






데이터 분석은 데이터웨어하우스(DW)에서 빅데이터로, 빅데이터에서 인공지능으로 진화하고 있다. 데이터 분석 아키텍처도 변했다. 분석 목적마다 개별로 만들었던 분석 시스템을 단일 데이터 플랫폼을 중심으로 통합하는 아키텍처가 널리 사용된다.
데이터 분석은 이제 비즈니스 의사결정의 핵심이다. 고객과 기업의 상호작용 방법이고, 미래까지 예측하는 수단이다. 한달에 한번 비즈니스 보고서를 만들던 배치형 분석으론 부족하다. 사물인터넷(IoT), 소셜 미디어 등에서 실시간으로 쏟아지는 데이터를 모아서 목적에 맞게 빠르게 분석하고, 빠르게 행동하려면 진보된 데이터 인프라를 확보해야 한다.
클라우드 컴퓨팅은 쉽고 빠르게 인프라를 확보하게 해준다. 이런 민첩성이 빅데이터, 인공지능 같은 새로운 분석 수요에 잘 맞는다. 클라우드 서비스 기업이 데이터 관련 서비스를 경쟁적으로 내놓은 건 그만큼 찾는 곳이 많다는 뜻이다.

양승도 아마존웹서비스(AWS)코리아 솔루션즈 아키텍트는 최근 기자간담회에서 “예측을 위한 분석 방법론에 DW를 사용하는 게 불가능하진 않지만, 분석과 예측에 적합한 값을 뽑아내기 매우 힘들다”며 “각 분석 방법론에 맞는 적당한 툴과 기술을 사용해야 한다”고 말했다.
그는 빅데이터 아키텍처의 기본 원칙 5가지를 제시했다. 각 단계별로 느슨하게 연결된 독립 시스템 구성, 작업에 적합한 툴 사용, AWS 관리형 서비스 활용, 참조 아키텍처와 디자인 패턴 적용, 비용 효율 고려 등이다.
양 아키텍트는 “데이터 수집,저장, 분석 등의 시스템을 느슨하게 독립시켜야 필요한 부분만 확장하는 게 가능하다”며 “AWS 관리형 서비스를 활용하면 기술을 적용하는 시간을 줄여 의미있는 데이터를 뽑아내는 것만 고민할 수 있게 된다”고 주장했다.
그는 “AWS가 12년간 클라우드 사업을 하며 다양한 고객사례에서 참조 아키텍처를 만들어 제공하고 있어 이를 참조해 유사한 사례에서 시작하는 게 좋다”며 “빅데이터가 비용 많이 드는 일이라 생각하는데 디자인 원칙을 조금만 고민하면 빅데이터 분석도 비용을 절약할 수 있다”고 덧붙였다.
데이터 아키텍처의 가장 기본 틀은 과거와 다르지 않다. ‘생성-수집 및 저장-분석 및 예측-협업 및 공유’로 전과 같다. 데이터 생성은 사실 어렵지 않다. IoT와 소셜 데이터로 많은 데이터가 쏟아지고 있다. 문제는 수집과 저장이다.
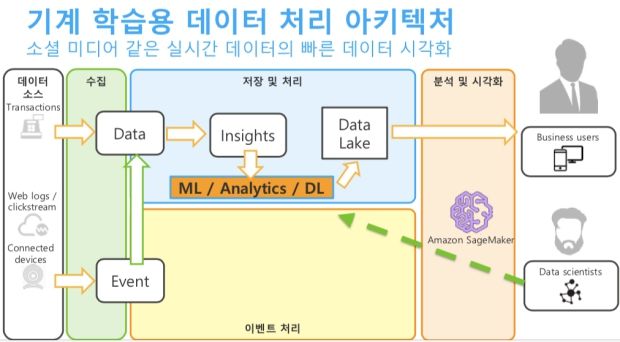
쏟아져 들어오는 데이터가 흐르는 튼튼한 파이프라인이 필요하다. 파이프라인은 적절한 곳에 저장해 나중에 분석하게 하거나(배치형 분석), 실시간으로 흐르는 데이터를 곧바로 활용하거나(스트리밍 분석), 머신러닝이나 딥러닝 알고리즘으로 인공지능을 구축하게 한다. 빠른 성능과, 확장성이 데이터 파이프라인의 기본이다.
데이터는 사용 목적에 따라 관계형 데이터베이스, DW, 하둡 등에 각기 쌓을 수 있다. 하지만, 저장할 때부터 목적에 따라 다르게 정리하면, 사용 목적이 바뀌었을 때 유연성이 떨어진다. 때문에 저장하는 곳을 하나로 통합해 거대한 저장소를 만드는 방안이 많이 쓰인다. 이른바 ‘데이터레이크’다.
데이터레이크는 저장할 때 사용자에 맞게 포맷을 달리해 저장하지 않는다. 사용자가 분석하려 할 때 그에 맞는 포맷으로 변환해 보여준다. 이렇게 되면 RDB든 하둡이든, 머신러닝이든 언제든 필요에 따라 데이터를 빠르게 활용할 수 있다.
양승도 아키텍트는 “일반적인 빅데이터는 수집해서 데이터레이크에 저장하고 아마존 아테나나 레드시프트로 분석과 시각화를 하게 한다”며 “실시간 처리를 한다면 데이터 스트림을 실시간 수집하는 아마존 키네시스 서비스를 써서 그때그때 이벤트를 처리하거나 데이터레이크에 쌓고, 나중에 아마존 엘라스틱서치로 분석할 수 있다”고 말했다.
관련기사
- AWS, 그래프DB '넵튠' 정식 서비스 시작2018.07.05
- 클릭 몇 번에 이더리움 네트워크 생성...AWS 템플릿 공개2018.07.05
- LS그룹, AWS 기반 제조 빅데이터 플랫폼 구축2018.07.05
- AWS코리아, 클라우드 서비스에 ISMS 인증 받았다2018.07.05

데이터레이크는AWS에서 S3와 글루(Glue)로 만들 수 있다. 99.999999999% 가용성을 보장하는 S3에 데이터를 쌓고, 데이터 카탈로그와 ETL을 글루로 처리해 다양한 분석 수요에 대응할 수 있다. 데이터는 얼마나 자주 활용하느냐에 따라 핫데이터, 웜데이터, 콜드데이터 등으로 구분해 계층화하고 그에 맞는 저장매체를 달리하면 비용을 줄일 수 있다. 인공지능을 쓰려면 머신러닝 모델을 제공하는 아마존 세이지메이커를 이용하면 된다.
양승도 아키텍트는 “이렇게 데이터레이크를 중심으로 플랫폼을 만들어놓으면, 데이터가 다양한 경로로 흐르면서 다양하게 활용될 수 있다”고 강조했다.





