






비식별 처리한 개인정보의 활용 사례가 늘어나고 있다. 동시에 정보를 비식별된 채로 안전하게 분석할 수 있는 기술도 고도화되는 상황이다.
31일 서울 송파구 롯데월드타워에서 열린 '개인정보 비식별 기술 세미나'에서는 비식별 개인정보 활용 기술, 사례가 공유됐다.
이날 세미나에서는 비식별화된 통신 데이터를 활용, 2천만명 이상 인구의 실시간 이동 추이와 속성 정보를 파악해 이를 토대로 대중교통, 관광지 수요나 상권의 영향력을 도출한 사례가 소개됐다.
아울러 반출이 어려운 의료 정보 분석을 위해, 여러 병원에 분산돼 있는 의료 정보를 한 데 모을 필요 없이 분산된 상태로 분석해내는 연합학습(Federated Learning) 기술이 주목할 만한 방법론으로 언급됐다.
■실시간 유동인구 파악에 유리한 LTE 데이터, 관광·교통·상권 분석에 유리
이종현 KT 팀장은 LTE 데이터의 특성을 살려 빅데이터 분석에 활용한 사례들을 설명했다.
KT는 평균 5분 단위로 가입자 1천800만명과, KT 로밍을 사용하는 600만명의 외국인 방문객들의 LTE 시그널 데이터를 수집하고 있다. 단말이 통신하는 기지국이 바뀌거나, 데이터를 사용하거나, 3시간마다 통신 상태를 확인하기 위한 차원에서 시그널 데이터 수집이 이뤄진다.

특히 가입자의 연령별 인구 분포를 살펴볼 때 통계청의 주민등록인구 분포와 상관 계수 0.96을 보여 높은 관련성을 보여줬다는 설명이다. 상관 계수는 1에 가까울수록 변수 간 관련성이 높다는 것을 나타낸다.
KT는 이 시그널 데이터를 개인정보 비식별화 조치 후 분석에 활용한다. 지난 2013년에는 이 데이터를 서울시 심야 버스 노선 설정에 활용했다. 실시간으로 위치를 체크하는 통신 데이터를 이용해 시간대별 주재 인구를 파악, 교통 수요를 도출해낸 것이다.
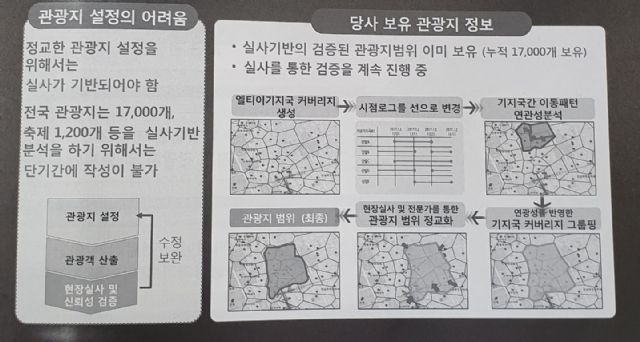
관광지 유동 인구 중 실제 거주민과 국내외 관광객을 분리해 관광객 수를 집계하고, 관광객들의 이동 추이를 파악해 관광지 범위를 정교화하는 데에도 시그널 데이터가 활용됐다.
이종현 팀장은 "지방자치단체들은 지역 경제 활성화에 대한 고민을 갖고 있고, 이 때문에 관광 산업에 관심이 많다"며 "축제 등의 행사를 기획했을 때 이 행사가 얼마나 성공했는지를 확인하고 싶어했는데, 설문조사 등의 방법으로는 의미 있는 데이터가 도출되지 않던 상황이었다"고 설명했다.
KT는 자사가 수집한 유동인구 정보, 카드사 소비액, SNS 정보를 분석해 관광 정책과 비즈니스 전략을 수립하기 위한 빅데이터 분석을 지원하는 관광 분석 솔루션을 개발했다. 이를 통해 관광 수요 예측과 관광 상품 설계, 업무 제휴, 가격 설정 등이 용이해질 수 있다고 강조했다.
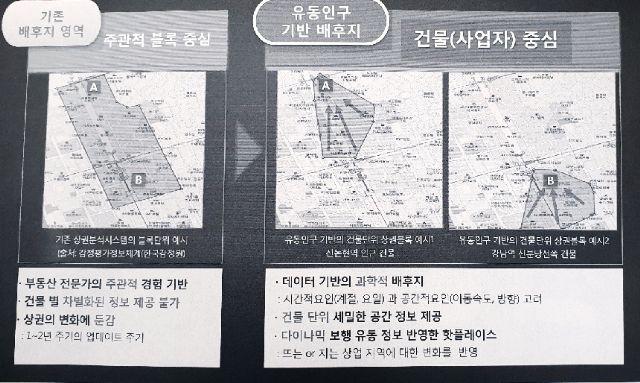
상권 분석에도 빅데이터를 활용했다. KT의 지도 앱 데이터와 BC카드 데이터를 통합해 마련한 사업체 정보와 건축물 대장 등을 토합해 만든 건물정보를 토대로 건물별로 입주한 사업체를 파악했다. 이는 유선 인터넷 1위 사업자라는 특성을 활용한 사례다. 사업체들이 사옥 이전을 할 때 유선 인터넷 주소 변경 신청도 함께 하기 때문에 정보 업데이트가 용이하다.
KT는 여기에 유동 인구 정보를 결합, 실제 유동인구가 특정 건물을 도보로 방문할 때 얼마나 멀리 떨어진 곳에서부터 이동하기 시작하는지를 분석해냈다.
이 팀장은 "5G가 본격적으로 상용화되면 비즈니스에 활용할 수 있는 데이터 분석을 많이 할 수 있게 될 것"이라며 "타사 데이터와의 융합도 더 시너지 있고 영향력 있는 분석 결과를 만들어낼 수 있는 방법"이라고 진단했다.
■"연합학습, 프라이버시 침해·데이터 왜곡 우려 덜 수 있는 분석 방법"
신수용 성균관대 교수는 "개인정보를 2차적으로 활용하기 위해 일일히 동의서를 받으면 가장 좋지만, 그게 쉽지 않다"며 "대안인 비식별 개인정보에 대한 사회적 합의가 마련되지 않아 이를 활용한 기관들이 고소를 당하는 실정"이라고 지적했다.
비식별화 조치가 취해진다는 점에서 기본적으로 데이터를 왜곡하는 것에 대한 한계도 있다. 이날 신 교수가 발표에서 다룬 의료 데이터의 경우 특히 그렇다. 신 교수는 "실제 혈압량을 그대로 기록하면 정보 주체 특정의 우려가 있고, 그렇다고 이를 정상, 고혈압 등의 방식으로 바꿔 표현하면 수집한 데이터를 활용하기가 마땅찮아진다"고 설명했다.
관련기사
- '개인정보 비식별 기술 세미나' 열린다2019.11.01
- KB국민은행-KB국민카드-GS리테일, 데이터 기반 시범사업 맞손2019.11.01
- 비식별 개인정보 활용 공방 계속…시민단체 재항고2019.11.01
- 검찰, 비식별 개인정보 활용 기업에 무혐의 처분2019.11.01

이런 문제를 해결할 방법론으로 신 교수는 연합학습을 주목했다. 데이터를 한 데 모을 필요 없이 분산된 상태에서 알고리즘이 학습할 모델을 각각 만들고, 이 모델들을 통합 서버에서 결합하는 방식이다. 데이터 원본을 분석에 활용하면서도 데이터 반출을 위한 복잡한 절차를 수반하지 않아도 되고, 분석 인력도 실제 데이터를 볼 수 없어 프라이버시 우려도 해소할 수 있다는 것.
신 교수는 "데이터 왜곡 없이 안전하게 분석할 수 있는 방법으로 동형 암호화도 존재하지만, 이는 연산량을 많이 요구하기 때문에 시간이 많이 소요되는 등 현재 기술적 한계가 있다"며 "직접 실험한 결과나 여러 논문 결과를 살펴봐도 연합학습은 원본 데이터들을 통합해 분석하는 것보다 정확도나 소요 시간 측면에서 성능이 크게 뒤지지 않는다"고 강조했다.





