






구글이 기존보다 4배 빠른 텍스트 생성 속도를 갖춘 '젬마' 버전을 내놨다.
구글딥마인드는 10일(현지시간) 텍스트 디퓨전 방식을 적용한 오픈소스 실험 모델 '디퓨전젬마(DiffusionGemma)'를 출시했다고 공식 블로그에 밝혔다. 이 모델은 '아파치 2.0 라이선스'로 배포되며 전체 260억개 파라미터 규모전문가혼합(MoE) 구조를 기반으로 이뤄졌다.
디퓨전젬마의 핵심은 기존 거대언어모델(LLM)처럼 토큰을 한 개씩 순차 생성하지 않는다는 점이다. 256개 토큰 블록을 한 번에 생성한 뒤, 여러 차례 수정과 보완을 거쳐 최종 결과를 만드는 텍스트 디퓨전 방식으로 작동한다. 이를 통해 그래픽처리장치(GPU)에서 최대 4배 빠른 텍스트 생성 속도를 구현했다.
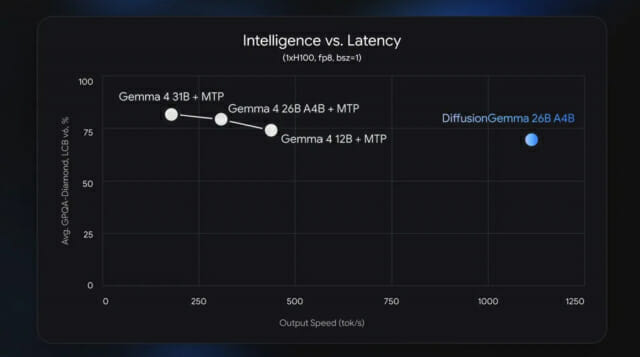
구글딥마인드는 "이 모델은 단일 엔비디아 'H100'에서는 초당 1000개 이상 토큰을 생성한다"며 "엔비디아 '지포스 RTX 5090'에서는 초당 700개 이상 토큰을 처리할 수 있다"고 밝혔다.
해당 모델은 전체 260억개 파라미터를 갖고 있지만 실제 추론 과정에서는 38억개 파라미터만 활성화한다. 양자화 기준으로 18기가바이트(GB) 비디오램(VRAM) 환경에서도 구동할 수 있어 고급 소비자용 GPU에서도 활용 가능한 셈이다.
또 모든 토큰이 서로를 참조하는 양방향 어텐션 구조를 적용했다. 인라인 편집과 코드 인필링, 아미노산 서열 생성, 수학 그래프 생성 등 비선형 작업에 강한 것으로 알려졌다.
디퓨전젬마는 생성 과정에서 전체 텍스트를 한 번에 검토하며 오류를 수정하는 자기 정제 기능도 갖췄다. 복잡한 마크다운 형식을 정확하게 마무리하거나 코드 생성과 렌더링을 거의 실시간으로 수행할 수 있는 셈이다.

구글딥마인드는 디퓨전젬마를 연구·실험 목적용이라고 당부했다. 속도와 병렬 생성에 초점을 맞춘 만큼 전체 출력 품질은 기존 자기회귀 기반 젬마4 모델보다 낮다고 설명했다.
관련기사
- 네이버는 엔비디아·AMD, 카카오는 구글·오픈AI...두 기업의 같은 길, 다른 동맹2026.06.09
- '구글 이탈' 맞선 역발상…브로드컴이 '종합 플랫폼' 택한 이유2026.06.09
- 구글, 기업용 AI 정확도 34% 높인 '에이전틱 RAG' 공개2026.06.09
- 애플, 구글과 함께 새 AI 아키텍처 공개…'적과의 동침' 통할까2026.06.09
또 디퓨전젬마 성능 이점으로 로컬 또는 낮은 동시성 환경에서 가장 크게 나타난다고 밝혔다. 대규모 클라우드 서비스 환경에서는 자기회귀 모델도 높은 연산 활용률을 확보할 수 있어 속도 우위가 줄어들 수 있다고 덧붙였다.
구글딥마인드는 "이번 모델은 속도가 중요한 인터랙티브 로컬 워크플로를 탐색하는 연구자와 개발자를 위해 설계됐다"고 밝혔다.





