AI 비서가 내 일정을 챙기고 메일에 답하고 알아서 할 일을 처리해주는 미래는 이미 도착한 것처럼 보인다. 그런데 사용자의 디지털 세계 전체를 진짜로 맡겨봤더니, 가장 똑똑하다는 GPT-5.5(GPT-5.5)조차 열 번 중 예닐곱 번은 일을 끝내지 못했다. 화웨이(Huawei)와 베이징이공대 등 연구진이 2026년 5월 공개한 AI 개인비서 벤치마크 'Claw-Anything(클로-애니씽)'이 보여준 결과다. AI 개인비서 벤치마크란 항상 켜져 있는 AI 비서가 실제 사용자의 디지털 생활을 얼마나 제대로 도와주는지를 점수로 측정하는 시험을 말한다. 이 시험 점수는 우리가 곧 내 개인정보를 AI에게 어디까지 맡겨도 되는지를 가늠하는 잣대가 된다.
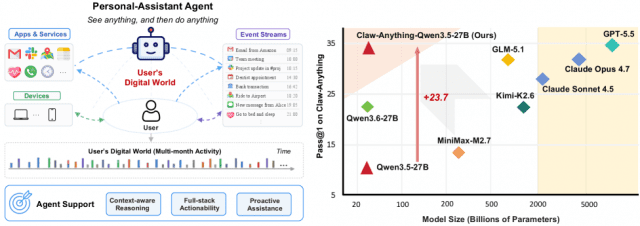
그림1. Claw-Anything의 개요와 오픈웨이트 모델 최고 Pass@1 성능
디지털 세계 전체를 본 AI, 성공률 34.5%
연구진이 공개한 Claw-Anything 벤치마크에서 최신 모델 GPT-5.5의 작업 성공률(Pass@1)은 34.5%에 그쳤다. 같은 모델이 기존 시험에서는 훨씬 높은 점수를 받아왔다는 점을 생각하면, 이 숫자는 충격에 가깝다. 항상 켜진 개인비서(always-on personal assistant)란 사용자가 따로 부르지 않아도 늘 배경에서 작동하며 이메일, 일정, 메신저 같은 디지털 활동을 지켜보다가 필요한 순간 돕는 AI를 말한다.
지금까지 AI 비서 평가는 "카메라 가격을 검색해줘" 같은 단발성 심부름을 잘하는지만 봤다. 하지만 진짜 비서라면 내가 지난주에 무엇을 검색했는지, 어제 누구와 약속을 잡았는지, 내 메일함과 캘린더와 메신저에 흩어진 정보를 연결해 판단해야 한다. 연구진은 바로 이 '넓은 시야'를 시험대에 올렸고, 시야가 넓어지자 최신 AI들이 줄줄이 무너졌다.
3개월 활동기록, 수십 개 서비스, 여러 기기로 늘어난 시험 범위
Claw-Anything가 어려운 이유는 AI에게 던지는 정보의 양이 기존 시험과 차원이 다르기 때문이다. 이 벤치마크는 한 과제당 평균 10.1개, 최대 18개의 서비스를 동시에 다루게 하고, 3개월이 넘는 사용자 활동기록과 수십 개 백엔드 서비스를 깔아둔다. 과제 하나에 담기는 글자 수만 19만 단어(191.7k)에 달하는데, 기존 벤치마크가 보통 2천에서 1만 2천 단어 수준이었던 것과 비교하면 수십 배 규모다.
쉽게 말해, 예전 시험이 쪽지 한 장을 주고 답을 묻는 것이었다면 이번 시험은 두꺼운 일기장과 수십 개 앱을 통째로 던져주고 그 안에서 답을 찾으라는 셈이다. 게다가 연구진은 일부러 쓸데없는 사건과 서로 모순되는 신호 같은 '잡음'을 잔뜩 섞어 현실과 비슷하게 만들었다. 그 결과 닫힌 모델들의 성적도 나란히 낮았다. GPT-5.5가 34.5%로 가장 높았고, 클로드 오퍼스 4.7(Claude Opus 4.7) 31.8%, 클로드 소네트 4.5(Claude Sonnet 4.5) 28.0%였으며, 오픈소스 모델 GLM-5.1(GLM-5.1)은 31.7%를 기록했다.
보고도 실행하지 못하는 AI, 진짜 약점은 따로 있었다
연구진이 짚은 가장 큰 실패 원인은 '조사와 실행 사이의 간극(investigation-execution gap)'이다. AI가 흩어진 정보를 찾아내 상황은 제대로 이해해놓고도, 그 이해를 실제 행동으로 옮기는 마지막 단계에서 무너진다는 뜻이다. 비유하자면 자료 조사는 끝냈는데 정작 보고서 제출 버튼을 누르지 못하는 인턴과 비슷하다.
정보를 빼버리는 실험에서 이 약점은 더 선명해졌다. 활동기록(이벤트 스트림)을 없애자 성공률은 0%로 떨어졌고, 여러 서비스를 넘나드는 도구를 막자 역시 0%에 수렴했다. 기기를 넘나드는 협업 과제에서도 PC와 휴대폰을 함께 쓰게 했을 때는 16%였지만, PC만 쓰게 제한하자 2%로 곤두박질쳤다. 게다가 활동기록이 길어질수록, 다뤄야 할 서비스가 많아질수록 성적은 꾸준히 내려갔다. 시야를 넓게 줘도 그 넓은 맥락을 끝까지 활용하는 능력은 아직 한참 부족하다는 신호다.
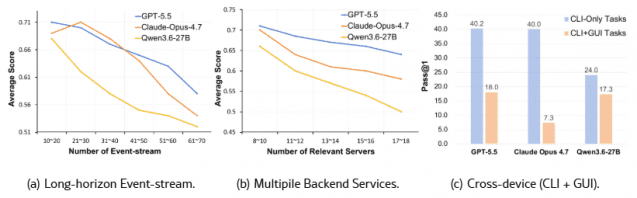
그림2. 맥락 규모(이벤트 기록·서비스 수·GUI 접근)에 따른 성능 변화 실험
시키기 전에 알아서 돕기, 가장 어려운 마지막 관문
같은 시험 안에서도 AI들이 가장 크게 헤맨 부분은 '능동적 도움(proactive assistance)'이었다. 능동적 도움이란 사용자가 명령하지 않아도 AI가 상황을 먼저 읽고 알맞은 제안을 건네는 능력을 말한다.
Claw-Anything에서 시켜야 움직이는 반응형(reactive) 과제의 성공률은 25.9%였지만, 알아서 먼저 돕는 능동형(proactive) 과제는 6.7%에 그쳤다. 약 네 배 차이다. "내가 어제 본 카메라 가격이 떨어졌어"라고 물으면 답을 찾아오는 일과, 묻기도 전에 "어제 보신 카메라 가격이 떨어졌으니 지금 사시는 게 좋겠습니다"라고 먼저 말을 거는 일은 전혀 다른 수준의 과제라는 뜻이다. 진짜 비서다움의 핵심인 '눈치'야말로 현재 AI가 가장 못 넘는 벽인 셈이다.
내 디지털 인생을 맡기기 전에 짚어야 할 것
흥미로운 점은 이 시험이 단지 AI의 한계를 들춰내는 데서 끝나지 않는다는 데 있다. 연구진은 사용자 환경과 과제를 자동으로 찍어내는 데이터 생성 파이프라인을 함께 공개했고, 이걸로 만든 2,000개 학습 환경에서 1,500개의 성공 사례를 모아 작은 모델 Qwen3.5-27B(Qwen3.5-27B)를 추가 학습시켰다. 그 결과 성공률이 23.7%포인트 올라, 27B짜리 작은 모델이 거대한 닫힌 모델들에 바짝 다가섰다. 한계를 측정하는 자가 동시에 한계를 좁히는 연료가 된 셈이다.
다만 이 결과가 곧바로 "이제 AI에게 내 모든 정보를 맡겨도 된다"는 뜻은 아니다. 최고 모델조차 같은 일을 세 번 모두 성공한 비율(Pass^3)은 20%에 그쳤기 때문에, 같은 일을 반복시켜도 안정적으로 해낼지는 두고 볼 필요가 있다. 지금 단계에서 분명한 것은, AI에게 더 넓은 권한을 줄수록 더 큰 편리함과 더 큰 불확실성이 함께 따라온다는 사실이다. 내 디지털 인생 전체를 비서에게 넘기기 전에, 그 비서가 정말 끝까지 일을 마무리할 수 있는지부터 따져볼 시점이다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q. Claw-Anything가 기존 AI 시험과 다른 점은 무엇인가요?
기존 시험은 단발성 심부름을 잘 처리하는지만 봤지만, Claw-Anything는 3개월치 활동기록과 수십 개 서비스, 여러 기기를 한꺼번에 주고 그 안에서 일을 끝내는지 평가합니다. 과제 하나의 정보량이 19만 단어에 달해 기존보다 수십 배 큽니다.
Q. GPT-5.5가 34.5%라는 건 실제로 얼마나 못한다는 뜻인가요?
열 번 시키면 예닐곱 번은 일을 끝내지 못한다는 의미입니다. 같은 모델이 더 쉬운 시험에서는 높은 점수를 받기 때문에, 이 숫자는 넓은 권한을 줬을 때 AI가 아직 미덥지 못하다는 신호로 볼 수 있습니다.
Q. 그럼 AI 비서에게 제 정보를 맡겨도 안전한가요?
아직은 신중할 필요가 있습니다. 최신 AI도 정보를 이해하고도 실제 실행에서 자주 실패했고, 같은 일을 세 번 모두 성공한 비율은 20%에 그쳤습니다. 편리함이 큰 만큼 안정성은 더 지켜봐야 하는 단계입니다.
기사에 인용된 리포트 원문은 arXiv에서 확인할 수 있다.
관련기사
- "LLM, 거짓 알면서도 사실처럼 말한다"…실험으로 드러난 ‘자신감 편향’2026.05.29
- 구글 AI 검색 반발에 덕덕고 설치 30% 급증… '강제 AI' 거부 확산2026.05.28
- AI 효과 본 한국 기업 75%, 그런데 '진짜 강자'는 단 2%뿐이었다2026.05.27
- 급한 불 끈 홈플러스...경영 정상화는 ‘산 넘어 산’2026.07.16
리포트명: Claw-Anything: Benchmarking Always-On Personal Assistants with Broader Access to User's Digital World
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)