






"기업이 인공지능(AI) 효과를 보려면 데이터를 AI가 잘 이해할 수 있게 만들어야 합니다. 이를 위해 사내 흩어진 데이터를 한곳으로 모아 품질을 높여야 합니다. '왓슨x' 플랫폼은 이런 AI 레디 데이터 전략으로 AI 애플리케이션이 높은 정확도와 품질을 유지하게 돕습니다."
한국IBM 이지은 최고기술책임자(CTO) 겸 테크 세일즈 리더는 16일 그랜드 인터컨티넨탈 서울 파르나스 호텔에서 열린 'IBM AI 서밋 코리아'에서 AI 비즈니스 활성화를 위한 데이터 전략을 이같이 밝혔다. 데이터가 AI에 바로 활용될 수 있게 구축돼야 비즈니스 성과를 창출할 수 있다는 설명이다.
AI 레디 데이터는 생성형 AI 학습·운영에 최적화된 데이터다. 정확하고 효율적인 AI 모델을 구축·운영하기 위해 데이터 품질과 정합성, 규모 등을 미리 확보한 상태를 의미한다. 기업이 이를 실현하려면 단순히 많은 양의 데이터를 모으는 것뿐 아니라 AI 모델이 잘 학습하고 정확한 결과물을 생성할 수 있도록 데이터를 정체, 가공, 라벨링 하는 과정까지 거쳐야 한다.

이 리더는 기업이 AI 레디 데이터 구축에 어려움을 겪고 있다고 지적했다. 그는 "다수 기업 데이터는 비정형"이라며 "이는 기업 데이터 전체 90% 이상을 차지한다"고 설명했다. 이어 "이중 AI 모델에 들어가는 데이터는 1% 미만"이라며 "데이터 품질 문제와 복잡한 저장소 구조가 걸림돌"이라고 지적했다.
이후 한국IBM 이호승 데이터 플랫폼 테크 세일즈 총괄 전무는 AI 레디 데이터 환경 구축을 위한 전략으로 '왓슨x' 플랫폼 기반 '데이터 통합'과 '데이터 인텔리전스'를 제시했다. 기업 내 흩어진 데이터를 한곳으로 통합하고 품질을 높여야 AI 비즈니스 효과를 극대화할 수 있다는 이유에서다.
우선 데이터 통합에서는 여러 출처 데이터를 수집해 AI가 이해할 수 있는 형태로 저장하는 과정을 거친다. 이 상무는 "기업 데이터는 온프레미스 서버에 있는 비정형 데이터나 클라우드 환경에 저장된 정형 데이터, 실시간으로 생성되는 스트리밍 데이터 등으로 분산됐다"며 "왓슨x는 이 모든 데이터를 연결해 한 곳에 모아 관리할 수 있도록 지원한다"고 설명했다.
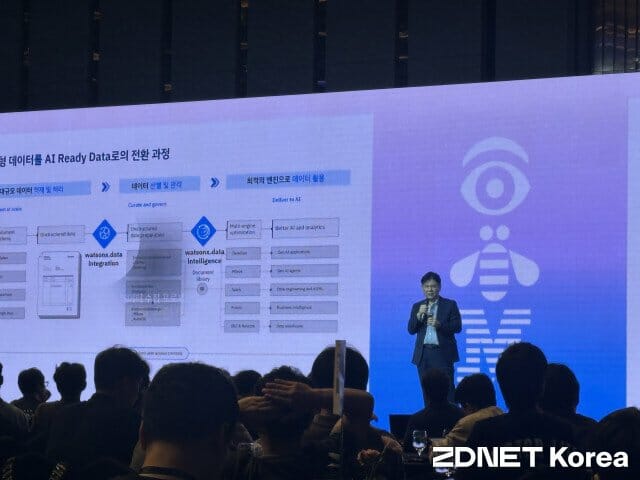
우선 왓슨x 플랫폼은 수집된 데이터를 AI가 바로 읽고 학습할 수 있는 구조로 변환한다. 단순히 저장하는 수준이 아니라, AI 모델 학습과 추론에 최적화된 형태로 정리할 수 있다는 설명이다.
이후 플랫폼은 데이터 인텔리전스 과정을 거친다. 여기서 데이터 오류를 자동 수정하고, 의미 단위로 변환한다. 이때 이름, 성함 등 동일한 의미의 서로 다른 표현도 한 항목으로 묶어 일관성을 확보한다. 또 개인정보나 보안 관련 데이터를 자동 탐지해 마스킹 처리하고, 욕설이나 불필요한 노이즈 데이터를 제거한다.
관련기사
- IBM이 제시한 AI 에이전트 시대 전략은…"'왓슨x'가 해법"2025.09.16
- IBM, 양자컴퓨터 최대 약점 '노이즈' 오히려 계산에 쓴다2025.09.14
- IBM, 동아대병원 DX 기술 지원…"의료 데이터 분석·업무 효율↑"2025.09.02
- "테니스 경기장에 신기술"…IBM, US 오픈에 AI 서비스 공급2025.08.29
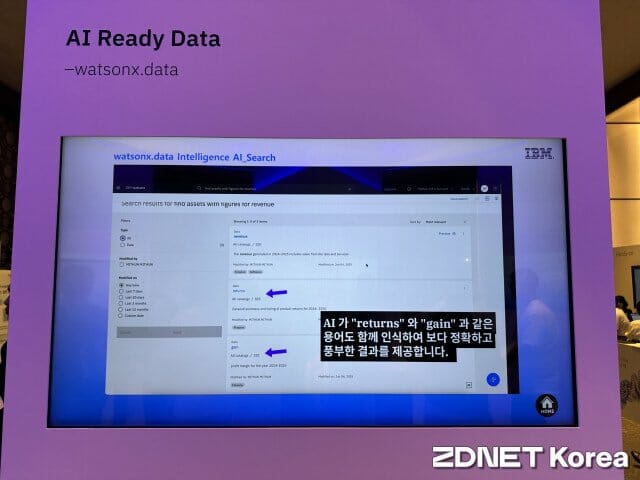
또 기업마다 사용하는 고유 용어나 내부 코드도 맞춤형으로 묶는다. 이 상무는 "데이터 인텔리전스 과정에서 이런 용어를 수동 큐레이션 해 표준화한다"며 "AI가 해당 기업 맥락을 더 정확히 이해하도록 만든다"고 강조했다.
이어 "이렇게 정제된 데이터셋은 벡터화·임베딩 과정을 거쳐 AI 애플리케이션에 들어간다"며 "결과적으로 AI 애플리케이션이 더 신뢰성 높은 답변을 내고, 기업 맞춤형 인사이트를 도출할 수 있다"고 설명했다.





