구글이 이미지·음성 같은 멀티모달 작업을 노트북에서 처리할 수 있는 경량 인공지능(AI) 모델을 내놨다.
구글은 3일(현지시간) 최신 모델 '젬마 4 12B'를 공식 홈페이지를 통해 공개했다. 이 모델은 엣지 친화형 모델과 고성능 전문가 혼합 모델 사이 간극을 메우기 위해 설계됐다.
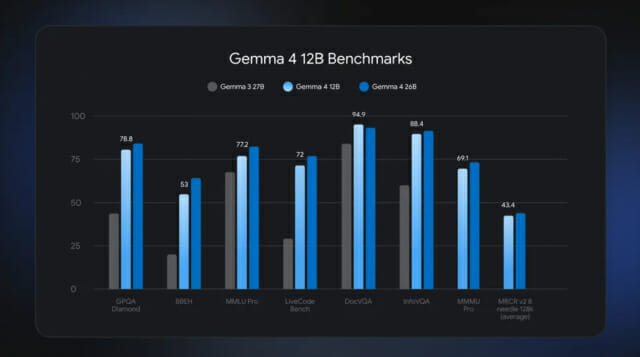
젬마 4 12B는 표준 벤치마크에서 전문가 혼합 모델에 가까운 성능을 낸 것으로 나타났다. 메모리 사용량을 절반 이하로 줄여 16GB급 그래픽메모리(VRAM)나 통합 메모리를 갖춘 일반 노트북에서도 기기 안에서 실행할 수 있도록 했다.

해당 모델은 다단계 추론과 에이전틱 워크플로도 지원한다. 구글은 이를 통해 사용자가 자신의 기기에서 강력한 멀티모달과 에이전틱 경험을 구현할 수 있다고 강조했다.
구글은 젬마 4 12B가 기존 멀티모달 AI의 복잡한 처리 과정을 줄였다고 설명했다. 기존 모델은 이미지나 음성을 먼저 별도 인코더로 해석한 뒤 언어 모델에 넘겼지만, 젬마 4 12B는 이 중간 단계를 생략한 구조로 이뤄져서다.
이미지 처리 방식도 단순화했다. 기존처럼 무거운 비전 인코더가 이미지를 따로 분석하는 대신 가벼운 변환 장치만 거쳐 언어 모델 본체가 시각 정보를 직접 처리하도록 했다.
음성 처리 방식은 더 간단하다. 구글은 별도 오디오 인코더를 없애고, 음성 신호를 언어 모델이 다룰 수 있는 형태로 바로 바꿔 입력하도록 설계했다고 설명했다.
젬마 4 12B는 아파치 2.0 라이선스로 공개됐다. 개발자 생태계 전반의 지원을 받을 수 있도록 했으며 지연 시간을 줄이기 위한 멀티토큰 예측 드래프터도 탑재했다.
관련기사
- 구글 AI 검색 반발에 덕덕고 설치 30% 급증… '강제 AI' 거부 확산2026.05.28
- 해커 표적 된 오픈소스 개발자…크라우드스트라이크·구글, 봇넷 폐쇄2026.05.28
- 구글 AI 검색, 웹 경제도 바꾼다…‘제로클릭’ 시대, 퍼블리셔 트래픽은 어디로2026.05.26
- 제미나이 과금 논란 속 구글 "AI 보안 전략 처음부터 짜야"2026.05.25
구글은 젬마 4 모델이 개발자 커뮤니티를 통해 1억 5000만 다운로드를 넘어섰다고 밝혔다.
구글은 "젬마 4 12B는 모바일 우선의 효율성과 고도화된 추론 능력을 결합해 고성능 멀티모달 지능을 노트북에서 직접 구현할 수 있도록 설계됐다"며 "속도나 추론 능력을 줄이지 않으면서도 일상적인 하드웨어에 고도화된 멀티모달 기능을 제공한다"고 밝혔다.