






정보 주체를 알아볼 수 없도록 처리한 비식별 개인정보도 다른 비식별 개인정보와 결합하면 주체가 식별될 수 있다는 우려가 나타나고 있다.
이에 정보 주체 식별 가능성을 차단하면서도 개인정보를 비교적 왜곡 없이 산업적으로 활용할 수 있도록 하는 방식인 '재현 데이터'를 활용하자는 주장이 나왔다.
'국제해킹보안컨퍼런스(POC) 2019'에서 장웅태 성균관대학교 학생과 김민용 전북대학교 학생은 비식별화된 데이터를 재식별한 결과와 재현 데이터 기법을 소개했다.

■"현행 비식별 정보, 알고리즘으로 18% 재식별"
장웅태 학생은 비식별 개인정보와 다른 정보를 결합해 정보 주체가 식별된 사례를 언급했다.
먼저 미국 메사추세츠 주의 사례를 소개했다. 연구 목적으로 이름, 성별, 주소, 우편번호, 생일 등이 포함된 공무원의 병원 진료 기록을 공개했다. 이를 선거인 명부와 결합하자 주지사의 진료 정보를 식별된 경우다.
넷플릭스에 기록된 영화 평가 정보와 다른 영화 평점 사이트 IMDb의 정보를 결합해 정보 주체를 특정한 사례도 있었다. 넷플릭스는 영화 평점 알고리즘 개선 대회를 위해 이용자 50만명의 영화 평가 정보 1억개를 비식별 처리해 공개했다. 그러나 IMDb 이용자 50명의 평점 정보를 활용하자 특정 정보의 주체가 도출됐다. 이 때문에 대회가 중지되기도 했다.
장웅태, 김민용 학생은 실제 두 문자열 간 유사도를 확인하는 레펜슈타인 거리 알고리즘을 활용, 두 데이터베이스 간 재식별이 가능하다는 것을 증명했다.
이 알고리즘은 하나의 속성값에 대해 다른 속성값마다 유사도를 측정하고, 그 중 최댓값을 선택하는 방식으로 작동한다.
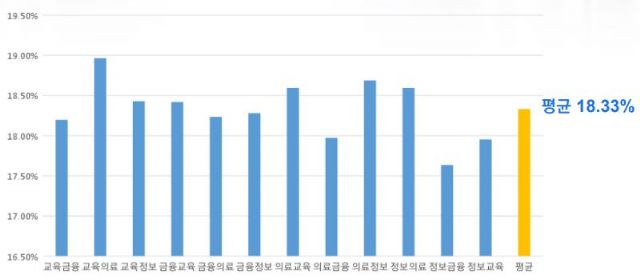
장웅태 학생은 현행 가이드라인 기준으로 비식별 처리한 가상의 의료·금융 데이터 각 10만건을 사용했다. 레펜슈타인 거리 알고리즘을 사용해 분석한 결과 재식별률이 18.23%로 나왔다.
미국 의료정보보호법(HIPAA) 상 비식별화 가이드라인에서는 재식별률 0.4% 미만일 때 재식별 위험이 없다고 판단한다. 장웅태 학생은 "HIPAA의 가이드라인을 기준으로 볼 때 재식별률이 높게 나왔다"며 "그외 다른 종류의 데이터끼리 결합했을 때에도 평균 재식별률이 18.33%로 이와 크게 다르지 않았다"고 설명했다.
■재현 데이터, 신뢰성·사용 난이도가 한계…"비식별 연구 활성화돼야"
김민용 전북대학교 학생은 "데이터 유사도 식별 알고리즘은 각 데이터 간의 연관성을 줄이는 방법으로 재식별 위협을 막을 수 있을 것"이라면서도 "데이터를 삭제하거나, 순서를 재배열하는 기존 방식은 데이터 훼손이 많아 빅데이터 활용 가치가 떨어진다"고 말했다.
그는 기존 방식의 비식별 수준과 데이터 유용성이 반비례한다는 단점을 극복할 수 있는 기법으로 재현 데이터를 제안했다. 재현 데이터는 원본 데이터와는 다른 값을 지니지만 원본 데이터 전체의 확률분포를 비교적 정밀하게 보존한 자료로, 머신러닝 학습용 데이터 생성에 주로 활용된다.
재현 데이터 생성 과정은 크게 세 단계로 나뉜다. 먼저 원본 데이터를 분석해 변수의 분포와, 상관관계 등을 분석한다. 이후 변수 중 노출 시 위험이 큰 변수를 선정한다. 이 변수에 대해 재현값을 생성하는 식이다. 실제로 미국 인구조사국이 재현 데이터 기법을 활용해 인구들의 거주 지역과 직장 지역 정보 등을 담고 있는 통근 데이터를 비식별하고 있다.
다만 재현 데이터 기법이 만능은 아니다. 분포값을 토대로 생성된 자료인 만큼, 신뢰성에 의문이 제기될 수 있다는 것. 김민용 학생은 "외국에서는 재현 데이터를 사용할 때 원본 자료와 재현 데이터 자료를 동일하게 분석해 비교한 값을 함께 제공해 신뢰성에 대한 의문을 해소해주고 있다"고 설명했다.
관련기사
- 비식별 개인정보 활용 기술 어디까지 왔나2019.11.15
- 정부, 바다 위 4차 산업혁명 자율운항선박 상용화한다2019.11.15
- 네이버는 어떻게 빅데이터를 안전히 가공할까?2019.11.15
- KISA, 빅데이터로 '앞으로 유행할 보안위협' 예측한다2019.11.15

통계적 지식을 보유한 사람만 이 기법을 사용할 수 있다는 것도 한계점이다.
김민용 학생은 "재현 데이터를 활용하기 위한 도구가 제공되면 사용이 좀더 용이해질 것으로 본다"며 "비식별화가 필수인 빅데이터 관련 시장이 오는 2022년 2천억원 규모를 이룰 것으로 전망되는 상황에서 현재 활발치 않은 비식별 기술 연구도 활성화돼야 할 것"이라고 언급했다.





