오픈AI가 계산생물학용 AI 평가 기준 진벤치-프로(GeneBench-Pro)를 공개했다. 6월 30일 발표된 이 벤치마크는 기존 진벤치를 더 어렵고 현실적인 문제로 확장했다. 유전체학, 정량생물학, 중개의학에 걸친 129개 합성 문제로 구성됐다. 진벤치는 연구자들이 새로운 생물학을 연구하는 데 쓰인다.
각 문제는 현실적이면서 일부러 잡음을 섞은 데이터셋과, 실제 의사결정으로 이어지는 추정 목표를 함께 제시한다. 모든 문제가 알려진 인과 구조에서 생성돼 정답을 기계적으로 채점할 수 있다. 채점 기준이 흔들려 정확도가 떨어지는 다른 장기 과제형 벤치마크의 약점을 피했다.
오픈AI가 측정하려는 능력은 연구 감각이다. 데이터가 실제로 뒷받침할 수 있는 질문이 무엇인지, 초기 경고 신호에 따라 모델을 어떻게 바꿔야 하는지, 처음 세운 계획을 언제 버려야 하는지 같은 연쇄 판단을 돕는다.
최고 반응 수준에서 GPT-5.6 Sol Pro가 정답률 31.5%, GPT-5.6 Sol이 28.7%를 기록했다. 언뜻 보면 낮은 수치 같지만 GPT 계열 외 가장 강한 모델인 클로드 오퍼스 4.8은 16.0%에 그쳤다. 최고 모델도 실제 생물학 문제의 약 70%를 틀리고 있다.
이 점수는 현재 AI가 실험 데이터를 다루는 실제 연구에서 아직 사람 연구자를 대체하기 어렵다는 뜻이다. 오픈AI는 대표 문항을 공개해 후속 연구가 같은 기준으로 성능을 비교하도록 했다.
▶︎ 관련기사:
오픈AI, 생명과학 특화 AI 모델 'GPT-로잘린드' 출시…신약 개발·유전체 연구 가속화
자세한 내용은 오픈AI에서 확인할 수 있다.
이미지 출처: 이디오그램 생성
관련기사
- 구글 제미나이 '나노 바나나' 개인화 이미지 생성, 미국서 무료 개방2026.07.02
- 삼성전자, tvN '내일도 출근!' 제작 지원…AI 가전 글로벌 접점 넓힌다2026.07.01
- 대만, 슈퍼마이크로 AI 서버 '중국 밀반출' 의혹 수사 착수2026.07.01
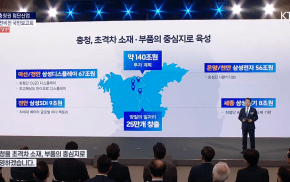
- 삼성, 충청에 140조원 투자…반도체·디스플레이·배터리 강화2026.07.02
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)