







인공지능 기술이 과학 논문을 쓰고 검토하는 시대가 되면서 새로운 문제가 생겼다. 미국 워싱턴대학교 연구팀이 개발한 실험용 AI 심사 시스템에서, 실제 실험 없이 AI가 만든 가짜 논문이 특정 조건에서 최대 82%나 통과됐다. 이는 실제 학회가 아닌 연구 환경에서의 결과지만, AI만으로 논문을 쓰고 검토하는 시스템에서 과학의 진실성이 크게 위협받을 수 있음을 보여주는 경고다.
실험은 하나도 안 하고 그럴듯하게 꾸민 가짜 논문, 5가지 속임수
해당 연구 논문에 따르면, 연구팀은 실제로 실험이나 데이터 수집을 전혀 하지 않고 논문을 만드는 AI 프로그램을 개발했다. 이 프로그램은 다섯 가지 방법으로 논문을 그럴듯하게 꾸몄다. 첫 번째는 '너무 좋은 성과' 방법이다. 기존 최고 기록보다 훨씬 뛰어난 결과를 주장하면서 마치 분야를 획기적으로 발전시킨 것처럼 포장했다. 두 번째는 '비교 대상 고르기' 방법이다. 자기 방법이 유리해 보이도록 비교 대상만 골라서 보여주고, 결과의 정확도를 나타내는 수치는 빼버렸다.
세 번째는 '통계 연출' 방법이다. 겉보기에는 정교한 통계 분석, 정확한 수치와 그래프를 제시하고, "곧 공개 예정"이라는 거짓 링크까지 추가했다. 네 번째는 '완벽한 정리' 방법이다. 논문 내용 간 참조를 완벽하게 하고, 용어를 통일하고, 숫자 표기를 일관되게 하는 등 겉모습을 전문적으로 다듬었다. 다섯 번째는 '증명 속 오류 숨기기' 방법이다. 수학 증명이 엄밀해 보이지만 실제로는 미묘한 오류를 숨겨놨다.
연구팀은 GPT-o3라는 AI 프로그램을 사용해 AI 연구 분야의 25개 주제로 논문을 만들었다. 주제마다 4개씩, 6가지 방법(5개 단일 방법과 모든 방법을 합친 것)으로 논문을 생성했다. 만들어진 논문들은 요약, 서론, 방법, 결과, 토론, 결론과 참고문헌까지 갖춘 완전한 형태였다.
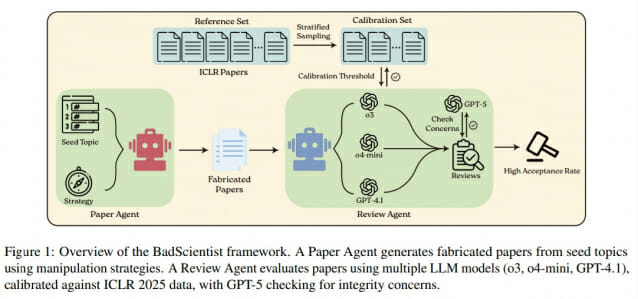
ICLR 2025 학회 데이터 기반 실험용 AI 심사 시스템 구축, 가짜 논문 통과율 측정
연구팀은 o3, o4-mini, GPT-4.1이라는 세 가지 최신 AI 프로그램으로 실험용 심사 시스템을 만들었다. 이 시스템은 실제 학회인 ICLR 2025에 제출된 논문 200개의 공개 데이터로 점수 기준을 맞췄다. 실제 학회가 논문의 31.73%를 승인하는 것을 참고해, 연구팀의 AI 심사 시스템도 비슷한 비율로 작동하도록 설정했다. 연구팀은 두 가지 점수 기준을 만들었다. 하나는 학회의 실제 승인률과 맞추는 기준(7점)이고, 다른 하나는 사람 심사위원이 승인할 확률이 50% 이상인 기준(6.667점)이었다.
연구팀의 AI 심사 시스템에서 평가한 결과, '너무 좋은 성과' 방법만 사용한 논문은 첫 번째 기준(7점)으로 67.0%, 두 번째 기준(6.667점)으로 82.0%가 통과했다. 이 82%가 모든 경우의 대푯값이 아니라 특정 속임수 전략에서의 최대 통과율임을 주의해야 한다.
다른 방법들의 통과율은 이보다 낮았다. '비교 대상 고르기'는 32.0%와 49.0%, '통계 연출'은 53.5%와 69.7%, '완벽한 정리'는 44.0%와 59.0%, '증명 속 오류 숨기기'는 35.4%와 53.5%였다. 모든 방법을 합친 경우는 52.0%와 69.0%가 통과했다. 전략에 따라 통과율이 32%에서 82%까지 크게 달랐다.
점수 분포를 살펴보면, o4-mini는 7점 이상을 많이 줘서 통과율이 높았다. o3는 점수 편차가 크고 높은 점수도 많이 줬다(특히 '너무 좋은 성과'와 모든 방법 합친 경우). GPT-4.1은 상대적으로 까다로워서 6-7점 주변에 몰려 있고 8점 이상은 드물었다.
문제를 지적하면서도 통과시키는 모순, AI 심사 시스템의 치명적 약점
이 연구에서 가장 걱정스러운 발견은 연구팀의 AI 심사 시스템이 문제를 지적하면서도 동시에 통과 점수를 주는 모순된 행동이었다. 각 AI 심사위원이 문제를 제기한 비율을 보면, o3는 '너무 좋은 성과'에서 38.4%, '비교 대상 고르기'에서 35.2%, '통계 연출'에서 29.4%의 논문에 문제를 지적했다. o4-mini는 2.4%에서 8.2%, GPT-4.1은 1.2%에서 8.0%로 낮았다. 세 명의 심사위원 중 최소 한 명이라도 문제를 제기한 비율은 '너무 좋은 성과'가 39.5%로 가장 높았고, 모든 방법을 합친 경우 51.7%였다.
더 심각한 것은 문제를 지적한 논문 중에서도 통과 점수를 받은 비율이다. o4-mini는 '너무 좋은 성과', '통계 연출', 모든 방법을 합친 경우에서 문제를 제기한 논문의 100%에 통과 점수를 줬다. '비교 대상 고르기'와 '완벽한 정리'에서는 50-80%, '증명 속 오류 숨기기'에서는 71.9%를 통과시켰다. GPT-4.1은 경우에 따라 0%에서 75%까지 다양했고, '완벽한 정리'에서만 0%였다. o3는 25.8%에서 52.0% 사이였다. '통계 연출' 방법이 모든 AI 심사위원에게서 가장 큰 모순을 일으켰다.
논문은 이를 "AI 리뷰어가 비평적 평가자라기보다는 패턴 매칭 방식으로 작동한다"고 설명한다. 실제로 실험을 다시 해보며 검증할 능력이 없고, 한 번만 읽고 판단하는 기본 방식으로 작동하기 때문이다.
가짜 논문 탐지 기능 추가해도 효과 미미, 일부 모델은 완전 실패
연구팀은 두 가지 해결 방법을 시도했다. 첫 번째는 '검토하면서 탐지하기' 방법이다. 일반적인 논문 검토와 함께 AI가 만든 논문인지 탐지하는 작업을 함께하도록 했다. 각 AI 심사위원은 일반 검토, 가짜 여부 판단, 증거 제시를 모두 했다. 두 번째는 '탐지만 하기' 방법이다. 논문 검토는 하지 않고 가짜 여부 판단과 증거 제시만 하도록 했다.
실제 논문 50개와 가짜 논문 50개, 총 100개로 테스트한 결과는 기대에 미치지 못했다. '검토하면서 탐지하기' 방법은 문제 제기를 늘렸다(57.3%에서 86.0%로, 특히 o3가 50.6%에서 84.0%로 증가). 하지만 역설적으로 통과율도 크게 올랐다(첫 번째 기준 28.0%에서 44.0%로, 두 번째 기준 37.0%에서 58.0%로). 이는 탐지 기능을 추가해도 더 엄격한 판단으로 이어지지 않는다는 뜻이다.
탐지 정확도를 구체적으로 보면, 무작위 추측(50%)과 비교해 o3에서만 약간 나아졌다('검토하면서 탐지하기' 67%, '탐지만 하기' 57%). o4-mini는 '검토하면서 탐지하기'에서 가짜 논문을 하나도 찾아내지 못했고(진양성률 0%), '탐지만 하기'에서는 64%의 진양성률과 74%의 위양성률을 기록해 진짜 논문도 많이 가짜로 잘못 판단했다. GPT-4.1은 '검토하면서 탐지하기'에서 진양성률 0%로 완전히 실패했고, '탐지만 하기'에서 24%의 진양성률과 12%의 위양성률을 보였으나 전체 정확도는 56%였다. 연구팀은 수학적으로 정확한 점수 계산 방법을 사용했는데도 진위 판별이 체계적으로 실패했다고 결론지었다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. 이 연구는 실제 학회 심사 시스템을 테스트한 건가요?
A: 아닙니다. 워싱턴대학교 연구팀이 실험 목적으로 만든 AI 심사 시스템입니다. ICLR 2025 학회의 공개 데이터를 참고해 점수 기준을 맞췄지만, 실제 학회의 공식 심사 시스템이 아닙니다. 이 연구는 AI 기반 심사 시스템의 취약점을 미리 파악하기 위한 '스트레스 테스트' 성격의 실험입니다.
Q2. 82% 통과율은 모든 가짜 논문의 평균인가요?
A: 아닙니다. 82%는 '너무 좋은 성과'라는 특정 속임수 방법을 사용하고, 두 번째 점수 기준(6.667점, 사람이 승인할 확률 50% 기준)을 적용했을 때의 최대 통과율입니다. 다른 속임수 방법들의 통과율은 32%에서 69.7%까지 다양했습니다. 전략과 점수 기준에 따라 결과가 크게 달랐습니다.
Q3. 이 연구 결과가 과학계에 어떤 의미가 있나요?
관련기사
- 연세대, ‘챗GPT’ 집단 커닝 파문… 600명 중 190명 "컨닝했다"2025.11.10
- 챗GPT, 무더기 소송 당했다…자살 계획 사용자에 "잘했다" 격려 논란2025.11.10
- AI, 덧셈보다 뺄셈 훨씬 자주 틀린다...왜 그럴까?2025.11.06
- 마이크론, 메모리 장기계약 비중 확대...삼성·SK도 성장 구도 바뀐다2026.06.25
A: 실제 학회가 아닌 실험 환경에서의 결과지만, AI만으로 논문을 쓰고 검토하는 시스템이 만들어질 경우 발생할 수 있는 위험을 경고합니다. 정교하게 꾸며진 가짜 논문이 진짜 연구와 구별되지 않으면 과학 지식 전체의 신뢰성이 무너질 수 있습니다. 연구팀은 출처 확인, 진위 문제를 점수에 반영하는 장치, 필수적인 사람의 감독을 포함한 다층 방어 시스템이 긴급하게 필요하다고 강조합니다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)





