






구글의 인공지능이 새로운 역사를 창조했다. 그동안 난공불락의 영역으로 꼽혔던 바둑 프로기사와의 대결에서 사상 처음으로 승리했다.
구글은 인공지능 프로그램인 알파고가 중국계 프로기사 판 후이 2단과 대국에서 5번 모두 승리했다고 발표했다. 구글은 이 같은 결과를 담은 '심층신경망과 트리 검색으로 바둑 게임 정복하기(Mastering the game of Go with deep neural networks and tree search)’란 논문을 28일(현지 시각) 과학잡지 <네이처>에 게재했다.
특히 관심을 끈 것은 구글의 다음 행보다. 구글은 알파고가 오는 3월 한국에서 바둑 최강인 이세돌 9단과 승부를 벌일 예정이라고 밝혀 벌써부터 많은 관심이 쏠리고 있다.

■ "최적의 위치 평가" 문제의식으로 출발
컴퓨터가 프로기사와 대국에서 승리한 건 이번이 처음은 아니다. 지난 2014년 바둑 프로그램인 크레이지 스톤이 일본의 요다 노리모토 9단과 대결에서 1승 1패를 기록한 적 있다.
하지만 당시엔 노리모토 9단이 넉점을 깔아주고 승부를 겨뤘다. 접바둑이 아닌 대등한 승부에서 컴퓨터가 인간을 물리친 것은 이번이 처음이다.
구글 알파고는 어떻게 바둑 프로 기사와 대결에서 승리할 수 있었을까? 구글이 <네이처>에 발표한 논문을 중심으로 한번 살펴보자.
구글 알파고는 2014년 인수한 인공지능 기업 딥마인드가 개발한 바둑 프로그램이다. 이번에 발표한 논문은 딥마인드 공동 창업자 및 최고경영자(CEO)였다가 지금은 구글 엔지니어링 부사장을 맡고 있는 데미스 하사비스(Demis Hassabis)를 비롯한 20명이 공동 집필했다.
이 논문은 “완벽한 정보를 갖고 있는 모든 게임은 각 지점에 최적의 가치 기능을 갖고 있다”는 문장으로 시작한다. 가장 적합한 곳에 가장 적합한 수를 뒀다는 의미다.
논문을 여는 첫 문구는 연구팀이 바둑을 어떤 관점으로 접근했는지 짐작할 수 있도록 해 준다.
바둑은 가로 19X세로 19칸으로 구성된 바둑판 위에 최적의 지점을 찾는 게임이다. 이 관점으로 접근할 경우 쉽게 해답을 찾을 수 있을 것 같다. 하지만 고려해야 할 경우의 수가 엄청나다.
미국의 디지털문화 전문 잡지 와이어드에 따르면 바둑 한 수를 둘 때 고려할 경우의 수가 250개 정도에 이른다. 문제는 이게 ‘연속된 경기’란 점이다. 한 경기에 150수 이상 둔다고 가정하면 '250의 150승'에 달하는 경우의 수가 만들어진다.
더 어려운 점은 바둑이 각 수가 유기적으로 연결돼 있는 게임이란 점이다. 중간에 수 하나가 달라지면 결과는 엄청나게 다른 결과로 이어진다. 그 동안 인공지능으로 바둑 경기를 정복하기 힘들었던 건 이 때문이었다.
흔히 바둑처럼 복잡한 게임은 ‘b의 p승’의 경우의 수를 갖는다. 이 때 b는 각 위치당 합법적으로 움직일 수 있는 수로 흔히 ‘게임의 넓이’로 통한다. 반면 ‘p승’은 한 경기에 두게 되는 수를 의미하며 ’게임의 깊이’로 통한다.
■ 3단계 학습 과정 거치면서 '특급 기사'로 변신
구글 논문은 체스 한 경기 규모가 ’b=35, p=80’ 정도인 반면 바둑은 ‘b=250, d=150’ 수준이라고 주장했다. 규모 면에서 바둑과 체스는 비교가 안 된단 얘기다. 알파고는 이 많은 경우의 수를 줄이는 방법으로 최적의 수를 도출해냈다.
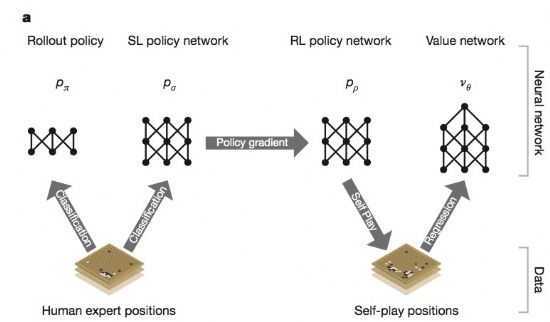
이를 위해 알파고는 가치망(value networks)과 정책망(policy networks)이란 두개의 신경망을 구성했다. 여기에 몬테카를로 트리 검색(MCTS)을 결합했다. MCTS는 다양한 경우를 감안해 가장 적합한 결정을 할 수 있도록 해 주는 알고리즘이다. 지난 2014년 크레이지 스톤이 노리모토 9단과 접바둑 대결에서 승리할 때 사용한 방법론이기도 하다.

이중 정책망은 다음 번 돌을 놓을 위치를 선택한다. 반면 가치망은 승자를 예측하는 역할을 한다.
이 복잡한 과정을 최대한 간소화하기 위해 ‘검색 가능한 경우의 수’를 줄여나갔다. 이 때 구글이 사용한 방법은 크게 두 가지다.
우선 위치 평가를 통해 어떤 곳에 놓을 때 최적의 승률을 낼 수 있을 지 알아내는 작업을 수행했다. 이를 통해 ’검색의 깊이’를 줄일 수 있었다.
그런 다음엔 적절한 바둑 수를 축적한 정책망에서 예측 가능한 행위를 추출해냈다. 이를 통해 검색 범위를 줄일 수 있었다고 구글이 네이처에 제출한 논문을 통해 밝혔다.
물론 이를 위해선 알파고를 훈련시켜야만 했다. 훈련은 크게 3단계로 진행됐다. 이 과정에서 ‘지도학습(supervised learning, SL)’과 ‘강화학습(reinforecd learning, RL)’이란 두 가지 학습법이 동원됐다.
1. 정책망 지도학습
첫 단계는 최적의 수를 찾는 정책망을 학습시키는 작업이다. 이를 위해선 지도학습 방법이 사용됐다.
이 과정에선 방대한 바둑 데이터베이스를 활용했다. 그 동안의 각종 기보들을 통해 인간 프로기사들이 둠직한 장소르 찾아내는 작업이다.
구글은 <네이처> 논문에서 총 13개 층위의 정책망을 훈련시켰다고 밝혔다. 이들에게 KGS 바둑 서버에 있는 3천만 개 위치 정보를 입력하는 방식으로 반복 훈련을 했다.
이런 훈련을 통해 ‘다음 수 예측률’을 크게 높일 수 있었다. 이전까지 44.4%였던 바둑 프로그램의 다음 수 예측 확률을 57%까지 향상시킨 것. 13%P 늘어난 예측 정확도는 엄청난 승률 향상으로 이어졌다고 구글 측이 밝혔다.
2. 정책망 강화학습
지도학습을 끝낸 뒤에는 강화학습으로 이어진다. 알파고의 진짜 경쟁력은 바로 이 부분에서 나온다고 보면 된다.
강화학습은 머신러닝의 한 분야다. 간단하게 설명하면 이런 방식이다. 어떤 로봇이 현재 상태를 인식한 뒤 행동을 취한다. 그럴 경우 이 로봇은 행동 결과에 따라 포상을 얻게 된다. 물론 이 때 긍정, 부정 포상이 모두 가능하다.
강화학습 알고리즘은 이런 과정을 거치면서 가장 많은 포상을 받을 수 있는 행동이나 선택을 찾아내는 방법을 탐구하는 것이다.
강화학습은 실전을 통해 지도학습으로 습득한 데이터를 가다듬는 과정이다. 이를 위해 지도학습 데이터를 무작위로 추출한 뒤 경기를 벌이는 방식을 택했다. 이를 통해 최상의 성과를 낸 수를 계속 강화해나가는 방식이다.
구글 측은 ‘강화학습’을 한 정책망을 ‘지도학습’ 정책망과 대결시킨 결과 80% 이상 승률을 올릴 수 있었다고 밝혔다.
오픈소스 바둑프로그램인 파치(Pachi)와도 대결했다. 파치는 한 수를 둘 때마다 10만회 시뮬레이션이 가능한 프로그램이다. 이 대결에서도 강화학습 정책망은 85% 가량의 승률을 기록했다.
3. 가치망 강화학습
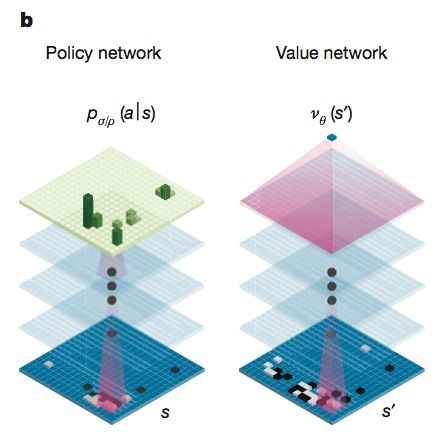
마지막 단계는 가치망을 훈련시키는 작업이다. 여기엔 수를 둘 위치 평가(position evaluation)에 초점을 맞춘다. 이를 통해 경기를 할 두 선수가 어떤 곳에 바둑알을 놓을 지 예측하는 작업이다.
가치망이 중요한 건 이 때문이다. 알파고의 두 신경망인 정책망과 가치망은 최적의 수를 찾는 역할을 한다는 점에선 비슷하다. 하지만 정책망은 여러 경우의 수를 제시하는 반면 가치망은 ‘가장 적합한 한 가지 예측치(a single prediction)’을 제시한다.
여기서 중요한 고려 요소가 있다. 바둑은 첫 수부터 마지막 수까지 유기적으로 연결돼 있다. 따라서 중간에 수 하나가 달라지게 되면 엄청나게 판이한 결과로 이어진다.
알파고는 이 문제를 해결하기 위해 개별 수 대신 게임 전체를 회귀분석하는 방법으로 접근했다. 돌 하나 때문에 결과가 확 달라지는 것을 피하기 위해서였다.
구글은 3천만 개 가량의 위치 정보로 구성된 데이터를 이용해 자체 경기를 반복했다고 밝혔다. 이를 통해 경기력을 꾸준히 향상시켜나갔다.
딥마인드 연구팀의 데이티브 실버는 와이어드와 인터뷰에서 “알파고는 신경망들끼리 수 백 만회의 게임을 반복하는 과정을 통해 스스로 새로운 전략을 찾아내는 방법을 익혔다”고 밝혔다.
4. 정책망과 가치망 활용해 최적의 수 찾기
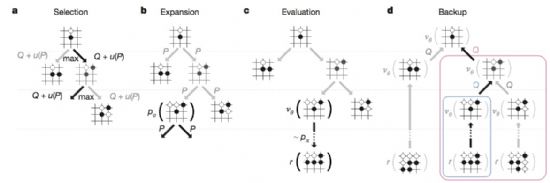
알파고는 두 개 신경망(가치망+정책망)과 MCTS를 함께 활용해 어디에 바둑알을 놓을 지를 골라낸다. 이 때 각 검색 트리의 위치 정보에는 행동가치, 방문 횟수, 그리고 사전 확률 등이 담겨 있다.
이 중 상태가치와 함께 강화학습의 중요한 개념 중 하나인 행동 가치는 특정 행동을 했을 때 기대되는 미래 가치의 총합을 의미한다.
MCTS에서는 이런 공식을 활용해 가장 행동 가치가 높은 지점을 추려나가는 과정이다. 시뮬레이션 작업을 통해 검색 트리 상의 모든 지점들이 행동 가치와 방문 횟수 정보를 계속 업데이트하게 된다.
구글 연구팀은 알파고의 성능을 평가하기 위해 크레이지 스톤, 젠을 비롯한 여러 바둑 프로그램과 대국을 했다고 밝혔다. 그 결과는 놀라웠다.
정책망과 가치망 강화학습과 내부 트레이닝을 거친 알파고는 다른 바둑프로그램과 총 495회 경기를 해서 494회 승리했다. 승률 99.8%였다.
알파고는 여기서 한 걸음 더 나갔다. 이번엔 4점을 깔아준 뒤에 경기를 벌였다. 구글은 크레이지 스톤, 젠, 파치 등 세 개 바둑 프로그램과 ‘넉점 접바둑’을 둔 실험에서도 각각 77%, 86%, 99% 승률을 기록했다고 밝혔다.
■ 참고 자료
- Silver, D. et al., “Mastering the game of Go with Deep neural networks and tree search,” Nature vol 529, pp. 484-489, 28 Jan 2016.
- Silver, D.& Hassabis, D. "AlphaGo: Mastering the ancient game of Go with machine learning," Goole Research Blog, 27 Jan 2016.
관련기사
- 구글 알파고, 이세돌 9단 이길 확률은2016.01.29
- 이세돌과 세기의 대결 앞둔 구글 인공지능의 출사표2016.01.29
- 이세돌 9단과 구글 인공지능이 붙는다2016.01.29
- 머신러닝은 툴이다2016.01.29
- Metz, Cade, "In a huge breakthrough, Google's AI beats a top player at the game of Go," Wired, 27 Jan 2016.
- 김익현, 구글-페북 머신러닝 승부 "핵심은 바둑" 지디넷코리아, 2015. 12. 8





