






영어에서 동사의 배치에 따라 평서문과 의문문으로 달라지는 것처럼 단어의 배치 순서는 문장의 의미를 결정하는 데 중요하다.
하지만 현재 인공지능(AI) 학습에 쓰이는 언어모델은 문장에서 단어만으로 내용을 유추하기 때문에 정확도를 높이는 데 한계가 있다.
이러한 문제점을 해결하기 위해 문장구조를 비교 분류한 자료가 포함된 데이터셋을 구글이 공개했다.
구글이 신규 인공지능(AI) 학습용 데이터세트 모델 2종 PAWS와 PAWS-X를 공식 블로그를 통해 3일(현지시간) 공개했다.
PAWS는 영어의 단어 순서, 구문 구조를 분석한 데이터 셋이며 PAWS-X는 한국어, 중국어, 스페인어, 독일어 등 비영어 중심의 데이터세트다.
언어에 따라 단어 순서 및 구문 구조가 문장의 의미에 큰 영향을 미치지만 기존 언어모델은 이러한 정보를 제공하지 못했다.
그래서 이를 기반으로 학습한 AI는 단어의 조합을 통해서만 내용을 유추해야 하기 때문에 배치 순서에 따라 내용이 달라지는 경우는 해석이 어려웠다.
구글은 현재 가장 주목받는 언어모델인 버트(BERT) 역시 ‘뉴욕에서 출발해 플로리다에 도착하는 항공편’(Flights from New York to Florida)과 ‘플로리다에서 출발에 뉴욕에 도착하는 항공편’(Flights from Florida to New York)처럼 단어가 아닌 순서에 따라 문맥이 달라지는 문장은 구분은 정확도가 50% 수준이라고 밝혔다.
PAWS는 이러한 문제를 해결하기 위해 미국의 지식인 사이트로 알려진 쿼라(Quora)와 위키피디아에서 전문가가 선별하고 라벨링한 중첩률이 높은 영어 문장 10만 8천 463쌍이 포함돼 있다.
PAWS-X는 사람이 비교한 2만3천659 쌍의 언어 소스와 PAW를 활용해 번역한 29만 6천406 쌍의 데이터가 제공된다.
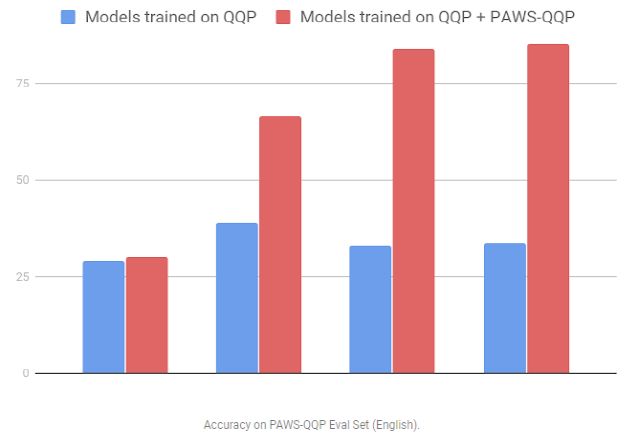
구글은 PAW-X 개발을 위해 중국어, 프랑스어, 독일어, 한국어, 일본어 및 스페인어 등 6개국 이사의 언어 전문가를 고용해 기계 학습 모델이 분류한 내용에 대해 검수를 진행했다고 밝히며 두 데이터세트를 통해 50% 수준이었던 정확도를 85~90%까지 끌어올릴 수 있고 설명했다.
관련기사
- 구글, 기계학습 플랫폼 ‘텐서플로 2.0’ 정식 출시2019.10.04
- "상담자료분석·고령자맞춤응대"…BNK금융 AI퍼스트 실험2019.10.04
- LG CNS, AI 학습용 한국어 데이터 '코쿼드2.0' 공개2019.10.04
- BNK금융그룹, AI 언어모델 ‘버트’ 고객 상담 분석에 적용2019.10.04
또한 새로운 데이터세트를 활용해 다양한 언어 데이터를 병합해 다국어 번역모델을 학습시킨 결과 정확도가 상승한 것으로 나타났다.
구글 장위엔 리서치 과학자와 양잉페이 소프트웨어 엔지니어는 “영어를 비롯해 여러 언어의 번역 데이터를 합쳐 학습한 결과 번역율이 높아진 것을 확인했다”며 “이를 기반으로 문장이나 문구 배열에 따른 식별 문제와 관련해 다국어 번역의 성능을 더욱 높일 수 있을 것으로 예상된다”고 전했다.





