 발표 논문에서 트랜스포머를 '파운데이션 모델(foundation model)'이라 부른 바 있는데, 이 모델들이 AI의 패러다임 변화를 견인하는 근간으로 봤기 때문입니다.





