






한국전자통신연구원(ETRI)이 기존의 문어체 언어분석 기술을 고도화시킨 구어체 언어분석 API(application Programming Interface, 응용프로그램에서 사용할수 있게 운용체계나 프로그래밍 언어가 제공하는 기능을 제어가능 하게 만든 인터페이스)를 공개했다. 국내 최고 수준 구어체 언어분석 API다. 글을 이해하는 인공지능(AI)을 넘어 사람의 말까지 이해할 수 있는 국내 AI 서비스 개발에 탄력이 붙을 전망이다.
6일 ETRI는 위키백과 및 법령 등 문어체를 주로 이해하는 기존 언어분석 기술을 확장, 사람의 대화 분석 오류를 최대 41% 개선, 정확하게 이해할 수 있는 구어체 언어분석 기술을 관련 사이트에 공개했다고 밝혔다.
ETRI가 개발한 언어 인공지능 '엑소브레인(Exobrain)'은 현재 ‘한컴오피스 2020’에 탑재되는 등 이미 상용화가 이뤄진 인공지능으로 ▲언어분석 기술 ▲딥러닝 언어모델 기술 ▲질의응답 기술 등이 적용됐다.
특히 언어분석 API는 2017년 10월 공개 이후, 일 평균 2만 6천 건 등 총 2600만 건에 이를 만큼 학계 및 언어처리 분야 연구자들에게 널리 사용되고 있다.

ETRI 연구진은 기존 문어체 기술을 고도화해 사람의 대화까지 정확하게 이해할 수 있는 구어체 언어분석 기술을 개발하는 데 성공했다. 이로써 관련 산업 생태계를 활성화하고 AI비서, 챗봇 등 AI 서비스 개발이 한층 가속화될 전망이다.
예컨대, ‘패션검색’을 주제로 AI 서비스를 하기 위해선 기존에는 언어처리 기술 준비작업이 만만치 않았으나 ETRI 엑소브레인 API를 활용하면 서비스에 더 집중할 수 있다.
ETRI가 공개한 구어체 언어분석 기술은 크게 ▲형태소 분석 기술 ▲개체명 인식 기술 등 두 가지다. 한국정보통신기술협회(TTA, Telecommunications Technology Association) 표준 가이드라인을 따랐고, 형태소 태그는 47개, 개체명 태그는 146개다.
형태소 분석 기술은 한국어 의미의 최소 단위를 분석하는 기술이다. 한국어 처리에 필수적으로 요구된다. 특히 지난해 코버트(KorBERT: Korean Bidirectional Encoder Representations from Transformers) 딥러닝 언어모델 기본 입력으로 적용, 많은 기업에서도 ETRI 제안 방법과 같이 형태소 분석에 기반한 딥러닝 언어모델 기술을 활용 중이다.
개체명 인식 기술은 문장 내 고유 대상과 그 의미를 인식하는 기술로 AI스피커와 챗봇 등 다양한 언어처리 서비스에 활용도가 높다. 예를 들어, ‘국민은행’이라는 단어가 ‘국민’이라는 명사와 ‘은행’이라는 명사의 결합이 아닌 고유 은행 명칭이라는 점을 인식하는 기술이다.
연구진은 구어체 언어분석의 어려운 점은 과업 자체의 난이도와 학습데이터 부족에 있다고 설명했다. 예컨대 '경상도인데'를 '경상돈데'라고 구어체로 표현하는 경우, 기존 형태소 분석 기술은 '경상도 인데'라는 축약 표현을 인식하지 못한 채 '경상돈 데'라고 분석하는 것이다.
또, 기계학습 및 딥러닝 기술이 대규모 학습데이터를 필요로 하는 데 반해 구어체 분야는 데이터 확보조차 어렵다는 문제가 있다. 실제 개체명 인식 학습데이터의 경우, 문어체는 약 27만 건이지만 구어체는 이의 10분의 1 수준인 2만 5천 건에 불과했다.
연구진은 전이학습(transfer learning)과 데이터 증강(data augmentation) 기법을 활용해 학습데이터 부족 한계를 극복했다.
전이학습과 데이터 증강 기법은 학습 데이터가 부족한 환경에서 딥러닝 기술 한계를 극복하기 위한 기술로 이미 존재하는 타 분야 학습 모델과 소량의 학습데이터를 재사용하는 방식으로 학습이 이뤄진다.
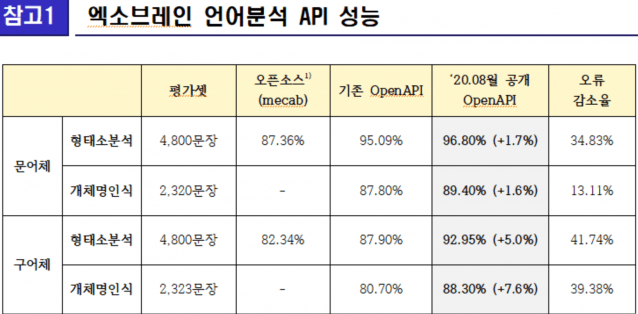
그 결과, 이번 구어체 언어분석 API는 기존 모델 대비 형태소 분석과 개체명 인식 성능이 각각 5.0%, 7.6% 개선됐고, 41.74%와 39.38%에 달하는 오류 감소율(오류가 감소하는 비율을 측정하는 지표로, 성능이 동일하게 1%p 개선되더라도 80%→81% 향상보다 95%→96% 향상 시 오류감소율이 크다)을 나타냈다.
특히, 형태소분석은 메캡(Mecab) 오픈소스 라이브러리(산업계에서 사용되는 한국어 형태소 분석 오픈소스 중 하나) 대비 10.6% 더 우수한 것으로 평가됐다.
ETRI 연구진은 구어체 언어분석 API와 더불어 기존 대비 성능을 개선한 문어체 언어분석 API도 추가로 공개했다. 추가로 공개된 API는 형태소 분석과 개체명 인식 기술이 각각 96.80%, 89.40%의 높은 정확도를 보였다.
ETRI 언어지능연구실 임준호 박사는 "기존 엑소브레인 언어분석 기술이 백과사전 및 법령을 분석하기 위한 목적으로 개발되었음에도 구어체 분야에 많이 적용됐다. 이번 구어체 언어분석 API 공개로 언어분석의 정확도 및 신뢰도를 제고해 국내 인공지능 시장이 더욱 활성화되길 기대한다"고 밝혔다.
엑소브레인 사업단은 최근 3년간 기술이전 22건과 사업화 17건을 달성해 외산 인공지능 솔루션의 국내시장 잠식을 막는 동시에 응용 서비스 폭을 넓히는 데 힘쓰고 있다. 추후 딥러닝 언어모델의 지속적인 성능 개선 및 추가 공개를 통해 AI 기술 고도화 및 플랫폼 개발에 기여할 계획이다.
관련기사
- ETRI, AI 음향 인식 대회서 세계 1위2020.07.20
- NHN, ETRI에 협업툴 '두레이' 공급2020.07.13
- 美, 앤트로픽 '미토스5' 빗장 풀어…"100여 곳에 허용"2026.06.27
- 中 파운드리, AI 반도체 슈퍼사이클 수혜로 매출 성장세 '뚜렷'2026.06.27
이번 과제는 2013년부터 과학기술정보통신부와 정보통신기획평가원(IITP)의 혁신성장동력 프로젝트로 수행 중이며, ETRI가 총괄 및 세부과제1을 담당해 전체 세부과제를 이끌고 있다.
세부과제2는 솔트룩스가 주관기관이고 엑소브레인 지식학습과 지식베이스 구축 기술을 다국어화한 서비스형 AI, AIaaS(AI as a Service) 플랫폼을 개발해 사업화를 진행 중이다.





