






정부가 언어 번역, 사물·안면 인식 등 다방면에서 인공지능(AI) 학습용 데이터를 구축한다는 계획을 세웠다.
과학기술정보통신부는 9일 서울 양재에서 열린 AI 사업 통합 설명회를 통해 올해 AI 학습용 데이터 구축 과제 10가지를 발표했다.
이를 통해 ▲번역 ▲상황·동작 인지 ▲사물·위험요소 식별 ▲질병 진단 데이터 등 다방면에서 데이터셋을 구축할 계획이다.
데이터 구축 사업은 이르면 다음 주 공모가 시작된다. 이후 오는 7월 초 1차 공개를 거쳐 최종 완성된 데이터를 연말 공개한다. AI 데이터 확산 사업의 일환이다.
■상황 읽는 AI 개발 돕는다
정부는 복합 인지 능력을 갖춘 AI 개발을 지원하기 위해 '멀티 모달' 영상 데이터를 구축한다. 멀티 모달이란 AI가 다양한 모듈과 장치를 통해 상황을 인지하고, 대화도 이끌어 갈 수 있는 기능이다.

이를 위해 드라마나 예능 등 다양한 상황을 나타내는 약 3천분의 영상을 토대로 7가지 감정, 상황 외 성별이나 연령대 등 인물 분류와 10종 이상의 객체 및 장소 정보, 발화 내용 데이터를 수집한다.
동작, 행동 인지를 위한 영상 데이터도 모은다. 일상 생활에서 수행하는 동작을 AI가 인지하게 하고, 이를 통해 관련 인지 기술을 개발하게 하기 위한 것이다. 약 6250분 가량의 영상 데이터를 수집한다.
보행자 영상은 별도의 과제로 뒀다. 실외 보행 영역 인지 알고리즘 개발 지원이 목표다. 2~10명의 인도, 횡단보도 보행 정·측면 영상 300시간을 수집한다. 시간대와 날씨에 따라 달라지는 다양한 환경에서의 실외 보행 영상도 200시간 이상 구축한다.
■韓 언어·사물·안면 인식 데이터셋 구축
공개된 데이터 구축 과제 내용을 살펴보면 한국에 특화된 데이터셋 구축 내용이 다수 포함됐다.
언어 번역 분야에서는 번역 성능 강화를 위한 한국어-영어 문장 병렬 말 뭉치 100만~150만 문장을 구축한다. 한국어 문장에 정확히 대응하는 영어 문장을 한 세트로 묶는 식이다.
말 뭉치의 폭넓은 효용을 위해 잡지 10%, 기사 50%, 문학 작품 10%, IT·컴퓨터 관련 15%의 비중을 두고 문장을 추출한다.
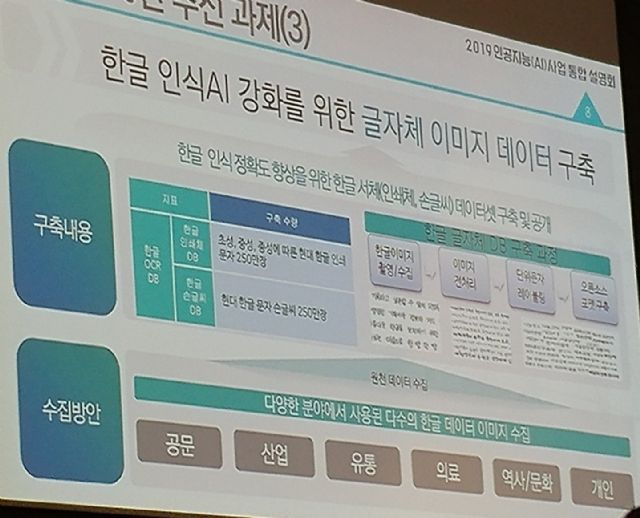
한글의 글자체 인식을 위한 이미지 데이터도 구축한다. 한글 인식 정확도 향상을 위해 초성, 중성, 종성에 따른 현대 한글 인쇄 문자 250만장과 현대 한글 문자 손글씨 250만장을 각각 한글 글자체 DB에 포함시킬 예정이다. 공문, 산업, 유통, 의료, 역사, 문화 등 다방면에서의 자료 수집이 이뤄지게 된다.
국내 거리에서 볼 수 있는 사물이나 건물, 간판이나 상징 관련 이미지를 수집하는 '한국형' 사물 이미지 데이터 구축도 추진하다. 상세 내용에 대해 1천 가지 이상의 분류도 거칠 예정이다. 건물이나 시설물, 거리와 간판, 교통 수단, 상품, 각종 표지판, 로고 등이 원천 데이터로 수집된다. 수집 규모는 총 360만장으로 잡았다.
AI의 한국인 식별 능력을 강화하기 위한 한국인 안면 이미지 데이터셋도 올해 구축 과제에 포함됐다. 영상 인식 서비스 개발에 활용할 수 있다는 설명이다. 각도와 조도, 표정과 해상도와 안경 등 부가 요소 등을 고려해 약 2천만장의 이미지 데이터셋을 구축한다.
■헬스케어·안전 특화 AI 역량 고도화 데이터 제공
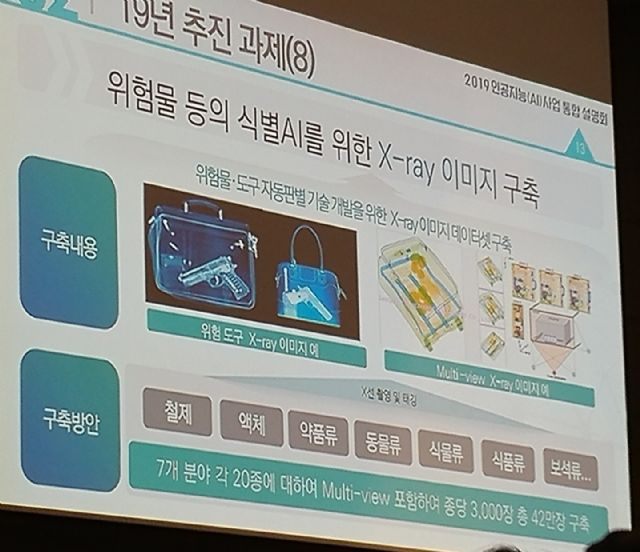
AI의 위험물 식별 능력을 키우기 위한 데이터셋 구축 과제도 제시했다. 엑스레이 등을 통해 가방 등에 총기류 등 위험물이 있는지 자동 판별할 수 있게 하기 위함이다.
철제, 액체, 약품류, 동·식물류, 식품류, 보석류 증 7개 분야 각 20종에 대해 다양한 시점에서 촬영한 이미지 42만장을 마련한다.
질병 진단 AI 기술 역량도 강화하기 위해 의료 이미지를 구축한다. 질환 진단 이미지 영상을 딥러닝 기계학습에 활용, 질환 진단에 기여할 수 있다는 것이다. 엑스레이, 초음파 영상 등 촬영 이미지와 질병 진단 정보를 결합한 데이터셋을 만들게 된다.
관련기사
- 정부 "현재 AI기술 뛰어넘는 신AI기술 개발 추진"2019.01.09
- K쇼핑 "말로 상품검색-주문-결제 다 된다"2019.01.09
- 셀트리온그룹, 4차 산업시대 맞춰 AI 원격진료 서비스 준비2019.01.09
- 자동차 수리비 견적도 이제 'AI'가 맡는다2019.01.09
CCTV 영상 데이터의 경우 개인 또는 군집의 이상 행동을 탐지하기 위해 수집된다. 주·야간별, 거리 수준별 다양한 영상 데이터를 구축한다. 침입, 실신, 다툼, 배회, 폭행, 무단 투기, 미행, 납치 등 이상행동과 정상 행동을 분류해 제공한다.
10종의 이상 행동에 대한 유형별 영상 각 15시간을 주, 야간으로 나눠 찍은 영상 총 300시간이 구축된다.





