바이브컴퍼니(대표 이재용, 이하 바이브)는 '2022년 인공지능 학습용 데이터 구축 지원 사업(2차)'의 일환인 '숫자연산 기계독해 데이터' 구축 과제를 성공적으로 마무리했다고 26일 밝혔다.
이 사업은 과학기술정보통신부(과기정통부)가 주관하고 한국지능정보사회진흥원(NIA,
원장 황종성)가 추진하는 사업으로, 바이브는 '숫자연산 기계독해 데이터' 구축 과제의 주관기관으로 딥네츄럴, 포티투마루와 함께 컨소시엄을 구성해 사업을 수행했다.
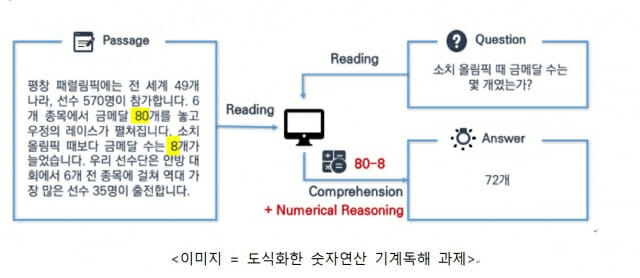
숫자연산 기계독해 데이터란 사칙연산 등 숫자연산이 필요한 분야의 문서에 기계독해를 적용해 수치연산 질의를 통해 답을 찾아내는 인공지능 모델을 구축하기 위한 학습용 데이터를 뜻한다.
바이브 컨소시엄은 올해 6월부터 12월까지 7개월간 ▲경제, 스포츠 분야 신문 기사 데이터에서 뽑은 30만 개 지문에 대한 39만 건의 질의응답 라벨링 ▲숫자연산 기계독해 AI 모델 구축을 진행했다. 특히 바이브는 지난 5월 한국어 기계독해 평가 '코쿼드(KorQuAD)1.0'에서 123개의 모델 중 4위에 오르며 기계독해 기술력을 인정받은 바 있다.
'코쿼드1.0'은 한국어 기계 독해 평가를 위해 LG CNS에서 공개한 한국어 질의응답 데이터셋이다. 위키백과에서 추출한 7만 개의 AI 학습용 표준 데이터셋을 기반으로 질문을 제시하면 AI 모델이 그에 맞는 답을 찾아내는 방식으로 진행한다. 바이브가 이번에 구축한 데이터와 AI 모델은 내년 상반기 중 NIA에서 운영하는 ‘AI 허브'에서 공개된다.
이기황 바이브 인공지능빅데이터연구소 이사는 "이번 과제 수행을 통해 세계적으로 아직 초기 단계에 있는 숫자연산 기계독해 기술의 개발과 발전에 큰 기여를 하게 될 것으로 기대하고 있다."고 밝혔다.
한편 바이브는 기계독해 기술과 텍스트 자동 요약 기술을 활용해 핀테크 전문 자회사인 퀀팃과 함께 AI 기반 금융 정보 서비스인 '핀터랩스(Finter Labs)'의 데모 버전을 운영하며 꾸준한 기술 개발 및 상용화를 진행하고 있다.