







생성형 AI가 인간의 창의성을 따라잡았다는 말은 절반만 맞았다. 캐나다 몬트리올대학교와 인공지능 연구소 미라(Mila) 연구진이 인간 10만 명과 주요 AI 모델을 똑같은 창의력 시험으로 맞붙인 결과, GPT4는 평범한 사람의 평균 점수는 넘어섰지만 창의력 상위권 인간은 단 한 번도 이기지 못했다. 2026년 1월 국제 학술지 사이언티픽 리포트(Scientific Reports)에 실린 이 연구는, AI가 창의 노동을 곧 대체할 것이라는 불안이 적어도 지금은 이르다는 점을 데이터로 보여준다.
GPT4, 10만 명 규모로 확인된 평균 초과 창의력
몬트리올대 연구진이 발표한 보고서에 따르면 GPT4는 인간 10만 명의 평균 창의력 점수를 통계적으로 유의미한 차이로 넘어섰다. 연구진은 인간과 AI에게 똑같은 창의력 시험을 치르게 한 뒤 같은 방식으로 점수를 매겼다. 사용한 도구는 발산적 연결 과제(Divergent Association Task, DAT)다. 발산적 연결 과제란 서로 의미가 최대한 동떨어진 단어 10개를 떠올리게 한 뒤, 단어들 사이의 의미 거리를 컴퓨터로 계산해 창의성을 점수로 매기는 시험이다.예를 들어 '고양이, 강아지, 토끼'처럼 비슷한 단어를 적으면 점수가 낮고, '바다, 철학, 망치, 슬픔'처럼 서로 멀리 떨어진 단어를 적으면 점수가 높다. 멀리 떨어진 개념을 끌어와 연결하는 능력이 창의성의 핵심이라는 심리학 연구에 근거한 방식이다.
결과는 흥미로웠다. 핵심 비교에서 GPT4가 가장 높은 점수를 기록했고, 구글(Google)의 제미나이프로(GeminiPro)는 인간 평균과 통계적으로 구분되지 않는 수준이었다. 더 놀라운 건 비쿠나(Vicuna)라는 훨씬 작은 모델이 자신보다 덩치 큰 모델들을 앞섰다는 점이다. 모델이 크다고 무조건 창의적인 건 아니라는 뜻이다. 평범한 사람 입장에서 보면, 챗봇에게 "서로 다른 단어 열 개를 말해봐"라고 시켰을 때 평균적인 사람보다 더 동떨어진 단어를 내놓는 시대가 됐다는 이야기다.
상위 10퍼센트 인간은 모든 AI를 앞섰다는 반전
가장 중요한 발견은 따로 있다. 창의력 상위권 인간은 어떤 AI 모델도 이기지 못했다는 점이다. 연구진이 인간 응답을 상위 50퍼센트, 상위 25퍼센트, 상위 10퍼센트로 나눠 비교하자, 이들 상위 집단의 평균 점수는 GPT4를 포함한 모든 모델을 앞섰다. AI는 '평균적인 사람'은 넘었지만 '창의적인 사람'의 벽은 넘지 못한 것이다. 이 차이가 작아 보일 수 있지만, 작가나 시인, 편집자처럼 언어를 다루는 직업군이 몰려 있을 가능성이 높은 이 상위 구간에서 AI가 번번이 밀렸다는 사실은 의미가 크다.
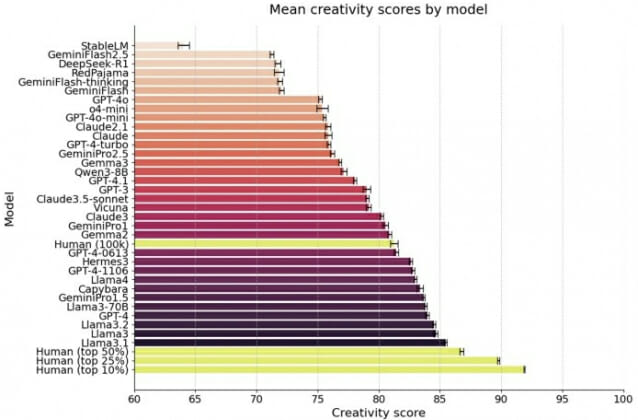
그림1. AI 모델과 인간 집단의 DAT 평균 창의력 점수 비교: 상위권 인간을 넘지 못하는 AI. (출처: Scientific Reports, 2026)
AI가 어디서 막히는지는 단어 선택 습관에서 드러난다. GPT4는 전체 응답의 70퍼센트에서 '현미경(microscope)'이라는 단어를, 60퍼센트에서 '코끼리(elephant)'를 반복해서 꺼냈다. 효율을 높인 후속 모델 GPT4터보(GPT4-turbo)는 더 심해서, 응답의 90퍼센트 이상에 '바다(ocean)'가 등장했다. 같은 질문을 받으면 거의 똑같은 단어를 다시 내놓는 것이다. 반면 인간은 가장 많이 고른 단어가 '자동차(car)'였는데도 그 비율이 1.4퍼센트에 불과했고, '개(dog)' 1.2퍼센트, '나무(tree)' 1.0퍼센트로 뒤를 이었다. 사람은 저마다 다른 단어를 떠올리지만, AI는 자기가 자신 있어 하는 몇 개 단어로 자꾸 돌아간다는 차이가 또렷하게 나타난 셈이다.
온도 조절과 전략 한 줄로 달라지는 AI 창의력
연구진은 AI의 창의력 점수가 설정과 지시 방식에 따라 크게 출렁인다는 사실도 확인했다. 핵심 변수는 '온도(temperature)'다. 온도란 AI가 다음 단어를 고를 때 얼마나 모험적으로 선택할지를 정하는 설정값으로, 높을수록 예측에서 벗어난 다양한 단어가 나오고 낮을수록 안전하고 뻔한 단어가 나온다. GPT4의 온도를 가장 높게 올리자 평균 점수가 85.6점까지 뛰었는데, 이는 인간 응답의 72퍼센트보다 높은 수준이었다. 온도를 올리니 같은 단어를 반복하는 빈도도 줄었다. AI의 창의력이 타고난 한계가 아니라 다이얼을 돌리듯 조정 가능한 영역이라는 뜻이다.
지시 방식, 즉 프롬프트도 큰 영향을 줬다. 연구진이 "단어의 어원을 다양하게 활용하는 전략으로 답하라"고 주문하자 GPT3.5와 GPT4 모두 기본 지시를 받았을 때보다 점수가 올라갔다. 반대로 "반대 의미의 단어를 쓰라"고 하자 점수가 떨어졌는데, '빛'과 '어둠'처럼 반대말은 사실 의미상 서로 가깝기 때문이다. 같은 AI라도 어떻게 말을 거느냐에 따라 결과물이 달라진다는 것은, 챗GPT를 쓰는 일반 사용자에게도 그대로 적용되는 실전 팁이다. 막연히 "창의적으로 써줘"라고 하기보다 구체적인 전략을 한 줄 덧붙이는 쪽이 더 나은 결과를 끌어낸다.
하이쿠와 짧은 소설 대결에서도 인간이 앞선 이유
단어 시험을 넘어 실제 글쓰기로 넘어가도 결론은 비슷했다. 연구진은 세 줄짜리 정형시 하이쿠(haiku), 영화 줄거리 요약, 200단어 이내의 초단편 소설인 플래시 픽션(flash fiction)을 AI에게 쓰게 한 뒤 의미의 다양성을 점수화했다. 인간 글은 별도로 쓰게 한 것이 아니라 기존 온라인 자료에서 가져왔는데, 하이쿠는 전문 하이쿠 사이트에서, 영화 줄거리는 영화 데이터베이스 TMDB에서 추출했다. AI들 사이에서는 GPT4가 세 형식 모두에서 GPT3.5를 앞섰지만, 인간 비교군이 있었던 하이쿠와 영화 줄거리 두 형식에서는 인간이 쓴 글이 두 모델을 통계적으로 의미 있는 차이로 앞섰다. 특히 별도 연구에 따르면 AI가 쓴 이야기는 전문 작가의 글에 비해 창의적 글쓰기 평가를 통과하는 비율이 3배에서 10배나 낮았다.
흥미로운 장면은 하이쿠에서 나왔다. 하이쿠는 전통적으로 자연을 소재로 삼는데, 인간이 쓴 하이쿠가 오히려 AI보다 의미의 다양성 점수가 높았다. 분석해 보니 인간은 '자연'이라는 관습적 규칙에서 더 자유롭게 벗어났기 때문이었다. AI는 배운 규칙을 충실히 지키느라 비슷한 틀에 머물렀고, 사람은 규칙을 살짝 깨면서 예상 밖의 표현을 만들어냈다. 정해진 틀을 넘어서는 일탈, 바로 그 지점이 아직 인간의 영역이라는 점을 보여주는 대목이다.
창의 직군 대체론, 아직은 이른 이유
이번 연구가 던지는 메시지는 'AI 창의력 위협론'을 데이터로 다시 보게 만든다. 연구진은 GPT4가 이전 모델보다 창의적이라는 오픈AI(OpenAI)의 주장은 사실로 확인됐지만, 가장 까다로운 창의 작업을 맡는 직군이 현재의 AI로 대체될 가능성은 낮다고 봤다. 평균을 넘는 것과 정상급을 넘는 것은 전혀 다른 문제이고, 상위권 인간과 최고 성능 AI 사이의 간격은 기술이 빠르게 발전하는 와중에도 좀처럼 좁혀지지 않았기 때문이다.
다만 이 결과를 'AI는 창의적이지 않다'로 단순화하기는 이르다. 연구가 측정한 것은 창의성의 한 측면인 '의미의 발산', 즉 멀리 떨어진 개념을 끌어오는 능력에 한정된다. 또 AI는 온도와 프롬프트만 바꿔도 점수가 크게 오르는 만큼, 사람이 잘 다룰수록 더 나은 결과를 끌어낼 여지가 크다. 연구진 역시 경쟁보다 협업 가능성에 주목하며, AI가 초보 작가의 번역과 수정 작업을 효과적으로 돕는다는 후속 연구를 함께 소개했다. 결국 지금 시점에서 더 현실적인 질문은 'AI가 사람을 대체하느냐'가 아니라 '사람이 AI를 얼마나 잘 부리느냐'일 가능성이 있다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q. 발산적 연결 과제(DAT)는 정확히 어떤 시험인가요?
A. 서로 의미가 최대한 다른 단어 10개를 떠올려 적는 시험입니다. 컴퓨터가 단어들 사이의 의미 거리를 계산해 점수를 매기며, 멀리 떨어진 단어를 많이 적을수록 창의력 점수가 높게 나옵니다. 보통 50점에서 100점 사이로 나옵니다.
Q. 그래서 GPT4가 사람보다 창의적이라는 건가요?
A. 평균적인 사람보다는 점수가 높았지만, 창의력 상위 10퍼센트 인간은 어떤 AI도 이기지 못했습니다. 평범한 다수는 넘어섰으나 정상급 인간의 벽은 넘지 못했다고 이해하시면 됩니다.
Q. 챗GPT에게 더 창의적인 답을 받으려면 어떻게 해야 하나요?
A. 막연히 "창의적으로 써달라"고 하기보다, "단어의 어원을 다양하게 활용해서"처럼 구체적인 전략을 한 줄 덧붙이면 결과가 좋아진다는 점이 연구에서 확인됐습니다. 설정에서 온도(temperature) 값을 높이는 것도 더 다양한 표현을 끌어내는 방법입니다.
기사에 인용된 리포트 원문은 Scientific Reports에서 확인할 수 있다.
관련기사
- '팔로워 2만명' 수천만 인플루언서 눌렀다…AI 검색 인용 글의 의외 공통점2026.05.28
- 구글 AI 검색 반발에 덕덕고 설치 30% 급증… '강제 AI' 거부 확산2026.05.28
- 앤트로픽 '미토스' 곧 나오나…클로드 코드에 모델 토글 잠깐 노출2026.05.27
- SK하이닉스, 용인 'Y1' 팹 구축 본격화…장비 발주 시작2026.07.14
리포트명: Divergent creativity in humans and large language models (Scientific Reports, 2026, 16:1279)
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)





