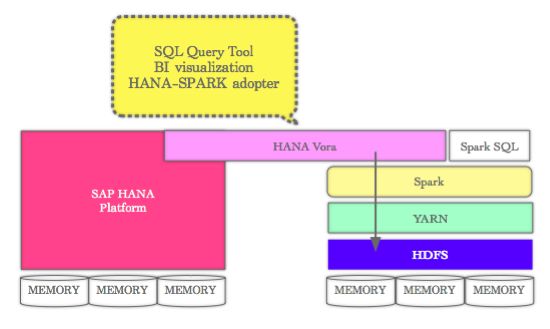
“SAP HANA 보라(Vora)는 아파치 스파크 위에 올라가는 인메모리 쿼리 엔진이다. 종전 HANA와 별도의 플랫폼으로, HANA 플랫폼과 하둡-스파크 플랫폼을 연결하는 가교역할을 한다. 기업의 비즈니스 프로세스로 만들어지는 데이터와 하둡의 방대한 빅데이터를 효율적이고, 단순하게 활용할 수 있게 된다.”
그렉 맥스트라빅 SAP 데이터베이스및기술부문 총괄사장은 15일 인터뷰에서 이같이 밝혔다.
SAP는 지난 1일 하둡과 스파크 환경을SAP HANA 플랫폼에 연결할 수 있는 ’HANA 보라(Vora)’를 발표했다. HANA 보라는 인메모리 쿼리 엔진으로 하둡에 저장된 데이터를 인메모리 환경에서 온라인분석하게 해준다. 맥락 정보를 추출해 중요한 분석 결과를 업무에 재 적용 할 수 있게 도와준다는 설명이다.

동시에 데이터를 시맨틱 측면에서 이해하는 온라인분석처리(OLAP)와 유사한 분석 기능을 제공한다. 비즈니스인텔리전스(BI) 수준으로 분석할 수 있어 데이터 분석가가 기업 데이터와 하둡 데이터를 쉽게 결합할 수 있다고 회사측은 강조했다.
그랙 맥스트라빅 사장은 “스파크 위에 보라가 얹어지고. 스파크 API를 보라가 사용하게 된다”며 “스파크 프레임워크로 데이터를 캐싱하고, 인메모리에 저장, 처리하면서 계층적으로 드릴다운하는 분석 방식에서 스파크나 하둡보다 빠르게 데이터를 활용하게 해준다”고 말했다.
그는 “하둡은 배치 처리에 알맞고, 보라는 실시간 처리 측면에 알맞다”며 “보라는 스파크 역할을 보완하면서 기존 트랜잭션 시스템과 결합하는 HANA의 확장으로써 기업 데이터호수로 널리 자리잡은 하둡을 쉽고 단순하게 활용하는 방법을 제공한다”고 덧붙였다.
HANA 보라는 별도의 소프트웨어로 HANA 플랫폼과 독립적으로 사용가능하다. HANA 플랫폼이 ERP, CRM 등 기업 내부 데이터를 활용하는 공간이라면, 보라는 하둡에 무더기로 쌓인 방대한 비정형 데이터를 인메모리 환경에서 SQL로 분석하는 도구다.
그는 “기업은 사물인터넷(IoT)과 같은 센서에서 생성되는 엄청난 양의 데이터를 하둡이란 데이터호수에 저장하고 있다”며 “하지만 기존 비즈니스 프로세스와 데이터 호수를 결합하는 게 쉽지 않은데, 양자 사이에 정렬되지 않은 간극이 존재하기 때문”이라고 말했다.
그는 “기업은 필요에 의해 무수한 데이터를 생성하는데, 오히려 관리하는 비용만 늘어나는 상황이 벌어진다”며 “HANA 보라는 이에 대한 해법으로 디지털 기업을 실현하는 좀 더 용이한 경로를 제공한다”고 강조했다.
SAP는 그동안 빅데이터 분야에 HANA 플랫폼을 내밀어왔다. 그러나 HANA는 정형 데이터 처리를 인메모리 환경에서 수행하는 플랫폼이기 때문에 비정형 데이터 중심의 데이터 디스커버리엔 적합하지 않다.
HANA 보라는 이같은 HANA 플랫폼의 맹점을 보완한다. 하둡이란 또 다른 플랫폼을 인정하고, 같은 인메모리 기술인 스파크를 통해 HANA와 하둡을 연결한다. 보라를 이용하면 하둡 데이터 처리 결과를 HANA 플랫폼으로 가져와 활용하는 것도 가능해진다.
그는 “모든 데이터 메모리에 둘 수 없다”며 “HANA는 OLTP와 OLAP을 단일 환경에 통합한다는 우리의 목적을 달성하는 솔루션이며 보라는 정형과 비정형 데이터를 연결하는 대용량 데이터 분석 솔루션”이라고 말했다.
이어 “HANA는 빅데이터 프레임워크의 일부로 보는 게 적합하며, 만병통치약으로 이해한다면 잘못된 것”이라고 덧붙였다.
한편, 그렉 맥스트라빅 사장은 사이베이스에 대한 SAP의 입장을 정리했다. 기업에서 요구하는 데이터베이스 조건이 다양하고, 그에 맞는 다양한 솔루션을 제공한다는 기본 전략에 입각한 설명이다.
그는 “사이베이스는 우리 데이터베이스 포트폴리오의 중요한 제품”이라며 “사이베이스 고객이 많고, 만족도도 높아 계속 투자하고 개발해 나갈 것”이라고 말했다.
관련기사
- 빅데이터-BI 융합 가속...SAP도 가세2015.09.16
- 운동선수의 꿈이 부상에 꺾이지 않도록...2015.09.16
- SAP, 도시 문제 솔루션 '미래도시' 공개2015.09.16
- SAP 분석 플랫폼에 구글 협업 기술 통합된다2015.09.16
그는 “조만간 사이베이스 개발팀이 한국 주요고객과 만나는 이벤트를 마련하고, 구체적인 로드맵을 소개할 것”이라며 “시장별로 사이베이스에 대한 특정 요구사항을 받아서 개발을 진행하고 있는데,한국은 특히 많은 사이베이스 고객을 보유한 시장이라 더욱 집중할 계획”이라고 덧붙였다.
그는 이어 “모든 데이터를 인메모리에 넣을 필요는 없다고 본다”며 “사이베이스는 시스템 기록 관련 애플리케이션의 데이터를 처리하는 중요한 제품으로 계속 투자하고 개발해 나갈 것”이라고 강조했다.