






올거나이즈가 거대언어모델(LLM) 성능 평가 플랫폼을 선보여 기업이 최적의 인공지능(AI) 모델을 선택하도록 돕는다.
올거나이즈는 문제 해결을 위해 자율적으로 행동하는 AI 에이전트의 성능을 평가하는 국내 최초 플랫폼으로서 '올인원 벤치마크'를 출시했다고 3일 밝혔다. 이는 지난해 선보인 금융 전문 LLM 리더보드에서 한 단계 발전한 형태로, LLM의 다양한 역량을 종합적으로 분석하고 대시보드 형태로 결과를 제공한다.
올인원 벤치마크는 LLM이 에이전트 역할을 수행하기 위해 필요한 도구 선택 및 활용 능력, 대화의 맥락 이해, 정보 수집 및 활용 능력 등을 평가한다. 현재 올거나이즈의 자체 소형언어모델(sLLM)을 비롯해 챗GPT, 엑사원, 큐원, 딥시크 등 총 12개의 LLM을 분석할 수 있다.
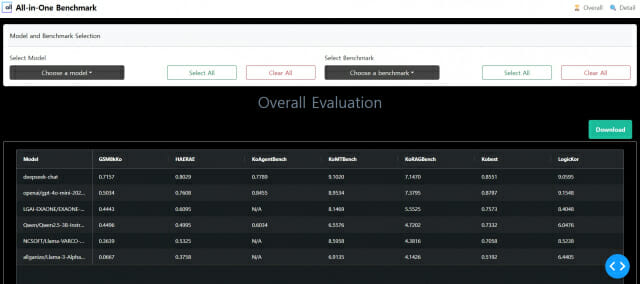
새로운 LLM 평가는 매우 간편하게 진행된다. 모델 이름을 입력하면 애플리케이션 프로그램 인터페이스(API)가 자동 구현돼 즉시 테스트가 가능하다. 또 기존 벤치마크 방식이 동일 작업을 반복 실행해야 하는 불편함이 있었던 데 비해 올인원 벤치마크는 대규모 데이터셋에서도 효율적인 평가가 가능해 시간을 대폭 단축했다.
최근 올거나이즈는 올인원 벤치마크를 활용해 오픈소스로 공개된 딥시크의 'V3' 모델을 평가했으며 그 결과 'GPT-4o 미니'와 유사한 성능을 보였다고 밝혔다. 'V3'는 기존 다양한 벤치마크에서 성능을 검증받았으나 에이전트로서의 성능 분석은 이번이 처음이다.
관련기사
- 올거나이즈, 한국어 문서 생성·요약 특화 모델 출시2024.06.03
- 올거나이즈 "생성형 AI '거짓말 탐지기' 성능 비교하세요"2024.05.29
- 올거나이즈 "알리LLM앱, 보안 기능 업그레이드"2024.04.23
- 올거나이즈, 금융 전문 언어모델로 업무 생산성 높인다2024.04.08
올인원 벤치마크는 에이전트 성능뿐 아니라 언어 이해력, 지식 수준, 명령 준수(Instruction Following) 등 LLM의 전반적인 역량을 평가한다. 평가에는 '아레나하드(ArenaHard)' '코베스트(Kobest)' '해래(HAERAE)' 등 12개의 공개 벤치마크가 활용되며 결과는 100점 만점 기준으로 소수점 4자리까지 수치화돼 제공된다.
이창수 올거나이즈 대표는 "기업들이 AI 도입 시 객관적인 데이터를 기반으로 최적의 LLM을 선택할 수 있도록 지속적으로 평가 플랫폼을 업데이트할 것"이라며 "에이전트 성능을 강화하기 위한 LLM 학습 방법도 심도 있게 연구 중"이라고 밝혔다.





