






구글 인공지능(AI) 전문 자회사 딥마인드는 14일(현지시간) 2D 이미지를 보고 3D모델을 자동 생성할 수 있는 새로운 유형의 컴퓨터 비전 알고리즘 ‘GQN(Generative Query Network)’을 개발했다고 밝혔다.
GQN는 사람의 지시나 훈련 없이 여러 각도의 2D 이미지를 보고 난 후 3D모델을 렌더링할 수 있다. 예로 바닥에 빨간색 상자가 놓여있는 그림이 몇 장 제시되면 그림에 나와 있지 조명 등을 계산해 그림에 나와 있지 않은 빨간 상자 부분까지 렌더링해 3D모델을 만들어 낼 수 있다.
이 알고리즘은 사람의 뇌처럼 주변 환경과 물체 간 물리적 상호작용을 인지하는 것이 목표다. 사람이 받침대가 4개인 탁자를 봤을 때 당장 눈에는 받침대 3개만 보여도 눈에 보이지 않는 4번째 받침대가 있음을 추론하거나 그림자 방향을 보고 광원의 위치를 예상할 수 있는 것처럼 AI도 주변 환경을 인식할 수 있게 하는 것이다.
GQN는 시각 인지 시스템의 인식 훈련 과정의 번거로움을 줄일 수 있을 것으로 기대된다. 현재 대다수 시각 인지 시스템은 사람이 제작한 방대한 데이터 세트를 이용해 훈련된다. 데이터 세트의 각 장면들은 사람들이 작성한 주석이 달려있다. 이같은 데이터를 확보하려면 많은 비용과 시간이 들어간다.
GQN은 주변에서 접할 수 있는 데이터들로도 주변 환경을 인식할 수 있게 한다는 설명이다. GQN 연구 개발 내용은 국제 학술지 사이언스에도 게재됐다.
딥마인드 측은 “GQN은 어린 아이나 동물처럼 사람이 작성한 주석 없이도 주변 장면과 기하학적 특성을 인식하며 주변 환경 이해하는 훈련을 한다”고 자사 블로그에서 설명했다.
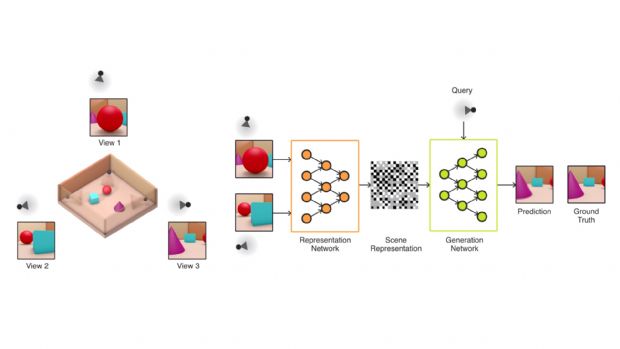
GQN은 표현 네트워크(representation network)와 생성 네트워크(generation network) 두 부분으로 구성된다. 표현 네트워크는 입력 데이터를 기본 장면을 설명하는 수학적 표현, 즉 벡터로 변환한다. 생성 네트워크는 시각 시스템이 보지 못한 관점에서 장면을 예측해 이미지화한다.
표현 네트워크는 생성 네트워크가 예측할 수 있는 관점의 장면을 알 수 없기 때문에 관찰한 장면의 실제 레이아웃을 가능한 정확하게 표현하는 방법을 찾게 된다. 객체 위치, 색상, 공간 레이아웃 등 가장 중요한 요소들을 캡처하는 것이다.
생성 네트워크는 장면 표현과 새로운 카메라 관점이 제공되면 원근법, 교합, 조명 등이 사전에 지정되지 않아도 선명한 이미지를 생성한다.
딥마인드는 GQN 고도화는 필요하지만 이번 기술 개발이 완전히 자율적인 장면 이해를 가능케 하는 단계 중 하나라고 자신했다.
관련기사
- 구글, 딥마인드 AI기술 상용화 속도2018.06.15
- 구글 딥마인드, AI로 급성신부전증 예측한다2018.06.15
- '알파고 제로' 또 진화...체스·장기도 정복2018.06.15
- 딥마인드 음성변조 AI 기술, 성별까지 바꿔2018.06.15
딥마인드 측은 “이번 기술은 전통적인 컴퓨터 비전 기술과 비교해 여전히 많은 제한을 가지고 있다. 현재 합성 장면으로만 훈련이 이뤄졌다”면서도 “새로운 데이터 소스가 제공되고 하드웨어 기능이 향상된다면 실제 장면의 고해상도 이미지에 GQN 프레임 워크 적용을 조사할 수 있을 것”이라고 전했다.
이어 “향후 연구에선 GQN 적용을 장면 인지 보다 폭 넓은 측면에서 연구할 수 있을 것”이라며 “예를 들어 공간과 시간을 가로지르는 물리와 운동에 대한 상식적 개념과 가상현실, 증강현실에서 애플리케이션을 학습하는 데도 도움이 될 수 있다”고 덧붙였다.





