"디지털 뉴딜은 데이터 댐을 만드는 것이다." 문재인 대통령이 한국형 뉴딜 첫 행보에서 디지털 뉴딜 구상을 한 마디로 설명하기 위해 꺼낸 말이다.
한국형 뉴딜은 코로나19로 인한 경제 위기를 극복하고 글로벌 경제를 선도하기 위해 추진되는 국가 발전 전략이다. 디지털 뉴딜은 그 한 축을 담당하며, 경제 전반의 디지털 혁신을 일으키는 것을 목표로 한다.
디지털 혁신을 위한 필수 재료가 데이터인 만큼, 데이터를 충분히 확보하고 잘 활용할 수 있게 하는 '디지털 댐' 사업이 이번 디지털 뉴딜의 핵심이다. 문 대통령이 '디지털 뉴딜이 곧 데이터 댐'이라고 요약한 이유이기도 하다.
'데이터가 21세기 원유이며, 미래 경쟁 우위를 좌우할 것'이라는 전망은 일찍이 2011년 나왔다. 하지만, 국가 발전의 핵심 원동력으로 데이터를 주목하고 조 단위 예산을 투입한 건 이번이 처음이다. 이런 변화만으로 산업계는 데이터 댐 사업을 긍정적으로 평가하고 있다.

다만, 데이터 댐에 담긴 데이터가 실제 다양한 산업이 혁신하는 데 쓰이려면, 데이터 전주기를 큰 그림에서 보고 정책을 추진할 필요가 있다는 게 전문가들의 공통된 제언이다. 현재 댐 안에 넣는 데이터 양을 늘리는 데 우선순위를 두고 있는데, 데이터를 쌓는 현 시점부터 민간에서 잘 활용되게 할 방법을 함께 고민할 필요가 있다는 얘기다. 이런 고민 없이 쌓인 데이터는 '오수(汚水)일 뿐이라, 정화하는 데 시간과 비용이 더 들어가 결국 쓰이지 못할 가능성이 크다.
품질 좋은 데이터가 쏟아지는 데이터 댐을 만들기 위해서는 '데이터 공개 원칙'이 마련될 필요가 있다. '개방'과 '표준'이 데이터 공개 원칙에 반드시 포함돼야 할 키워드로 꼽힌다. 이외에도 개인정보 가명화·익명화 선도 적용도 데이터 공개 단계에서 고려해야 할 요소로 지목된다.
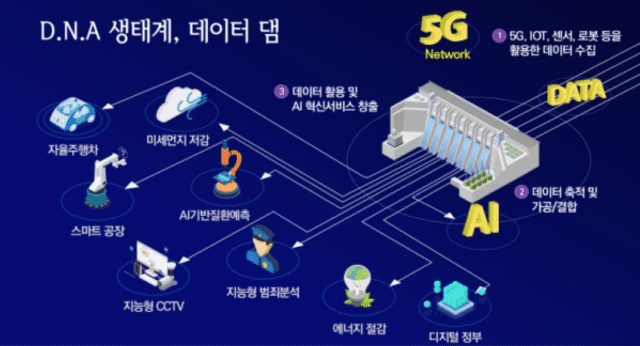
데이터 댐 구축 사업 뜯어보니...'데이터 수량' 높이기에 우선순위
데이터 댐 사업은 데이터 수집·가공·결합·거래·활용을 통해 데이터 경제를 가속화하고, 데이터를 실어 나를 파이프로 5G 전국망을 확산하는 사업이다. 데이터 댐 구축에 2022년까지 8.5조, 2025년까지 18.1조의 예산이 투입된다.
정부는 데이터 댐을 구축하는 과정에서 신규 일자리가 생겨나고 의료, 교육, 제조 등 다양한 산업에서 데이터를 활용한 새로운 비즈니스가 창출될 것으로 기대하고 있다. 미국이 과거 대공황 시 뉴딜의 대표 사업으로 ‘후버댐’ 건설을 추진해, 일자리를 만들고 연관 산업으로 부가가치를 확대한 것과 유사한 전략이다.
정부는 데이터 댐 사업 첫해인 만큼 댐 안에 담을 '데이터 확보'에 우선순위를 두고 세부 사업을 기획했다. 1160.7억원이 투입되는 '공공데이터 개방 사업'과 3473.9억이 배정된 'AI학습용 데이터 구축 사업'이 주축이다.
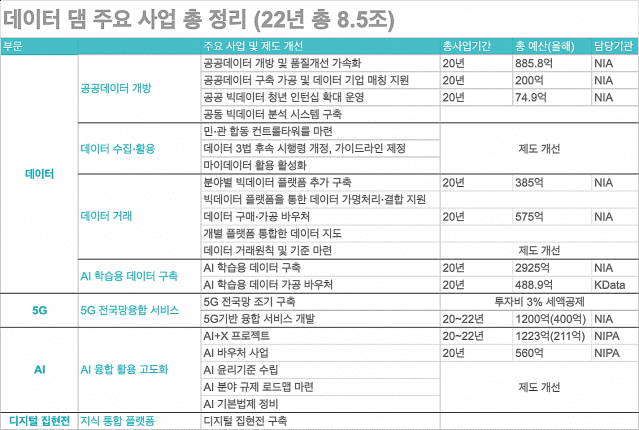
공공데이터 개방 사업은 전국 공공기관에 청년 인턴을 배치해 공공 데이터 개방과 품질 개선, 실측 등을 수행하는 사업이다. 공공데이터 14만2천 개를 개방하고 8천 명의 청년 인턴 일자리 창출 효과가 기대된다.
AI 학습용 데이터 구축 사업은 수요가 많고 기술적으로 구현 가능한 AI 학습용 데이터를 크라우드 소싱 방식을 이용해 구축하는 사업이다. 올해 150종의 데이터를 구축해 AI 허브 사이트에 공개하고, 2만개 이상의 일자리를 만든다는 계획이다.
이렇듯 데이터 확보에 이번 사업의 우선순위를 둔 이유는 대규모 일자리를 창출 목적도 있지만, 현실적으로 데이터 활용을 논하기엔 아직 데이터 댐 안에 담을 데이터의 양이 절대적으로 부족한 상황을 고려한 것이 크다.
실제 과학기술정보통신부가 올해 1월 발간한 정보화통계집에 따르면 2018년 기준 조사 대상 전체 사업체 401만여 개 중 공공데이터를 활용하고 있는 곳은 단 12.5% 수준으로 나타났는데, 공공데이터를 쓰지 않는 이유에 대해 53.9%의 기업이 '필요한 공공데이터가 없다'는 점을 지적했다.
이와 관련해 데이터 댐 사업 중 상당 부분을 맡고 있는 한국정보화진흥원(NIA)의 박원재 정책본부 총괄은 "데이터가 디지털 경제를 만드는 핵심적인 자원인데 데이터 양 자체가 적고 활용할 만한 게 없다는 지적이 존재한다"며 "데이터 댐 사업의 1차 목표는 데이터를 많이 생성하고 축적하는 것이고 이와 병행해서 만들어진 데이터가 산업 경쟁력을 강화하거나 AI에 활용되게 할 계획"이라고 설명했다.
데이터 구축 단계부터 활용 고민해야...데이터 공개원칙 필요
데이터 댐에 넣을 데이터 양을 늘리는 작업이 선행돼야 이후 가공, 활용, 거래 활성화도 가능해지지만, 무조건 데이터를 많이 담는 것만이 능사는 아니다. 댐 안에 품질 낮은 데이터만 잔뜩 담겨 있으면, 아무리 양이 많아도 활용되기 어렵다.
이런 이유로 정부도 데이터 품질 관리 장치를 마련하는 데 신경을 썼다. 특히 AI 학습용 데이터의 경우 한국정보통신기술협회(TTA)와 함께 활용 적합도를 검증하는 절차를 마련할 예정이다. 또 공공데이터 개방과 품질 개선 작업에 참여하는 청년 인턴에 대해선 어느정도 데이터에 대한 기본 이해가 있는 사람을 선별하고, 충분한 교육 후 기관에 배치한다는 계획이다.
짧은 사업 기간을 고려하면 이 같은 노력도 물론 필요하다. 하지만, 장기적인 관점으로 보면 데이터가 처음에 생성될 때부터 활용에 적합한 방식이 되는 것이 맞다. 그래야 때마다 밀린 숙제를 하듯 대규모 데이터 구축·품질 관리 사업을 할 필요도 없고, 공공에서 생성된 최신 데이터를 민간이 즉시 활용하는 효과도 볼 수 있다.
전문가들도 데이터 전주기를 고려한 품질 관리 체계를 구현하는 것이 중요하다고 입을 모으고 있다.
김학래 중앙대학교 문헌정보학과 교수는 "데이터 댐이 데이터 경제 활성화라는 처음 목적을 달성하려면 데이터 구축부터 향후 관리와 활용까지 데이터 전주기에 대한 고민이 동시에 이뤄져야 한다"고 조언했다.

이를 위한 구체적은 방안으로 '데이터 공개 원칙' 제정을 고려해 볼 필요가 있다. 미국은 오바마 정부때 이미 공공데이터 개방 기본원칙과 이행을 위한 요구사항을 담아 행정명령을 제정한 바 있다.
미국 공공데이터 개방 기본원칙에는 ▲반드시 기계적으로 검색할 수 있는 상태로 개방할 것 ▲상호호환성과 개방성을 높이고 누구든지 쉽게 접근 활용하게 할 것 ▲정보가 생산, 수정, 활용, 폐기 되는 생애주기에 따라 적정한 관리를 의무화할 것 ▲정보를 개방하기 전에 개인의 프라이버시, 비밀보장, 국가안보 등에 대한 비식별화 조치를 마련할 것 등의 내용이 포함됐다.
박태웅 한빛미디어 이사회 의장(공공데이터전략위원회 민간위원)은 "데이터 댐의 목표가 AI 학습을 위한 데이터의 축적에 있는 만큼 기계가 읽을 수 있어야 하고(Machine readable), 누구나 접근가능해야 하며, 표준을 지켜서 상호운영이 가능해야 한다는 원칙이 데이터 댐 사업에도 동일하게 적용될 수 있다"고 설명했다. 또 "개방, 공유, 표준, 머신 리더블이 기본이 돼야 하고 여기에 개방과 공유를 위해서는 오픈소스라는 가치도 추가되는 것이 바람직하다"고 덧붙였다.
특히 기계가 읽을 수 있는 포맷으로 데이터를 공개한다는 원칙만 지켜져도 활용할 수 있는 데이터 양이 크게 늘어날 수 있다. 여전히 공공기관들이 대부분의 문서를 한글(HWP)이나 PDF 파일로 공개하고 있는데, 이런 파일은 오픈포맷이 아니라 파일 속 데이터를 기계가 자동으로 읽는 게 불가능하다.
박 의장은 "예컨대 기재부가 예산자료를 엑셀에 담아 발표하면 순식간에 통계를 내고 최근 수년간의 효율을 비교하는 게 가능한데 이것을 PDF에 담아 공개하는 바람에 여기에 있는 개별 숫자들을 활용하기 위해선 일일이 수동으로 입력해야 하는 상황"이라며 "'데이터가 석유’라고 하는 정부에서 지금 이 순간에도 기계가 읽을 수 없는 자료들을 계속해서 홈페이지에 올리고 있는 일이 답답하다"고 꼬집었다.
개인정보 포함된 공공 데이터에 익명화 가명화 시범 적용해야
데이터3법 통과로 개인정보가 포함된 데이터도 비식별화 조치를 거쳐 활용할 수 있게 된 만큼, 이번 데이터 댐 사업에서 개인정보가 포함된 공공 데이터에 익명화·가명화를 시범 적용해 볼 필요가 있다는 의견도 나온다.
데이터 댐 사업을 통해 올해 개방되는 공공 데이터 14만 건은 모두 개인정보가 포함되지 않은 것이다. 실제 개인정보와 연결된 데이터가 더 활용 가치가 크고, 양도 방대할 것으로 예상된다.
지난 20일 서울 을지로 더존비즈온 사옥에서 더불어민주당 'K-뉴딜위원회' 주최로 열린 디지털 댐 정책 간담회에서 최성진 코리아스타트업포럼 대표는 "데이터3법 통과로 가명정보·익명정보 결합이 가능해졌지만 기업들은 시민단체 눈치만 보고 있는 상황"이라며 "공공에서 선도적으로 개인정보를 비식별화하고 가명화·익명화해 민간에서 더 많이 활용할 수 있게 해야 한다"고 제언했다.
실제 정부도 개인정보가 포함된 공공 데이터가 그렇지 않은 것보다 훨씬 많고, 비식별화할 경우 활용 가치가 높다는 점을 인식하고 개방할 방법을 찾고 있는 중이다.
이날 행정안전부 서보람 국장은 이 같은 요청에 "행정기관이 가지고 있는 데이터 중 상당분은 개인정보가 포함돼 있는 것"이라며 "이것을 어떻게 잘 가명화·익명화해서 활용하는데 문제가 없도록 개인정보보호위원회와 논의하고 있다"고 답했다.
관련기사
- 왜 디지털 뉴딜이어야 하는가2020.08.18
- 거대한 뉴딜 자금, 어떻게 쓸 것인가2020.08.19
- 디지털뉴딜에 소상공인 온라인 도전 거세진다2020.08.19
- 디지털뉴딜 선도할 25개 분야 '국가중점데이터' 개방2020.08.18
이렇게 되면 데이터 댐 사업이 데이터3법을 실험해보고, 보안점을 찾는 테스트베드가 될 수 있다.
최경진 가천대 법학과(AAI빅데이터 연구센터장) 교수는 "그동안 데이터가 잘 모이지 않았다고 법을 개정한 것인데 법 개정 후 실제 데이터가 더 잘 모일지 실험해 볼 수 있는 기회가 데이터 댐 사업으로 생겼다"며 "데이터를 더 잘 모을 방법을 발전시켜 나갈 수 있게 됐다"고 말했다.