







칭화대학교(Tsinghua University)와 상하이기지연구소(Shanghai Qizhi Institute) 연구진이 사람의 일상 영상만으로 로봇 손에게 복잡한 도구 사용법을 가르치는 AI 시스템 '유니덱스(UniDex)'를 개발했다. 이 시스템은 5만 개 이상의 인간 손동작 영상을 8가지 다른 형태의 로봇 손 데이터로 변환해 학습시킨 결과, 봉지 자르기, 꽃에 물 주기, 커피 내리기 같은 까다로운 작업에서 평균 81%의 성공률을 기록했다. 특히 한 번도 학습하지 않은 로봇 손으로도 기술을 전이할 수 있어, 로봇 손 제어 분야의 새로운 전환점이 될 것으로 보인다.
인간 영상으로 해결한 로봇 데이터 수집 비용 문제
로봇에게 사람처럼 손을 쓰도록 가르치는 일은 AI 연구의 오랜 숙제였다. 특히 집게형 그리퍼(gripper)가 아닌 다섯 손가락을 가진 정교한 로봇 손은 제어가 훨씬 어렵다. 연구진이 논문 서론(Introduction)에서 밝힌 바에 따르면, 로봇 손 학습의 가장 큰 장애물은 세 가지다. 첫째, 실제 로봇으로 데이터를 모으는 일이 비싸고 느리다. 둘째, 로봇 손마다 관절 개수와 생김새가 천차만별이라 한 로봇에서 배운 기술을 다른 로봇에 적용하기 어렵다. 셋째, 로봇 손은 관절이 6개에서 24개까지 다양해 제어 차원이 매우 높다.
연구진은 이 문제를 정면돌파하는 대신 우회로를 택했다. 바로 인간의 일상 영상을 활용하는 것이다. 사람은 매일 수많은 물건을 집고, 돌리고, 사용하며, 요즘은 1인칭 시점 카메라로 이런 장면을 대량으로 촬영한 공개 데이터셋이 존재한다. 연구진은 H2O, HOI4D, HOT3D, TACO 등 네 가지 인간 조작 영상 데이터셋을 활용해 총 5만 개 이상의 궤적(trajectory)을 수집했다. 이는 로봇 원격조작으로 모으려면 수년이 걸릴 분량이다.
하지만 사람 손과 로봇 손은 생김새도 다르고 움직이는 방식도 다르다. 이를 '운동학적(kinematic) 격차'와 '시각적(visual) 격차'라고 부른다. 연구진은 이 두 격차를 메우기 위해 독창적인 변환 파이프라인을 설계했다. 먼저 사람 손을 영상에서 지우고, 로봇 손을 같은 위치에 합성한다. 그다음 사람 손가락 끝의 궤적을 추적해 로봇 손가락 끝이 같은 경로를 따라가도록 역운동학(inverse kinematics)을 적용한다. 이 과정에서 사람이 직접 개입해 슬라이더 바를 조정하며 로봇 손이 물체와 자연스럽게 접촉하도록 미세 조정한다. 이를 '휴먼-인-더-루프 리타게팅(human-in-the-loop retargeting)'이라고 부른다.
8가지 로봇 손을 하나로 묶는 공통 언어, FAAS 개념
로봇 손마다 관절 개수와 구조가 다르다는 문제는 어떻게 해결했을까? 연구진은 '기능-작동기 정렬 공간(Function-Actuator-Aligned Space, FAAS)'이라는 개념을 고안했다. 이는 마치 서로 다른 언어를 쓰는 사람들이 공통 번역 언어를 사용하는 것과 비슷하다. 예를 들어 엄지손가락을 움직이는 모터는 로봇마다 다르지만, 모두 '엄지를 벌리거나 오므리는' 기능을 한다. FAAS는 이런 기능적으로 유사한 작동기들을 같은 좌표에 매핑한다.
논문 방법론(Method) 섹션에 따르면, FAAS는 로봇 손의 관절을 '기능 그룹'으로 묶는다. 손목 회전, 엄지 벌림, 검지 굽힘 등 각 기능마다 하나의 좌표를 할당하고, 해당 기능을 담당하는 모터가 여러 개라면 그 값을 분배한다. 이렇게 하면 관절이 6개인 간단한 로봇 손과 24개인 복잡한 로봇 손이 같은 '언어'로 명령을 받을 수 있다. 실제로 연구진은 8가지 서로 다른 로봇 손에 FAAS를 적용했고, 이들 모두가 같은 데이터셋으로 학습할 수 있었다.

이미지 2. 유니덱스 데이터셋 시각화
이 통일된 행동 공간 덕분에 한 로봇 손에서 학습한 기술을 다른 로봇 손으로 전이하는 것이 가능해졌다. 마치 한국어를 배운 사람이 영어 문법을 조금만 익히면 영어로도 같은 생각을 표현할 수 있는 것처럼, FAAS를 통해 로봇 손들은 서로의 경험을 공유할 수 있게 된 것이다.
900만 프레임 학습 후 81% 성공률을 기록한 유니덱스
연구진이 구축한 유니덱스-데이터셋(UniDex-Dataset)은 총 900만 개의 이미지-포인트클라우드-행동 프레임으로 구성됐다. 이는 8가지 로봇 손에 대해 각각 5만 개 이상의 궤적을 포함하는 규모다. 논문 결과(Results) 섹션에 따르면, 이 데이터셋으로 사전학습한 유니덱스-VLA(UniDex-VLA) 모델은 실제 로봇 실험에서 놀라운 성능을 보였다.
연구진은 여섯 가지 까다로운 도구 사용 작업으로 모델을 평가했다. 가위로 과자 봉지 자르기, 스프레이로 꽃에 물 주기, 주전자로 커피 내리기, 빗자루로 물건 쓸기, 마우스 드래그 및 클릭하기 등이다. 이 작업들은 단순히 물체를 집는 것을 넘어 도구를 정확한 각도와 힘으로 조작해야 하므로, 집게형 그리퍼로는 거의 불가능하다. 유니덱스-VLA는 이들 작업에서 평균 81%의 작업 진행률(task progress)을 기록했으며, 기존 VLA 기준 모델들을 큰 차이로 앞질렀다.
더 흥미로운 점은 일반화 능력이다. 연구진은 모델이 학습 중 본 적 없는 새로운 위치, 새로운 물체, 심지어 새로운 로봇 손에서도 작동하는지 테스트했다. 결과는 긍정적이었다. 예를 들어 봉지 자르기 작업에서 학습 때와 다른 위치에 봉지를 놓아도 성공률이 크게 떨어지지 않았고, 다른 색상이나 크기의 봉지를 사용해도 작동했다. 가장 놀라운 것은 제로샷 크로스-핸드 전이(zero-shot cross-hand transfer)다. 한 로봇 손으로 학습한 모델을 전혀 다른 구조의 로봇 손에 적용했을 때도 상당한 성공률을 보인 것이다. 이는 FAAS가 실제로 로봇 간 기술 전이를 가능하게 한다는 증거다.
스마트폰 영상으로 로봇을 훈련하는 유니덱스-캡의 가능성
연구진은 여기서 한 걸음 더 나아갔다. 유니덱스-캡(UniDex-Cap)이라는 간단한 촬영 장비를 개발한 것이다. 이는 RGB-D 카메라(색상과 깊이 정보를 동시에 촬영하는 카메라)와 손 추적 센서를 결합한 휴대용 시스템으로, 사람이 일상적인 조작을 수행하는 모습을 촬영하면 자동으로 로봇 실행 가능한 궤적으로 변환해준다.
논문의 실험(Experiments) 섹션에서 연구진은 흥미로운 비교 실험을 진행했다. 순수하게 로봇 원격조작 데이터만으로 학습한 모델과, 유니덱스-캡으로 촬영한 인간 영상 데이터를 함께 학습한 모델을 비교한 것이다. 결과는 명확했다. 인간 데이터를 함께 사용하면 같은 성능을 달성하는 데 필요한 로봇 데이터 양을 크게 줄일 수 있었다. 로봇 원격조작은 전문 장비와 숙련된 조작자가 필요해 비용이 많이 든다. 하지만 사람이 직접 손으로 작업하는 모습을 촬영하는 것은 훨씬 쉽고 저렴하다. 유니덱스-캡 같은 시스템이 있다면, 로봇 연구자가 아닌 일반인도 로봇 학습 데이터 생성에 기여할 수 있다. 마치 유튜브가 누구나 영상 제작자가 될 수 있게 만든 것처럼, 유니덱스는 누구나 로봇 교육자가 될 수 있는 길을 열어준다.
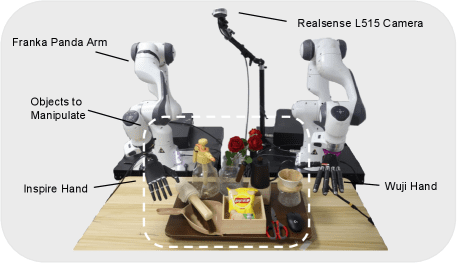
이미지 5. 리얼 월드 실험 셋업
산업·의료·가정까지 확산되는 로봇 손 민주화
이 연구의 의미는 단순히 로봇 손 제어 성능을 높인 것을 넘어선다. 연구진이 논문 결론(Conclusion)에서 강조하듯, 유니덱스는 세 가지 요소를 하나의 '파운데이션 스위트(foundation suite)'로 통합했다. 대규모 사전학습 데이터셋(UniDex-Dataset), 통합 VLA 정책(UniDex-VLA), 그리고 실용적인 데이터 수집 도구(UniDex-Cap)가 그것이다. 이 세 요소가 함께 작동하면서 로봇 손 기술의 진입 장벽을 크게 낮췄다.
현재 대부분의 로봇 팔은 집게형 그리퍼를 사용한다. 이는 제어가 간단하고 안정적이지만, 할 수 있는 작업이 제한적이다. 봉지 자르기, 마우스 조작, 악기 연주 같은 섬세한 작업은 불가능하다. 반면 정교한 로봇 손은 이런 작업을 할 수 있지만, 지금까지는 학습 데이터 부족과 제어 복잡성 때문에 연구실 밖으로 나가기 어려웠다. 유니덱스는 이 상황을 바꿀 잠재력을 가졌다.
제조업 현장에서는 복잡한 조립 작업에, 의료 분야에서는 수술 보조에, 가정에서는 요리나 청소 같은 일상 작업에 정교한 로봇 손이 활용될 수 있다. 특히 고령화 사회에서 노인이나 장애인을 돕는 보조 로봇은 사람 손처럼 섬세하게 움직일 수 있어야 한다. 컵을 집어 물을 따르고, 약병 뚜껑을 열고, 옷의 단추를 채우는 일 모두 정교한 손 제어가 필요하다.
연구진은 유니덱스를 오픈소스로 공개할 계획이며, 다른 연구자들이 새로운 로봇 손이나 인간 데이터셋을 추가할 수 있는 프로토콜도 제공한다. 이는 커뮤니티 전체가 함께 데이터셋을 키우고 모델을 개선할 수 있는 구조다. 마치 위키피디아가 집단 지성으로 성장한 것처럼, 유니덱스도 전 세계 연구자와 개발자의 기여로 계속 발전할 수 있다.
물론 한계도 있다. 현재 유니덱스는 주로 도구 사용에 초점을 맞췄고, 물체를 손 안에서 회전시키는 '인-핸드 매니퓰레이션(in-hand manipulation)' 같은 더 복잡한 작업은 아직 완벽하지 않다. 또한 인간 영상을 로봇 데이터로 변환하는 과정에서 여전히 사람의 개입이 필요하다. 하지만 이런 한계들은 기술이 발전하면서 점차 해결될 것으로 보인다. 유니덱스가 제시한 방향은 명확하다. 로봇 손 기술은 더 이상 소수 연구실의 전유물이 아니라, 대규모 데이터와 범용 AI 모델로 누구나 접근할 수 있는 기술이 되어야 한다는 것이다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. 유니덱스는 기존 로봇 손 학습 방법과 어떻게 다른가요?
A. 유니덱스는 비싼 로봇 원격조작 데이터 대신 일상 속 인간 손동작 영상을 활용합니다. 사람 손을 영상에서 지우고 로봇 손을 합성한 뒤, 손가락 끝 궤적을 추적해 로봇이 따라하도록 변환합니다. 이를 통해 5만 개 이상의 대규모 학습 데이터를 구축했으며, 8가지 서로 다른 로봇 손에 모두 적용할 수 있는 통합 학습 시스템을 만들었습니다.
Q2. FAAS가 왜 중요한가요?
A. FAAS는 관절 개수와 구조가 다른 로봇 손들을 하나의 공통 언어로 제어할 수 있게 만드는 개념입니다. 엄지 벌림, 검지 굽힘 같은 기능별로 좌표를 할당해, 6개 관절 로봇과 24개 관절 로봇이 같은 명령을 이해할 수 있습니다. 덕분에 한 로봇에서 배운 기술을 다른 로봇으로 전이할 수 있어, 로봇 간 지식 공유가 가능해집니다.
Q3. 일반인도 로봇 학습 데이터를 만들 수 있나요?
A. 연구진이 개발한 유니덱스-캡은 RGB-D 카메라와 손 추적 센서를 결합한 휴대용 장비로, 사람이 일상 작업을 수행하는 모습을 촬영하면 자동으로 로봇 실행 가능한 데이터로 변환합니다. 인간 영상 데이터를 함께 사용하면 필요한 로봇 시연 횟수를 크게 줄일 수 있어, 데이터 수집 비용을 대폭 낮출 수 있습니다.
기사에 인용된 논문 원문은 arXiv에서 확인할 수 있다.
논문명: UniDex: A Robot Foundation Suite for Universal Dexterous Hand Control from Egocentric Human Videos
관련기사
- 8만 명이 AI에게 원하는 것은 더 나은 삶이었다2026.03.25
- TV에 질문하고 학습한다… 구글 TV, 제미나이 AI로 스포츠·뉴스·교육 강화2026.03.25
- 버니 샌더스 vs 클로드, 샌더스가 AI의 아첨 성향을 이끌어내다2026.03.24
- 미 국방부 "앤트로픽 클로드 6개월 내 대체" 자신…현장 군인들은 반발2026.03.23
이미지 출처: AI 생성 콘텐츠
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)





