






이미지 내 객체 위치를 기존보다 정밀하게 출력하는 인공지능(AI)이 나왔다.
마이크로소프트 연구팀은 생성AI가 만든 이미지 안에 있는 객체 위치를 정확히 지정할 수 있는 AI모델 ‘레코’를 공개했다고 마크테크포스트가 25일(현지시간) 보도했다.
일반적으로 '스테이블 디퓨전'이나 '달리-2'등 AI 이미지 생성기는 프롬프트에 텍스트를 입력하면 이를 사실적인 이미지로 내놓는다.
그러나 아직 해결하지 못한 걸림돌이 있다. 정밀함이다. 사용자가 원하는 이미지를 얻으려면 프롬프트에 텍스트를 세세히 입력해야 하고 이를 생성AI가 100% 이미지로 구현할 수 있다는 보장도 없다. 텍스트가 복잡해지면 이미지 출력하는데 시간도 오래 걸린다.
특히 사용자가 텍스트에 객체 위치를 설정해도 출력 이미지에 반영되지 않는 경우가 있다. 예를 들어 '방 왼쪽 구석에서 잠자는 공주'라고 텍스트 프롬프트에 입력하면 이미지 출력에 객체인 공주가 방 왼쪽 구석이 아닌 한 가운데에서 잠자는 이미지로 나오는 경우가 흔했다는 의미다.
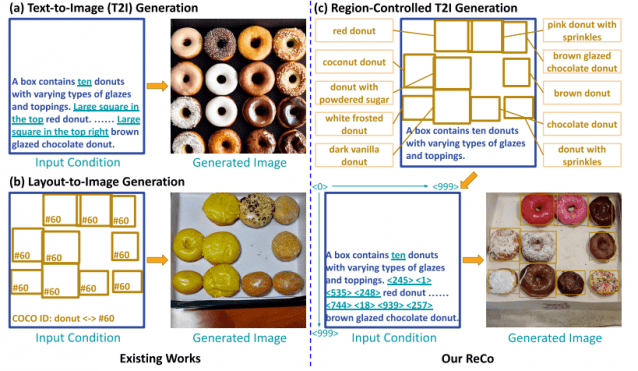
마이크로소프트 연구팀은 텍스트와 객체를 별도로 모델링하는 '레이아웃-이미지 접근 방식'을 택해서 발생한 현상이라고 설명했다. 해당 방식으로 모델링하면 사용자가 원하는 이미지를 텍스트 프롬프트에 세세히 설명해도 이를 100% 이미지 구현한다는 보장이 없다.

반면 레코는 텍스트와 객체를 결합해 한 번에 모델링하는 '영역 제어 이미지 생성 모델'을 택했다. 레이블이 있는 객체 경계 상자를 입력으로 사용해 그 안에 원하는 이미지를 생성한다. 모델이 공간 좌표 입력을 경계 상자를 통해 이해해서 정밀성이 높다.
결과적으로 텍스트와 이미지라는 서로 다른 입력 조건을 전보다 원활하게 결합할 수 있다. 연구에 참여한 양쩐양 마이크로소프트 선임연구원은 "기존보다 객체 위치를 정확하게 출력할 수 있다"며 "기존 AI 이미지 생성기 기능을 확장한 방식이라 보면 된다"고 밝혔다.





