






구글이 인공지능(AI)을 이용해 아마추어가 찍은 사진을 프로작가의 작품 수준으로 탈바꿈시켜주는 소프트웨어를 개발하고 있다.
이 기술이 상용화될 경우 일반인들도 스마트폰 카메라로 전문 사진작가 수준의 작품을 만들 수 있을 것으로 기대된다.
3일(현지시간) 미국 지디넷 등 주요 IT외신들은 구글이 매사추세츠공과대학(MIT) 연구팀과 공동으로 촬영 전단계부터 사진을 보정할 수 있는 이미지 처리 알고리즘을 만들고 있다고 보도했다.
이번 연구에서 눈길을 끄는 부분은 카메라 하드웨어 성능 향상 대신 소프트웨어 쪽에 초점을 맞췄다는 점이다. 또 사진 보정 프로그램의 용량도 최소화해 누구나 쉽게 활용할 수 있도록 했다.

■ 전문 사진사의 보정작업 직접 학습
구글과 MIT는 효율 극대화를 위해 머신러닝과 신경망을 활용했다. 이 둘을 활용해 전문 사진작가의 보정 작업과정을 직접 익히도록 했다.
신경망 훈련에는 어도비와 MIT가 만든 사진 5천 장이 동원됐다. 다섯 명의 전문 사진작가들에게 각 사진들을 후보정하도록 했다.
그런 다음엔 구글의 사진 보정 알고리즘이 보정 과정을 직접 학습하도록 했다. 보정 전 사진과 후 사진을 비교하면서 전문가의 솜씨를 하나씩 익히도록 한 것이다.
쉽게 비유하자면 사진 하나씩을 놓고 전문 사진작가로부터 하나씩 과외교습을 받는 것이나 마찬가지 과정을 거쳤다.

■ 용량 최소화해 개인 스마트폰에서 바로 활용
또 다른 강점은 용량이다. 머신러닝으로 스마트폰 사진을 개선하려는 시도는 이전에도 적지 않았다.
하지만 구글과 MIT의 연구는 알고리즘 용량을 최소화했다는 점이 눈에 띈다. MIT 블로그에 따르면 이 소프트웨어는 용량이 디지털 사진 한 장 정도에 불과하다.
덕분에 다양한 유형의 이미지를 바로 바로 보정작업할 수 있게 됐다.
실제 실험 결과는 놀랍다. 구글이 픽셀폰으로 테스트한 결과 1920X1080 크기의 처리된 미리보기로 바꿔주는데 단 20밀리초(ms=1000분의 1초), 1200만 화소 사진의 경우 61ms 밖에 걸리지 않았다.
반면, 사진을 보정해 고화질 이미지로 변환시켜 주는 HDR+ 기능을 사용했을 때, 1200만 화소 사진을 변환하는데 400-600ms이 걸렸다.
휴대폰 안에서 바로 실행될 수 있게끔 알고리즘을 효율적으로 만든 덕분에 사용자들은 실시간으로 보정된 사진을 촬영할 수 있게 된 것이다.
특히 머신러닝으로 학습한 전문 사진사의 노하우를 결합함에 따라 개별 사진에 최적화된 이미지를 만들어낼 수 있다고 외신들이 전했다. 따라서, 사용자가 보통 때와 같이 사진을 찍어도 훨씬 개선된 이미지를 얻을 수 있다는 점이 이 알고리즘의 핵심이다.
머신러닝 알고리즘은 새로운 이미지를 통해 학습이 가능한 만큼, 유명한 사진작가의 사진을 학습해 그와 비슷한 느낌의 사진을 찍을 수 있게 할 수 있다. 페이스북과 프리즈마가 유명 화가의 화풍으로 사진을 바꿔주는 필터를 제공하는 것과 비슷하다.
■ 이미지를 수식으로 변환…정확도 향상-용량 감소 동시 달성
구글과 MIT의 알고리즘은 어떻길래, 고화질 보정에 들어가는 시간을 10분의 1 수준으로 단축시켜 실시간 변환이 가능한 걸까.
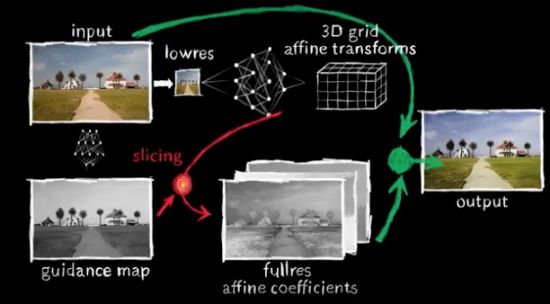
이 알고리즘은 MIT가 2015년 진행한 연구를 기반으로 만들어졌다. MIT는 당시 이미지 변환 속도를 높이기 위해 촬영한 이미지를 저해상도로 변경한 후 웹서버에 보내, 이렇게 보정하면 된다는 일종의 '변환 레시피'를 받아다 원본에 적용해 고해상도 이미지를 만드는 방식을 생각해 냈다.
하지만 당시 MIT의 방식은 치명적인 약점이 있었다. 보정하는 데 들어가는 속도는 줄일 수 있지만, 정교한 보정이 어려웠던 것. 저해상 이미지에 맞춰 제시된 보정값을 고해상도 이미지에 적용하니 엉성한 부분이 생긴 것이다.
구글은 저해상도 이미지를 활용해 변환 속도를 높인 MIT의 초기 아이디어가 상당히 효과적이라고 보고, 정교함까지 높일 수 있는 방법을 MIT와 함께 찾기로 했다.
그래서 생각해 낸 방식이 '변환 레시피'를 이미지 대신 수식으로 알려주도록 한 것이다. 학습 과정에서 알고리즘의 성능은 원본에 적용했을 때 결과 수식이 보정 이미지 버전와 얼마나 유사한가로 결정된다.
보다 정밀하게 수식을 적용하기 위해 이미지를 3차원의 16X16 조각이 되게 선을 그었다. 각 셀은 원본의 색상 값의 변화를 결정하는 수식을 포함하고 있다.
덕분에 사진 보정작업 자체를 수학공식처럼 기억할 수 있게 됐다. 전문 사진사의 보정 기법을 학습한 결과를 좀 더 효율적으로 활용할 수 있게 됐다. 전체 이미지 단위가 아니라 모듈 단위로 학습 결과를 적용할 수 있기 때문이다.
■ "하드웨어 한계, 소프트웨어로 극복"
알파고를 떠올려보면 쉽게 이해할 수 있다. 알파고는 바둑 전체 과정에 대한 학습과 함께 150여 수에 이르는 각 단계별 경우의 수를 모두 학습했다. 덕분에 전문가 수준의 바둑 실력을 익힐 수 있었다.
사진을 셀 단위로 나눈 구글의 이번 알고리즘 역시 비슷한 방식으로 볼 수도 있다. 학습량이 많아질수록 전문가 뺨칠 정도의 정교한 수준으로 진화 발전할 수 있기 때문이다.
관련기사
- 구글 "성능 안 좋은 앱, 검색 불이익 준다"2017.08.04
- 구글, 스냅챗 인수 제안…성사될까?2017.08.04
- 구글, 눈에서 표정 추측하는 AI 공개2017.08.04
- 개인정보 너무 추적한 구글, 美 FTC 조사 받나2017.08.04
구글은 왜 이런 연구를 하는 걸까?
이에 대해 IT매체 더버지는 "스마트폰 카메라의 하드웨어 한계를 넘기가 점점 어려워지면서 구글이 소프트웨어적인 방법으로 사진 화질을 개선하는 데 노력을 기울이고 있다"고 해석했다.





