






한국정보통신기술협회(TTA)는 생성형 AI의 학습 생성 과정을 검증하기 위한 벡터 유사도 기반 콘텐츠 검증 지침을 표준화한다고 27일 밝혔다.
표준은 검증의 기준이 되는 ‘참조 데이터셋’과 분석 대상인 ‘AI 생성 콘텐츠’에서 각각 특징 벡터를 추출해 비교하는 방식을 제시한다.
참조 데이터는 작가별 그림체 또는 선정적 폭력적 콘텐츠 등 검증에 활용 가능한 유사 데이터로 구성한다. 참조 데이터셋에서 특징 벡터를 추출해 참조 벡터 DB에 등록하고, AI의 콘텐츠 생성 과정에서 생성되는 특징 벡터와 코사인 유사도를 계산한다. 이때, 유사도가 임계값을 초과하면 해당 콘텐츠가 참조 데이터셋의 영향을 받아 생성된 것이라고 판단한다.
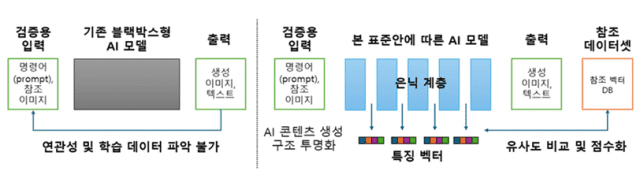
이를 통해 저작권 분쟁 발생 시에는 AI 생성 콘텐츠가 특정 작가의 작품을 무단 학습했는지를 입증하는 근거 등으로 활용할 수 있다. 또한, 유사도가 높은 참조 데이터가 선정적 폭력적 콘텐츠인 경우에는 유해 콘텐츠로 판단하고 사전에 차단할 수 있다.
이번 표준은 한국전자기술연구원, 다차원영상기술표준화포럼이 제안 문화체육관광부 ‘악의적 활용을 차단하는 생성형 AI 모델을 탑재한 콘텐츠 창작 및 공유 플랫폼 기술 개발’, ‘저작권 보호를 위한 멀티모달 생성형 AI 모델의 데이터셋 저작권 판별 기술’ 과제의 일환으로 제안돼 TTA 메타버스 콘텐츠 프로젝트그룹(PG610)에서 연내 제정 목표로 추진 중이다.
관련기사
- TTA, 차세대 3D 오디오 표준기술 시험검증2025.10.23
- 세계 최초 AAM 사실표준화기구 ‘G3AM’, 제1차 총회 개최2025.10.21
- TTA, 친환경 고효율 AI DC 테스트베드 실증2025.10.15
- TTA, SaaS 기업 일본 진출 로드맵 논의2025.09.26
PG610은 앞서 불법촬영 음란영상물 필터링을 위한 특징 데이터베이스 제작 지침 등 디지털 콘텐츠 관련 200여 건의 표준을 제정한 바 있다.
손승현 TTA 회장은 “AI가 학습하는 데이터와 생성하는 콘텐츠는 디지털 사회의 핵심 자원이자 중요한 비즈니스 모델이 될 것”이라며 “TTA는 AI의 악의적 활용을 방지하고 안전한 디지털 콘텐츠 생태계 조성에 앞장서겠다”고 말했다.





