



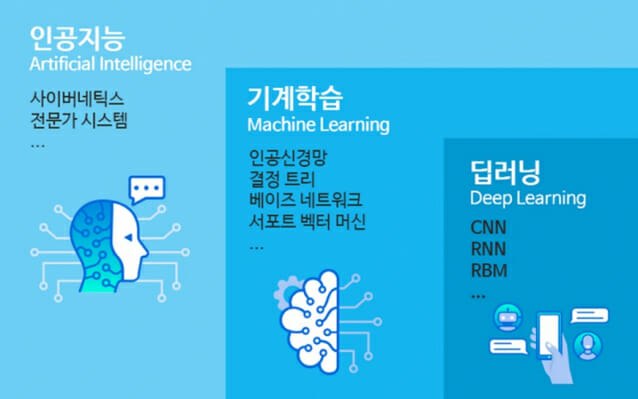
인공지능의 범주를 나눌 때 일반적으로 기계학습(ML, 머신러닝)과 딥러닝으로 나눈다. 그러나 둘의 차이가 무엇인지를 명확히 이해하고 있는 사람은 드물다.
기본적으로는 기계학습이 좀 더 포괄적인 인공지능을 의미하고, 딥러닝은 기계학습보다 좀 더 진일보된 고도화된 알고리즘으로 기계학습의 영역 안에 들어간다고 이해하면 좋겠다.
인공지능을 처음 배우는 일반적인 사람들은 무엇부터 배워야 하는지, 그리고 무엇까지 알아야 그래도 어느 정도 인공지능을 안다고 이야기할 수 있는지, 난감한 경우가 많다.
내가 몸담고 있는 대학원에서 진행하고 있는 AI 빅데이터 MBA 과정에는 다양한 백그라운드의 학생들이 입학을 하는데, 공학을 전공하고 IT 관련 회사에서 개발 경험을 가진 분들도 계시고, 완전히 인문학이나 상경계를 전공하시고 일반적인 업무를 하시어 공학적인 백그라운드가 아예 없는 분도 있다.
이러한 다양한 배경의 분들이 함께 공부를 하면서 서로의 약점들을 보완해가면서 공부를 하고 있다.
어떠한 기반을 가진 분들이라 하더라도 기본으로 수학이나 통계 등에 기반을 둔 인공지능 알고리즘을 어느 정도 이해를 해야 그래도 인공지능에 대해서 좀 안다고 할 수 있고, 더 나아가 성공적으로 본인들의 업무나 비즈니스에 활용할 수 있는데, 비즈니스나 학문적으로 가장 많이 활용되고 있는 대표적인 기계학습과 딥러닝의 알고리즘들이 있다.
이번 글에서는 우리가 기본적으로 알고 있어야 하는 14가지의 인공지능 알고리즘에 대해서 정리를 해보고자 한다. 이 14가지의 이름 정도만 외우고 있더라 하더라도 누군가가 인공지능에 대해서 이야기를 하거나 관련 논문을 볼 때에 어느 정도는 대화가 가능하리라 본다.
먼저 9가지의 대표적인 기계학습 알고리즘이다. 그 리스트를 정리하자면 다음과 같다.
1. K최근접이웃 (K-NN, K-Nearest Neighborhood)
2. 나이브 베이즈 분류기(Naïve Bayes Classifier)
3. 선형회귀(Linear Regression)
4. 로지스틱 회귀(Logistic Regression)
5. 서포트 벡터머신(SVM, Support Vector Machine)
6. 결정트리(Decision Tree)
7. 랜덤 포레스트(Random Forest)
8. 군집분석(K-means Clustering)
9. 신경망(MLP, Neural Network)
기계학습은 상당히 통계나 수학에 기반한 로직이나 알고리즘이다 보니, 기존의 알고리즘을 활용하여 다양한 문제 해결의 성능을 높이는 정도로 발전하고 있지, 전혀 새로운 기계학습의 알고리즘이 제시되거나 발표되는 경우는 드물다.
하지만 딥러닝의 영역은 지속적으로 새로운 알고리즘이나 컨셉들이 개발되고 있다. 특히 컴퓨터 비전이나 로보틱스의 영역에 있어서는 기존의 알고리즘들을 다시 합성하거나, 아니면 GAN 과 같이 전혀 새로운 개념의 알고리즘들도 나오고 있다.
일반적으로 우리가 알아야 할 5가지의 딥러닝 알고리즘은 다음과 같다.
1. 제한된 볼츠만 머신 (RBM, Restricted Boltzman Machine)
2. 심층 신뢰망(DBM, Deep Belief Network)
3. 합성곱 신경망(CNN, Convolutional Neural Net)
4. 순환신경망(RNN, Recurrent Neural Net)
5. 적대적 생성 신경망(GAN, Generative Adversarial Network)
이제 기계학습 알고리즘부터 하나하나 알아보도록 하겠다.
첫 번째는 K-Nearest Neighborhood (K-NN) 알고리즘이다. 한국말로 번역하면 ‘최근접 이웃 분류’ 알고리즘이라고 할 수 있다.
지도학습의 일종으로 이미 어떠한 클래스에 속한다고 정해진 학습 데이터들을 기반으로 아래 그림에서 보는 바와 같이 분류가 이루어진다.
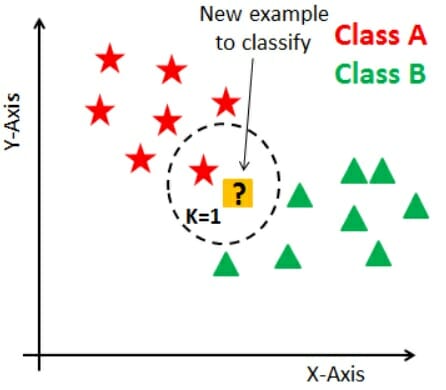
클래스 A와 B로 나누어진 문제에 있어, 새롭게 들어오는 입력값을 중심으로 K라는 일종의 거리를 정해 놓고 그 안에 A와 B의 학습데이터 중 어느 것이 더 많이 들어 오느냐에 따라 분류를 이루어 간다.
이때 측정하는 거리를 일명, ‘유클리디안 거리’ 라고 부른다. 기계학습의 모든 알고리즘에서 거리를 측정할 때 활용한다.
K-NN은 가장 간단하면서도 활용도가 높은 알고리즘이다. 예시 그림에서는 간단한 2차원적인 점으로 표현되어 있지만, 다차원의 피처들로 표현되는 다양한 문제들을 분류하는데 아주 쉽게 적용할 수 있다.
관련기사
- [기고] AI의 기본 쉽게 이해하기 2-22022.06.27
- [기고] AI의 기본 쉽게 이해하기 2-12022.06.13
- [기고] AI 기본 이해하기2022.05.30
- [기고]AI 플레이북 어떻게 작성할까? (하)2022.05.16
예를 들면 유통업에서의 고객관리 등에서도 쓰인다. 고객들의 그동안의 구매나 행동 패턴, 선호하는 상품이나 VOC 내용 등을 통해 고객들을 여러 라이프 스타일이나 등급으로 나누어 놓고, 관리를 하는데, 이때 다양한 입력 데이터를 가지고 가장 유사한 특성의 고객들을 군집화해서 묶어 놓는데 이 알고리즘은 유용하다.
새로운 고객이 등장했을 때, 가장 비슷한 성향의 군집화된 고객들에게 그동안 효과가 있었던 프로모션이나 마케팅을 그 고객에게 제시하여 성공확률을 높일 수 있다. 이외에도 컴퓨터 비전에서 얼굴인식이나 지문인식, 영상 분석 등 가장 비슷한 패턴을 보이는 값들을 찾을 때 아주 간단한 알고리즘이지만 좋은 성능을 보이고 있다.
*본 칼럼 내용은 본지 편집방향과 다를 수 있습니다.






