






예상치 못한 수많은 상황에 부딪치게 되는 인간 세상에서 인공지능(AI)은 어떻게 하면 더 안전하고 효율적으로 자신의 업무를 수행할 수 있을까?
커제 9단과 겨룬 알파고는 자신을 상대로 수많은 셀프대국을 펼치면서 수를 다듬는 과정을 거쳤다. 그러나 완벽히 짜여진 룰이 없는 인간 세상에서 모든 업무를 알파고가 대체하는 시기가 오기에는 아직 넘어야할 과제들이 많다.
그 중 하나는 AI가 위험을 피하면서 인간처럼 상식 선에서 행동할 수 있는가에 대한 문제다.
최근 딥마인드는 글로벌 AI 연구 프로젝트인 오픈AI와 협업해 'AI의 안전성(AI Safety)'를 보장하기 위한 새로운 방안을 고안했다.

기존 데이터를 입력해 특정한 패턴을 뽑아내는 머신러닝과 스스로 최대한 보상을 얻을 수 있는 방법을 찾아내는 강화학습만으로는 부족한 부분을 인간의 상식이 개입해 해결하겠다는 시도다.
딥마인드는 블로그를 통해 AI의 안전성을 해결하기 위한 핵심 질문 중 하나는 "어떻게 인간이 AI 시스템에게 원하는 것과 그렇지 않은 것을 구분해서 말해 줄 수 있느냐"라고 설명했다.
AI 기술이 현실 세계에 더 깊숙히 적용될수록 이 문제는 점점 더 수면 위로 드러나게 된다.
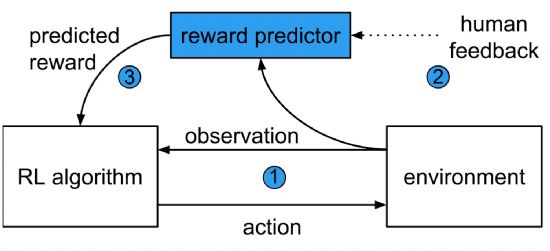
딥마인드와 오픈AI는 공동 연구를 통해 강화학습을 적용한 AI 시스템에게 비기술적인 경험을 학습시킬 수 있는 방안을 고안했다. 이런 방안은 특정한 목표를 수행하는 AI 시스템을 만들기 위해 미리 인간이 알고리즘을 짜고, 수정해야한다는 필요성을 제거했다.
이를 위해서는 비전문가 인간이 AI 시스템을 최소 30분간 만 피드백을 주는 방법으로 훈련시키면 된다.
예를 들어 로봇이 공중제비를 도는 모습을 구현하는 목표에 대해서는 AI 시스템이 가진 알고리즘에 900회 가량 피드백을 주면 실제로 AI 시스템이 공중제비 하는 모습을 보여줄 수 있게 된다.

이런 과정은 '인간 선호도를 반영한 심층강화학습(Deep Reinforcement Learning from Human Preferences)'이라는 논문에서 확인할 수 있다.(관련논문링크, 오픈AI 블로그)
전통적인 강화학습은 여러 계층의 인공신경망 위에서 '보상 예측기(reward predictor)'를 적용해 더 높은 점수를 기록하는 등 목표에 도달하는 것에만 초점을 맞췄다.
반면 심층강화학습은 강화학습이 미처 파악하지 못한 상황에서 어떻게 행동하는 것이 가장 상식 선에서 맞는지에 대한 인간의 피드백을 반복적으로 입력한다.
그 결과 AI 시스템은 인간의 선호도를 반영해 목표를 달성할 수 있게 된다.
다시 말하면 AI 시스템이 인간이 선호하지 않는 행동을 하지 않도록 막는 효과를 낸다. 이런 방식이 AI의 안정성 문제를 해결하는 단초가 될 것으로 연구팀은 전망했다.
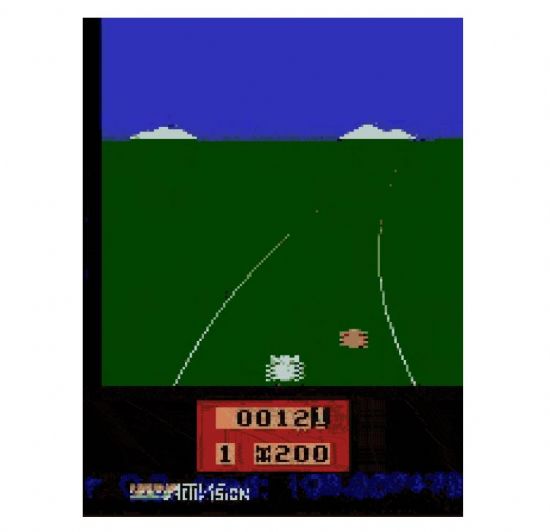
게임 개발사 아타리의 고전 자동차 경주 게임 엔듀로(Enduro)를 예로 들면 시행착오 끝에 원하는 최적의 결과를 도출해내는 전통적인 강화학습과는 다른 결과를 확인할 수 있었다. 다른 자동차를 제치고 가장 높은 점수를 내는 방법을 쓰는 대신 인간이 개입해 옆에 있는 다른 자동차와 나란히 움직이는 장면에 대한 피드백을 주자 AI 시스템도 이를 따라 했다.
주목할 점은 AI 시스템이 이미 원하는 목표를 가장 빨리 도달할 수 있는 방법을 알고 있음에도 불구하고 인간 세상에 통하는 상식을 반영해 행동을 조정할 수 있게 됐다는 사실이다. 자율주행차를 예로 들면 목적지에 가장 빨리 도달하는 방법에 앞서 옆차와 안전거리를 유지하면서 목적지에 도달할 수 있는 방법까지 배울 수 있게 되는 셈이다.
다만 AI 시스템에 대한 인간의 개입이 너무 초기에 끝나버리면 오히려 의도치 않은 방식으로 행동하게 되는 오류가 발생할 수도 있다.
관련기사
- 기업 맞춤형 AI 지원…'엘리먼트AI', 1천149억원 투자 유치2017.06.15
- AI 무장한 구글 스프레드시트, 말도 알아 듣는다2017.06.15
- AI 시대, 글로벌 기업들은 어떤 인재 원할까2017.06.15
- 보잉, 조종사 없는 ‘AI 여객기’ 개발2017.06.15
그럼에도 불구하고, 꽃병을 빨리 청소하기 위해 꽃을 다 망가뜨리거나 청소로봇이 젖은 걸레를 콘센트 주변에 놓는다는 등 인간이 상식적으로 하지 않는 행동을 AI 시스템이 할 수 있게 될 날이 그리 멀지 않아 보인다.
아래 동영상은 AI 시스템이 공중제비를 넘는데 인간이 개입해 더 나은 결과를 보여준다.





